 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Gain Sampling for Active Learning in Medical Image Classification
Paper and Code
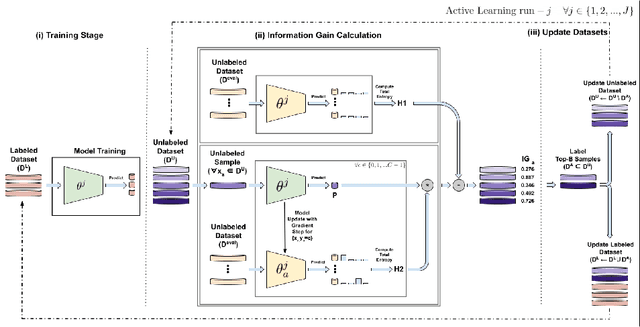
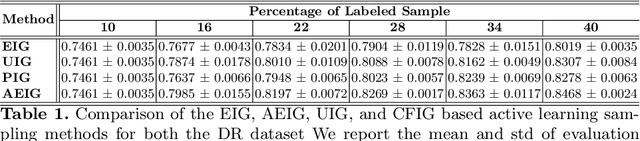
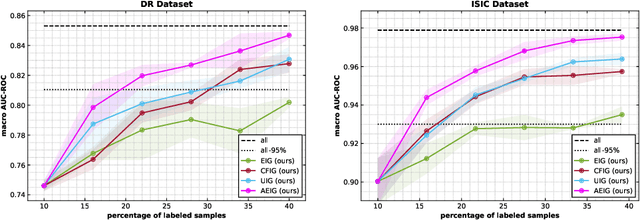
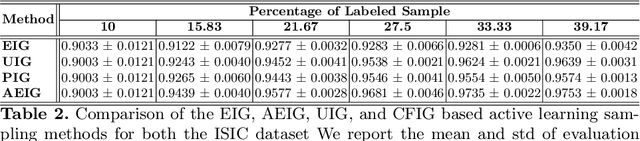
Large, annotated datasets are not widely available in medical image analysis due to the prohibitive time, costs, and challenges associated with labelling large datasets. Unlabelled datasets are easier to obtain, and in many contexts, it would be feasible for an expert to provide labels for a small subset of images. This work presents an information-theoretic active learning framework that guides the optimal selection of images from the unlabelled pool to be labeled based on maximizing the expected information gain (EIG) on an evaluation dataset. Experiments are performed on two different medical image classification datasets: multi-class diabetic retinopathy disease scale classification and multi-class skin lesion classification. Results indicate that by adapting EIG to account for class-imbalances, our proposed Adapted Expected Information Gain (AEIG) outperforms several popular baselines including the diversity based CoreSet and uncertainty based maximum entropy sampling. Specifically, AEIG achieves ~95% of overall performance with only 19% of the training data, while other active learning approaches require around 25%. We show that, by careful design choices, our model can be integrated into existing deep learning classifiers.