 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Generalization: The Impact of Annotation Style on Medical Image Segmentation
Oct 31, 2022Generalization is an important attribute of machine learning models, particularly for those that are to be deployed in a medical context, where unreliable predictions can have real world consequences. While the failure of models to generalize across datasets is typically attributed to a mismatch in the data distributions, performance gaps are often a consequence of biases in the ``ground-truth" label annotations. This is particularly important in the context of medical image segmentation of pathological structures (e.g. lesions), where the annotation process is much more subjective, and affected by a number underlying factors, including the annotation protocol, rater education/experience, and clinical aims, among others. In this paper, we show that modeling annotation biases, rather than ignoring them, poses a promising way of accounting for differences in annotation style across datasets. To this end, we propose a generalized conditioning framework to (1) learn and account for different annotation styles across multiple datasets using a single model, (2) identify similar annotation styles across different datasets in order to permit their effective aggregation, and (3) fine-tune a fully trained model to a new annotation style with just a few samples. Next, we present an image-conditioning approach to model annotation styles that correlate with specific image features, potentially enabling detection biases to be more easily identified.
Cohort Bias Adaptation in Aggregated Datasets for Lesion Segmentation
Aug 02, 2021
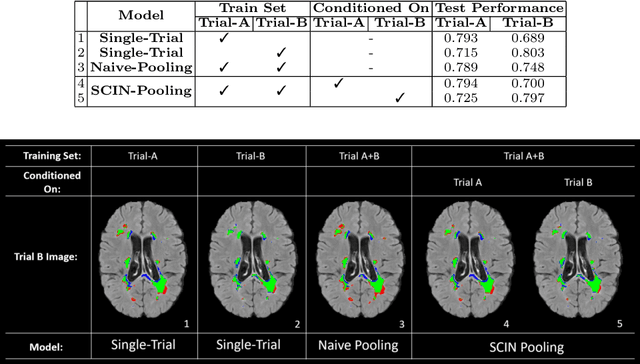
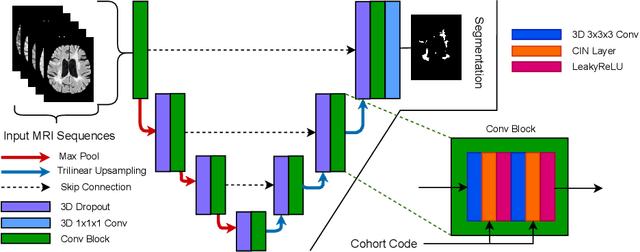

Many automatic machine learning models developed for focal pathology (e.g. lesions, tumours) detection and segmentation perform well, but do not generalize as well to new patient cohorts, impeding their widespread adoption into real clinical contexts. One strategy to create a more diverse, generalizable training set is to naively pool datasets from different cohorts. Surprisingly, training on this \it{big data} does not necessarily increase, and may even reduce, overall performance and model generalizability, due to the existence of cohort biases that affect label distributions. In this paper, we propose a generalized affine conditioning framework to learn and account for cohort biases across multi-source datasets, which we call Source-Conditioned Instance Normalization (SCIN). Through extensive experimentation on three different, large scale, multi-scanner, multi-centre Multiple Sclerosis (MS) clinical trial MRI datasets, we show that our cohort bias adaptation method (1) improves performance of the network on pooled datasets relative to naively pooling datasets and (2) can quickly adapt to a new cohort by fine-tuning the instance normalization parameters, thus learning the new cohort bias with only 10 labelled samples.