 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Diffusion Models are Medical Image Classifiers that Provide Explainability and Uncertainty for Free
Feb 06, 2025



Discriminative classifiers have become a foundational tool in deep learning for medical imaging, excelling at learning separable features of complex data distributions. However, these models often need careful design, augmentation, and training techniques to ensure safe and reliable deployment. Recently, diffusion models have become synonymous with generative modeling in 2D. These models showcase robustness across a range of tasks including natural image classification, where classification is performed by comparing reconstruction errors across images generated for each possible conditioning input. This work presents the first exploration of the potential of class conditional diffusion models for 2D medical image classification. First, we develop a novel majority voting scheme shown to improve the performance of medical diffusion classifiers. Next, extensive experiments on the CheXpert and ISIC Melanoma skin cancer datasets demonstrate that foundation and trained-from-scratch diffusion models achieve competitive performance against SOTA discriminative classifiers without the need for explicit supervision. In addition, we show that diffusion classifiers are intrinsically explainable, and can be used to quantify the uncertainty of their predictions, increasing their trustworthiness and reliability in safety-critical, clinical contexts. Further information is available on our project page: https://faverogian.github.io/med-diffusion-classifier.github.io/
CAManim: Animating end-to-end network activation maps
Dec 19, 2023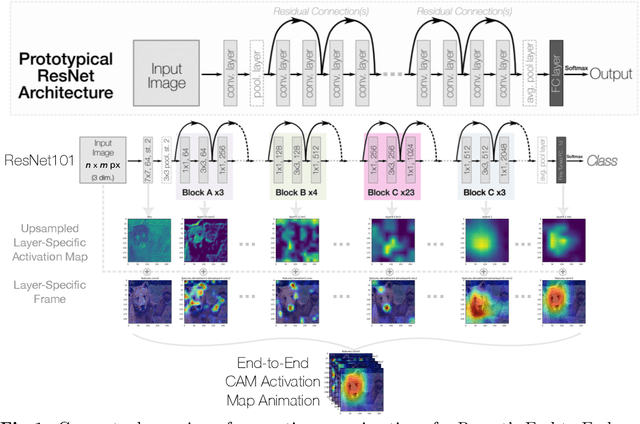
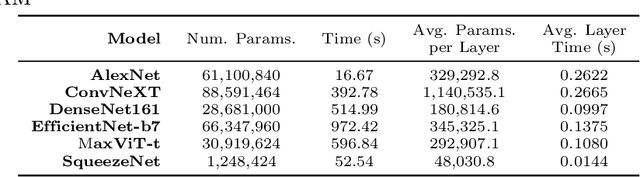
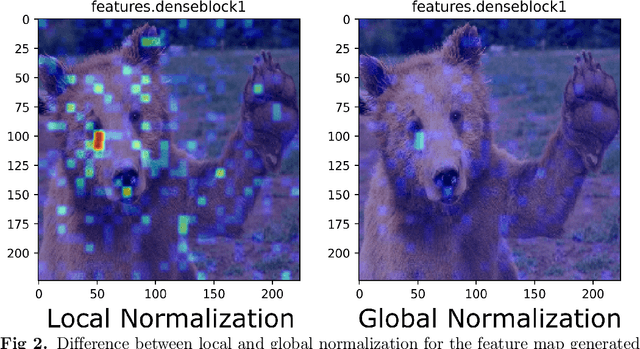
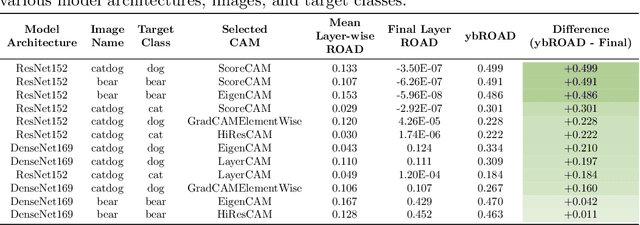
Deep neural networks have been widely adopted in numerous domains due to their high performance and accessibility to developers and application-specific end-users. Fundamental to image-based applications is the development of Convolutional Neural Networks (CNNs), which possess the ability to automatically extract features from data. However, comprehending these complex models and their learned representations, which typically comprise millions of parameters and numerous layers, remains a challenge for both developers and end-users. This challenge arises due to the absence of interpretable and transparent tools to make sense of black-box models. There exists a growing body of Explainable Artificial Intelligence (XAI) literature, including a collection of methods denoted Class Activation Maps (CAMs), that seek to demystify what representations the model learns from the data, how it informs a given prediction, and why it, at times, performs poorly in certain tasks. We propose a novel XAI visualization method denoted CAManim that seeks to simultaneously broaden and focus end-user understanding of CNN predictions by animating the CAM-based network activation maps through all layers, effectively depicting from end-to-end how a model progressively arrives at the final layer activation. Herein, we demonstrate that CAManim works with any CAM-based method and various CNN architectures. Beyond qualitative model assessments, we additionally propose a novel quantitative assessment that expands upon the Remove and Debias (ROAD) metric, pairing the qualitative end-to-end network visual explanations assessment with our novel quantitative "yellow brick ROAD" assessment (ybROAD). This builds upon prior research to address the increasing demand for interpretable, robust, and transparent model assessment methodology, ultimately improving an end-user's trust in a given model's predictions.
MetaCAM: Ensemble-Based Class Activation Map
Jul 31, 2023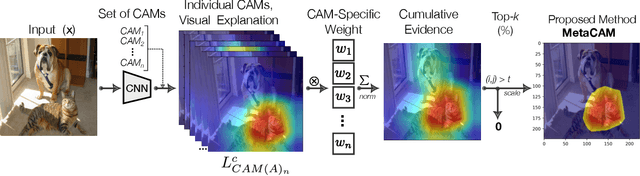

The need for clear, trustworthy explanations of deep learning model predictions is essential for high-criticality fields, such as medicine and biometric identification. Class Activation Maps (CAMs) are an increasingly popular category of visual explanation methods for Convolutional Neural Networks (CNNs). However, the performance of individual CAMs depends largely on experimental parameters such as the selected image, target class, and model. Here, we propose MetaCAM, an ensemble-based method for combining multiple existing CAM methods based on the consensus of the top-k% most highly activated pixels across component CAMs. We perform experiments to quantifiably determine the optimal combination of 11 CAMs for a given MetaCAM experiment. A new method denoted Cumulative Residual Effect (CRE) is proposed to summarize large-scale ensemble-based experiments. We also present adaptive thresholding and demonstrate how it can be applied to individual CAMs to improve their performance, measured using pixel perturbation method Remove and Debias (ROAD). Lastly, we show that MetaCAM outperforms existing CAMs and refines the most salient regions of images used for model predictions. In a specific example, MetaCAM improved ROAD performance to 0.393 compared to 11 individual CAMs with ranges from -0.101-0.172, demonstrating the importance of combining CAMs through an ensembling method and adaptive thresholding.