 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMacro2Micro: Cross-modal Magnetic Resonance Imaging Synthesis Leveraging Multi-scale Brain Structures
Dec 15, 2024



Spanning multiple scales-from macroscopic anatomy down to intricate microscopic architecture-the human brain exemplifies a complex system that demands integrated approaches to fully understand its complexity. Yet, mapping nonlinear relationships between these scales remains challenging due to technical limitations and the high cost of multimodal Magnetic Resonance Imaging (MRI) acquisition. Here, we introduce Macro2Micro, a deep learning framework that predicts brain microstructure from macrostructure using a Generative Adversarial Network (GAN). Grounded in the scale-free, self-similar nature of brain organization-where microscale information can be inferred from macroscale patterns-Macro2Micro explicitly encodes multiscale brain representations into distinct processing branches. To further enhance image fidelity and suppress artifacts, we propose a simple yet effective auxiliary discriminator and learning objective. Our results show that Macro2Micro faithfully translates T1-weighted MRIs into corresponding Fractional Anisotropy (FA) images, achieving a 6.8% improvement in the Structural Similarity Index Measure (SSIM) compared to previous methods, while preserving the individual neurobiological characteristics.
A Training-Free Approach for Music Style Transfer with Latent Diffusion Models
Nov 24, 2024



Music style transfer, while offering exciting possibilities for personalized music generation, often requires extensive training or detailed textual descriptions. This paper introduces a novel training-free approach leveraging pre-trained Latent Diffusion Models (LDMs). By manipulating the self-attention features of the LDM, we effectively transfer the style of reference music onto content music without additional training. Our method achieves superior style transfer and melody preservation compared to existing methods. This work opens new creative avenues for personalized music generation.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
AesFA: An Aesthetic Feature-Aware Arbitrary Neural Style Transfer
Dec 10, 2023



Neural style transfer (NST) has evolved significantly in recent years. Yet, despite its rapid progress and advancement, existing NST methods either struggle to transfer aesthetic information from a style effectively or suffer from high computational costs and inefficiencies in feature disentanglement due to using pre-trained models. This work proposes a lightweight but effective model, AesFA -- Aesthetic Feature-Aware NST. The primary idea is to decompose the image via its frequencies to better disentangle aesthetic styles from the reference image while training the entire model in an end-to-end manner to exclude pre-trained models at inference completely. To improve the network's ability to extract more distinct representations and further enhance the stylization quality, this work introduces a new aesthetic feature: contrastive loss. Extensive experiments and ablations show the approach not only outperforms recent NST methods in terms of stylization quality, but it also achieves faster inference. Codes are available at https://github.com/Sooyyoungg/AesFA.
Energy-Efficient Downlink Semantic Generative Communication with Text-to-Image Generators
Jun 08, 2023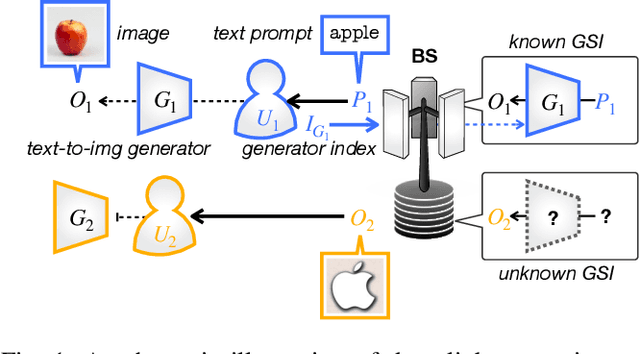

