 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Topic-Doesn't-Fit-All: Transcreating Reading Comprehension Test for Personalized Learning
Nov 12, 2025


Personalized learning has gained attention in English as a Foreign Language (EFL) education, where engagement and motivation play crucial roles in reading comprehension. We propose a novel approach to generating personalized English reading comprehension tests tailored to students' interests. We develop a structured content transcreation pipeline using OpenAI's gpt-4o, where we start with the RACE-C dataset, and generate new passages and multiple-choice reading comprehension questions that are linguistically similar to the original passages but semantically aligned with individual learners' interests. Our methodology integrates topic extraction, question classification based on Bloom's taxonomy, linguistic feature analysis, and content transcreation to enhance student engagement. We conduct a controlled experiment with EFL learners in South Korea to examine the impact of interest-aligned reading materials on comprehension and motivation. Our results show students learning with personalized reading passages demonstrate improved comprehension and motivation retention compared to those learning with non-personalized materials.
Integrating LLM-Generated Views into Mean-Variance Optimization Using the Black-Litterman Model
Apr 19, 2025
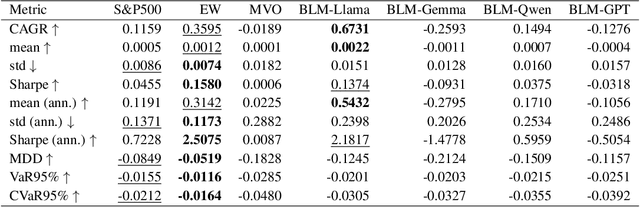
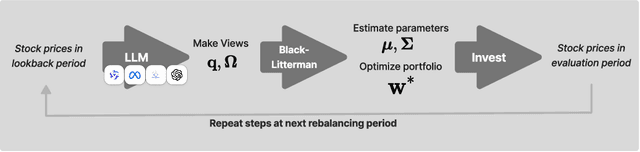
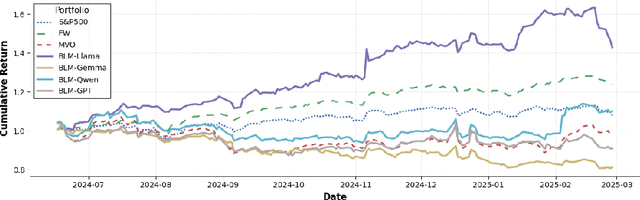
Portfolio optimization faces challenges due to the sensitivity in traditional mean-variance models. The Black-Litterman model mitigates this by integrating investor views, but defining these views remains difficult. This study explores the integration of large language models (LLMs) generated views into portfolio optimization using the Black-Litterman framework. Our method leverages LLMs to estimate expected stock returns from historical prices and company metadata, incorporating uncertainty through the variance in predictions. We conduct a backtest of the LLM-optimized portfolios from June 2024 to February 2025, rebalancing biweekly using the previous two weeks of price data. As baselines, we compare against the S&P 500, an equal-weighted portfolio, and a traditional mean-variance optimized portfolio constructed using the same set of stocks. Empirical results suggest that different LLMs exhibit varying levels of predictive optimism and confidence stability, which impact portfolio performance. The source code and data are available at https://github.com/youngandbin/LLM-MVO-BLM.
Understanding Editing Behaviors in Multilingual Wikipedia
Aug 28, 2015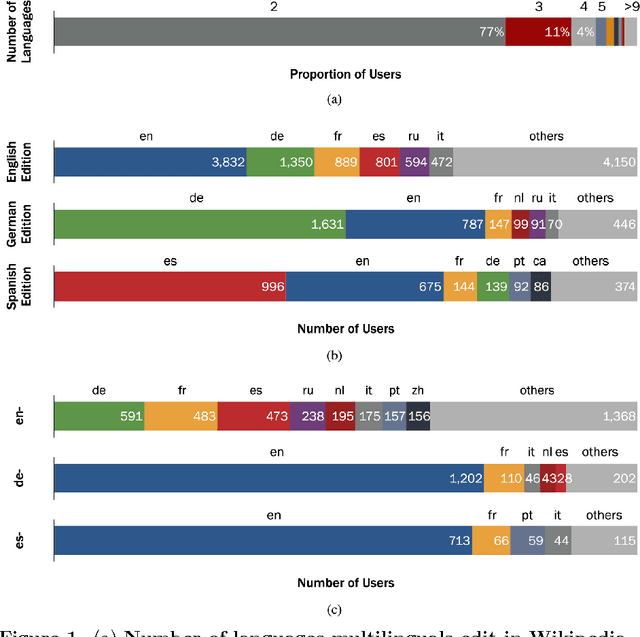

