 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing RAG Techniques for Automotive Industry PDF Chatbots: A Case Study with Locally Deployed Ollama Models
Paper and Code
Aug 12, 2024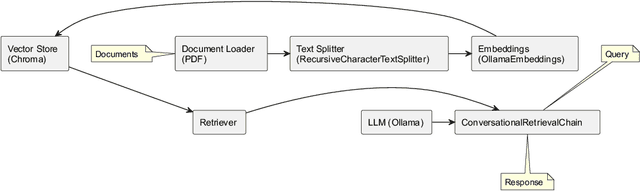
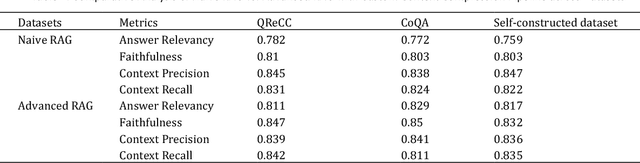
With the growing demand for offline PDF chatbots in automotive industrial production environments, optimizing the deployment of large language models (LLMs) in local, low-performance settings has become increasingly important. This study focuses on enhancing Retrieval-Augmented Generation (RAG) techniques for processing complex automotive industry documents using locally deployed Ollama models. Based on the Langchain framework, we propose a multi-dimensional optimization approach for Ollama's local RAG implementation. Our method addresses key challenges in automotive document processing, including multi-column layouts and technical specifications. We introduce improvements in PDF processing, retrieval mechanisms, and context compression, tailored to the unique characteristics of automotive industry documents. Additionally, we design custom classes supporting embedding pipelines and an agent supporting self-RAG based on LangGraph best practices. To evaluate our approach, we constructed a proprietary dataset comprising typical automotive industry documents, including technical reports and corporate regulations. We compared our optimized RAG model and self-RAG agent against a naive RAG baseline across three datasets: our automotive industry dataset, QReCC, and CoQA. Results demonstrate significant improvements in context precision, context recall, answer relevancy, and faithfulness, with particularly notable performance on the automotive industry dataset. Our optimization scheme provides an effective solution for deploying local RAG systems in the automotive sector, addressing the specific needs of PDF chatbots in industrial production environments. This research has important implications for advancing information processing and intelligent production in the automotive industry.