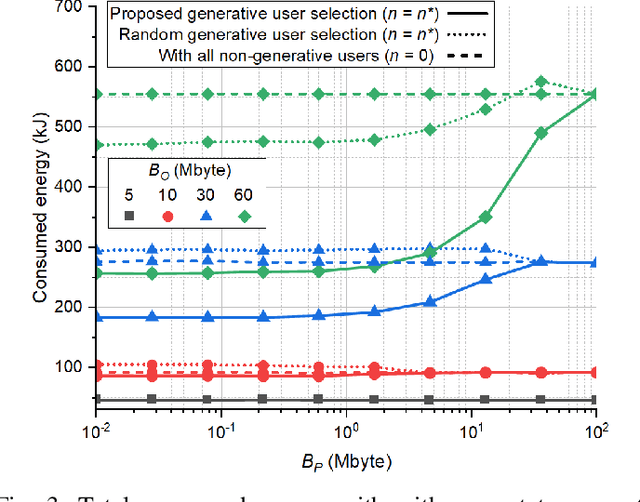
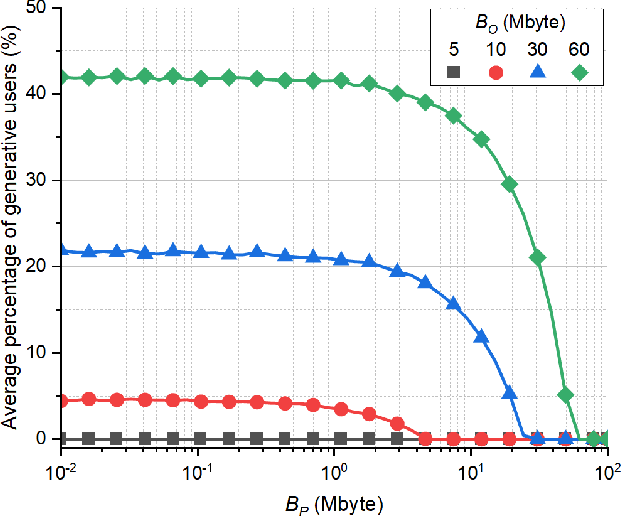
In this paper, we introduce a novel semantic generative communication (SGC) framework, where generative users leverage text-to-image (T2I) generators to create images locally from downloaded text prompts, while non-generative users directly download images from a base station (BS). Although generative users help reduce downlink transmission energy at the BS, they consume additional energy for image generation and for uploading their generator state information (GSI). We formulate the problem of minimizing the total energy consumption of the BS and the users, and devise a generative user selection algorithm. Simulation results corroborate that our proposed algorithm reduces total energy by up to 54% compared to a baseline with all non-generative users.
Understanding Editing Behaviors in Multilingual Wikipedia
Aug 28, 2015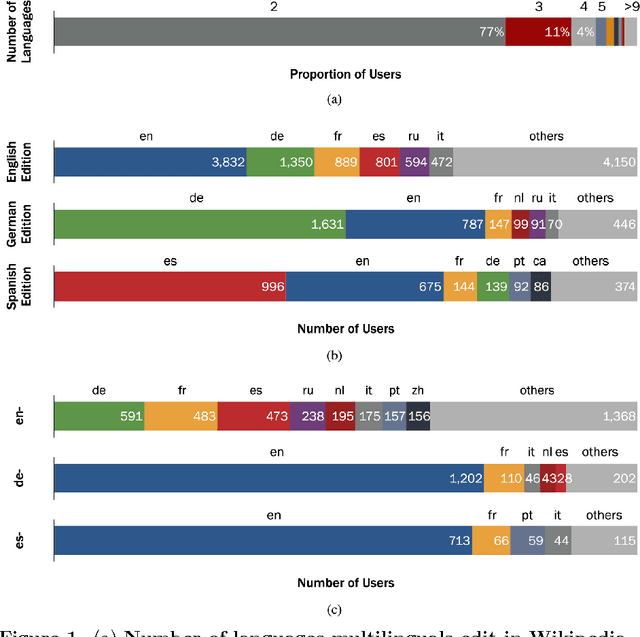

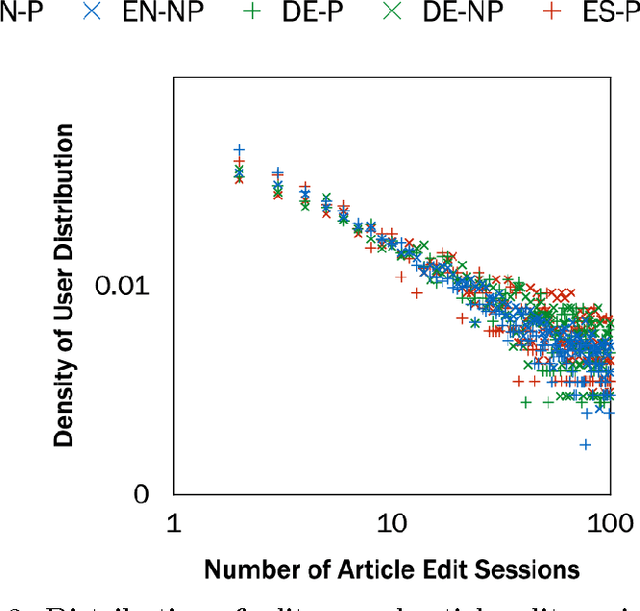

Multilingualism is common offline, but we have a more limited understanding of the ways multilingualism is displayed online and the roles that multilinguals play in the spread of content between speakers of different languages. We take a computational approach to studying multilingualism using one of the largest user-generated content platforms, Wikipedia. We study multilingualism by collecting and analyzing a large dataset of the content written by multilingual editors of the English, German, and Spanish editions of Wikipedia. This dataset contains over two million paragraphs edited by over 15,000 multilingual users from July 8 to August 9, 2013. We analyze these multilingual editors in terms of their engagement, interests, and language proficiency in their primary and non-primary (secondary) languages and find that the English edition of Wikipedia displays different dynamics from the Spanish and German editions. Users primarily editing the Spanish and German editions make more complex edits than users who edit these editions as a second language. In contrast, users editing the English edition as a second language make edits that are just as complex as the edits by users who primarily edit the English edition. In this way, English serves a special role bringing together content written by multilinguals from many language editions. Nonetheless, language remains a formidable hurdle to the spread of content: we find evidence for a complexity barrier whereby editors are less likely to edit complex content in a second language. In addition, we find that multilinguals are less engaged and show lower levels of language proficiency in their second languages. We also examine the topical interests of multilingual editors and find that there is no significant difference between primary and non-primary editors in each language.