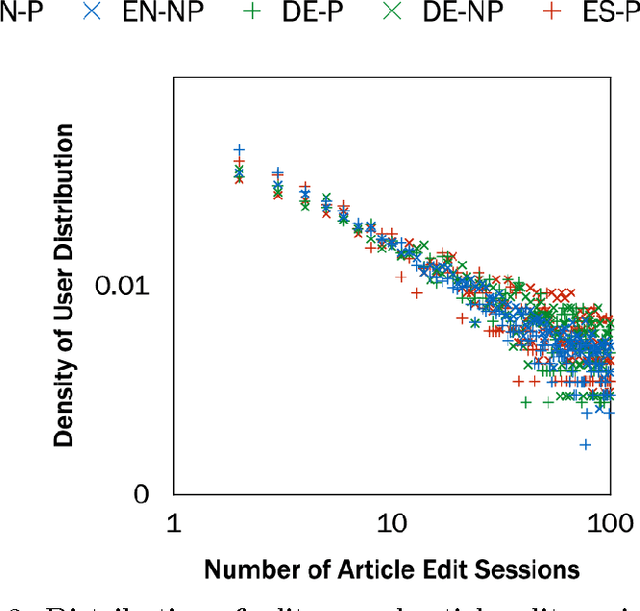

Multilingualism is common offline, but we have a more limited understanding of the ways multilingualism is displayed online and the roles that multilinguals play in the spread of content between speakers of different languages. We take a computational approach to studying multilingualism using one of the largest user-generated content platforms, Wikipedia. We study multilingualism by collecting and analyzing a large dataset of the content written by multilingual editors of the English, German, and Spanish editions of Wikipedia. This dataset contains over two million paragraphs edited by over 15,000 multilingual users from July 8 to August 9, 2013. We analyze these multilingual editors in terms of their engagement, interests, and language proficiency in their primary and non-primary (secondary) languages and find that the English edition of Wikipedia displays different dynamics from the Spanish and German editions. Users primarily editing the Spanish and German editions make more complex edits than users who edit these editions as a second language. In contrast, users editing the English edition as a second language make edits that are just as complex as the edits by users who primarily edit the English edition. In this way, English serves a special role bringing together content written by multilinguals from many language editions. Nonetheless, language remains a formidable hurdle to the spread of content: we find evidence for a complexity barrier whereby editors are less likely to edit complex content in a second language. In addition, we find that multilinguals are less engaged and show lower levels of language proficiency in their second languages. We also examine the topical interests of multilingual editors and find that there is no significant difference between primary and non-primary editors in each language.
Dirichlet Process with Mixed Random Measures: A Nonparametric Topic Model for Labeled Data
Jun 18, 2012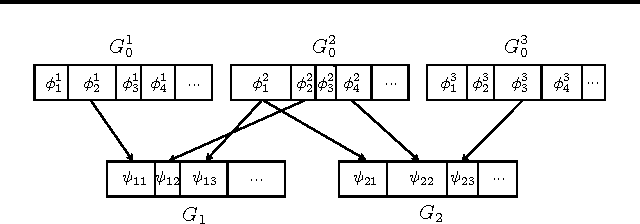
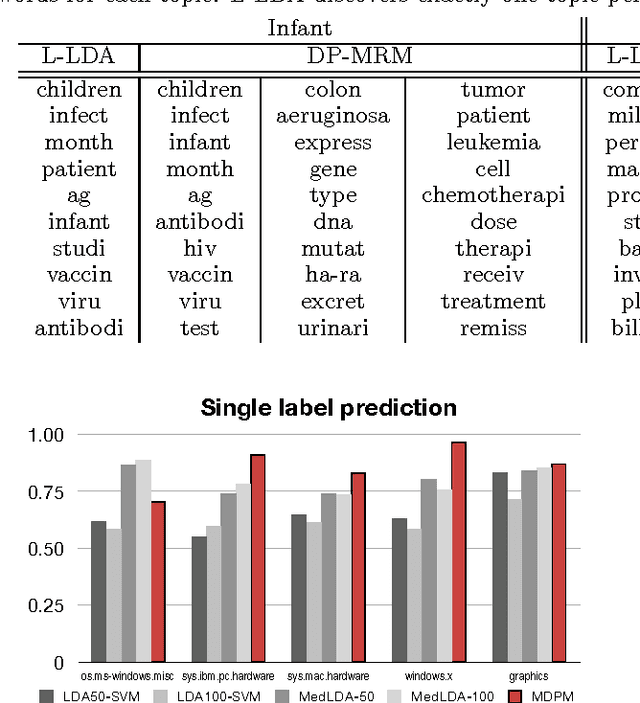

We describe a nonparametric topic model for labeled data. The model uses a mixture of random measures (MRM) as a base distribution of the Dirichlet process (DP) of the HDP framework, so we call it the DP-MRM. To model labeled data, we define a DP distributed random measure for each label, and the resulting model generates an unbounded number of topics for each label. We apply DP-MRM on single-labeled and multi-labeled corpora of documents and compare the performance on label prediction with MedLDA, LDA-SVM, and Labeled-LDA. We further enhance the model by incorporating ddCRP and modeling multi-labeled images for image segmentation and object labeling, comparing the performance with nCuts and rddCRP.