 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCohort Bias Adaptation in Aggregated Datasets for Lesion Segmentation
Paper and Code
Aug 02, 2021
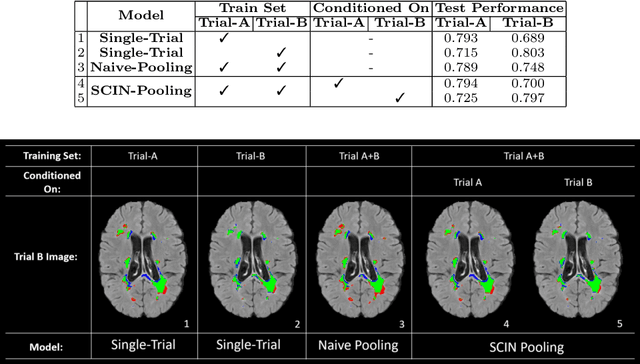
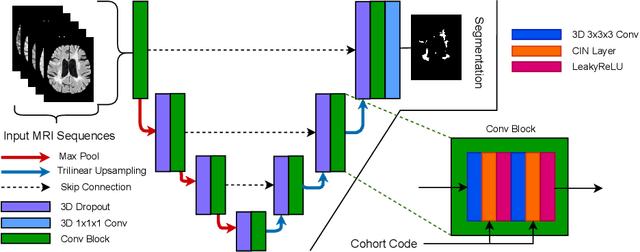

Many automatic machine learning models developed for focal pathology (e.g. lesions, tumours) detection and segmentation perform well, but do not generalize as well to new patient cohorts, impeding their widespread adoption into real clinical contexts. One strategy to create a more diverse, generalizable training set is to naively pool datasets from different cohorts. Surprisingly, training on this \it{big data} does not necessarily increase, and may even reduce, overall performance and model generalizability, due to the existence of cohort biases that affect label distributions. In this paper, we propose a generalized affine conditioning framework to learn and account for cohort biases across multi-source datasets, which we call Source-Conditioned Instance Normalization (SCIN). Through extensive experimentation on three different, large scale, multi-scanner, multi-centre Multiple Sclerosis (MS) clinical trial MRI datasets, we show that our cohort bias adaptation method (1) improves performance of the network on pooled datasets relative to naively pooling datasets and (2) can quickly adapt to a new cohort by fine-tuning the instance normalization parameters, thus learning the new cohort bias with only 10 labelled samples.