 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVVLoc: Prior-free 3-DoF Vehicle Visual Localization
Jan 31, 2026Localization is a critical technology in autonomous driving, encompassing both topological localization, which identifies the most similar map keyframe to the current observation, and metric localization, which provides precise spatial coordinates. Conventional methods typically address these tasks independently, rely on single-camera setups, and often require additional 3D semantic or pose priors, while lacking mechanisms to quantify the confidence of localization results, making them less feasible for real industrial applications. In this paper, we propose VVLoc, a unified pipeline that employs a single neural network to concurrently achieve topological and metric vehicle localization using multi-camera system. VVLoc first evaluates the geo-proximity between visual observations, then estimates their relative metric poses using a matching strategy, while also providing a confidence measure. Additionally, the training process for VVLoc is highly efficient, requiring only pairs of visual data and corresponding ground-truth poses, eliminating the need for complex supplementary data. We evaluate VVLoc not only on the publicly available datasets, but also on a more challenging self-collected dataset, demonstrating its ability to deliver state-of-the-art localization accuracy across a wide range of localization tasks.
Causal invariant geographic network representations with feature and structural distribution shifts
Mar 25, 2025The existing methods learn geographic network representations through deep graph neural networks (GNNs) based on the i.i.d. assumption. However, the spatial heterogeneity and temporal dynamics of geographic data make the out-of-distribution (OOD) generalisation problem particularly salient. The latter are particularly sensitive to distribution shifts (feature and structural shifts) between testing and training data and are the main causes of the OOD generalisation problem. Spurious correlations are present between invariant and background representations due to selection biases and environmental effects, resulting in the model extremes being more likely to learn background representations. The existing approaches focus on background representation changes that are determined by shifts in the feature distributions of nodes in the training and test data while ignoring changes in the proportional distributions of heterogeneous and homogeneous neighbour nodes, which we refer to as structural distribution shifts. We propose a feature-structure mixed invariant representation learning (FSM-IRL) model that accounts for both feature distribution shifts and structural distribution shifts. To address structural distribution shifts, we introduce a sampling method based on causal attention, encouraging the model to identify nodes possessing strong causal relationships with labels or nodes that are more similar to the target node. Inspired by the Hilbert-Schmidt independence criterion, we implement a reweighting strategy to maximise the orthogonality of the node representations, thereby mitigating the spurious correlations among the node representations and suppressing the learning of background representations. Our experiments demonstrate that FSM-IRL exhibits strong learning capabilities on both geographic and social network datasets in OOD scenarios.
* 15 pages, 3 figures, 8 tables
NDT-Map-Code: A 3D global descriptor for real-time loop closure detection in lidar SLAM
Jul 17, 2023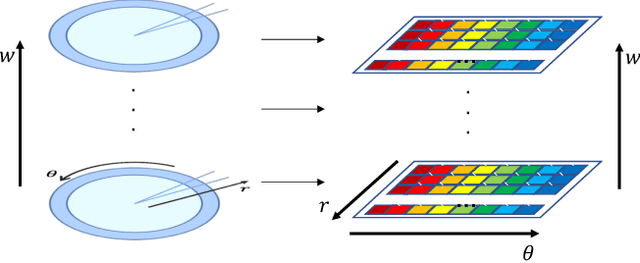


Loop-closure detection, also known as place recognition, aiming to identify previously visited locations, is an essential component of a SLAM system. Existing research on lidar-based loop closure heavily relies on dense point cloud and 360 FOV lidars. This paper proposes an out-of-the-box NDT (Normal Distribution Transform) based global descriptor, NDT-Map-Code, designed for both on-road driving and underground valet parking scenarios. NDT-Map-Code can be directly extracted from the NDT map without the need for a dense point cloud, resulting in excellent scalability and low maintenance cost. The NDT representation is leveraged to identify representative patterns, which are further encoded according to their spatial location (bearing, range, and height). Experimental results on the NIO underground parking lot dataset and the KITTI dataset demonstrate that our method achieves significantly better performance compared to the state-of-the-art.