 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL4Med-DDPO: Reinforcement Learning for Controlled Guidance Towards Diverse Medical Image Generation using Vision-Language Foundation Models
Mar 20, 2025



Vision-Language Foundation Models (VLFM) have shown a tremendous increase in performance in terms of generating high-resolution, photorealistic natural images. While VLFMs show a rich understanding of semantic content across modalities, they often struggle with fine-grained alignment tasks that require precise correspondence between image regions and textual descriptions a limitation in medical imaging, where accurate localization and detection of clinical features are essential for diagnosis and analysis. To address this issue, we propose a multi-stage architecture where a pre-trained VLFM provides a cursory semantic understanding, while a reinforcement learning (RL) algorithm refines the alignment through an iterative process that optimizes for understanding semantic context. The reward signal is designed to align the semantic information of the text with synthesized images. We demonstrate the effectiveness of our method on a medical imaging skin dataset where the generated images exhibit improved generation quality and alignment with prompt over the fine-tuned Stable Diffusion. We also show that the synthesized samples could be used to improve disease classifier performance for underrepresented subgroups through augmentation.
Conditional Diffusion Models are Medical Image Classifiers that Provide Explainability and Uncertainty for Free
Feb 06, 2025



Discriminative classifiers have become a foundational tool in deep learning for medical imaging, excelling at learning separable features of complex data distributions. However, these models often need careful design, augmentation, and training techniques to ensure safe and reliable deployment. Recently, diffusion models have become synonymous with generative modeling in 2D. These models showcase robustness across a range of tasks including natural image classification, where classification is performed by comparing reconstruction errors across images generated for each possible conditioning input. This work presents the first exploration of the potential of class conditional diffusion models for 2D medical image classification. First, we develop a novel majority voting scheme shown to improve the performance of medical diffusion classifiers. Next, extensive experiments on the CheXpert and ISIC Melanoma skin cancer datasets demonstrate that foundation and trained-from-scratch diffusion models achieve competitive performance against SOTA discriminative classifiers without the need for explicit supervision. In addition, we show that diffusion classifiers are intrinsically explainable, and can be used to quantify the uncertainty of their predictions, increasing their trustworthiness and reliability in safety-critical, clinical contexts. Further information is available on our project page: https://faverogian.github.io/med-diffusion-classifier.github.io/
Toward Reliable Human Pose Forecasting with Uncertainty
Apr 13, 2023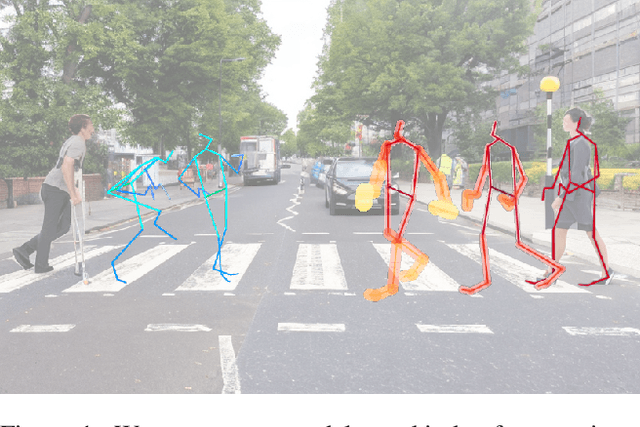
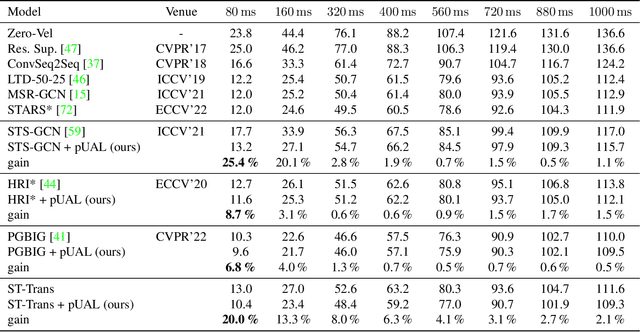
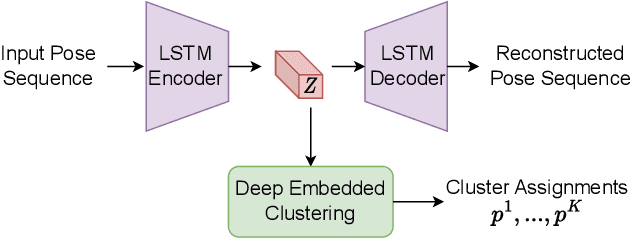
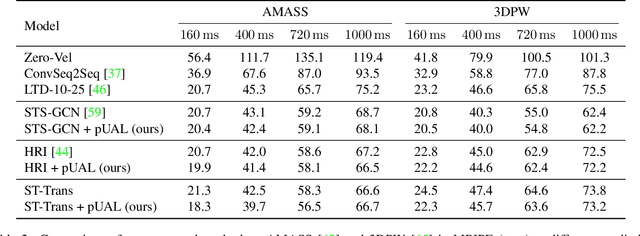
Recently, there has been an arms race of pose forecasting methods aimed at solving the spatio-temporal task of predicting a sequence of future 3D poses of a person given a sequence of past observed ones. However, the lack of unified benchmarks and limited uncertainty analysis have hindered progress in the field. To address this, we first develop an open-source library for human pose forecasting, featuring multiple models, datasets, and standardized evaluation metrics, with the aim of promoting research and moving toward a unified and fair evaluation. Second, we devise two types of uncertainty in the problem to increase performance and convey better trust: 1) we propose a method for modeling aleatoric uncertainty by using uncertainty priors to inject knowledge about the behavior of uncertainty. This focuses the capacity of the model in the direction of more meaningful supervision while reducing the number of learned parameters and improving stability; 2) we introduce a novel approach for quantifying the epistemic uncertainty of any model through clustering and measuring the entropy of its assignments. Our experiments demonstrate up to $25\%$ improvements in accuracy and better performance in uncertainty estimation.