 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Advancing License Plate Super-Resolution in Real-World Scenarios: A Dataset and Benchmark
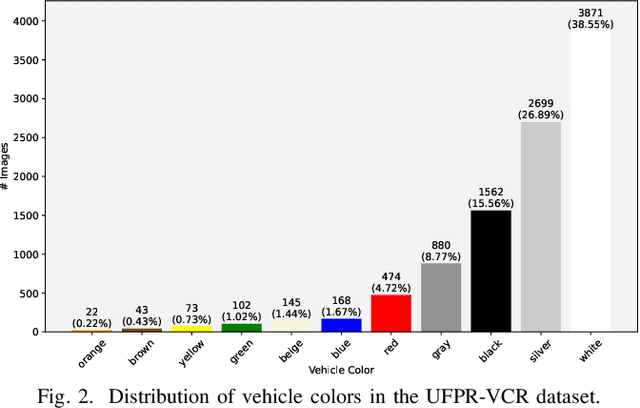
May 09, 2025Recent advancements in super-resolution for License Plate Recognition (LPR) have sought to address challenges posed by low-resolution (LR) and degraded images in surveillance, traffic monitoring, and forensic applications. However, existing studies have relied on private datasets and simplistic degradation models. To address this gap, we introduce UFPR-SR-Plates, a novel dataset containing 10,000 tracks with 100,000 paired low and high-resolution license plate images captured under real-world conditions. We establish a benchmark using multiple sequential LR and high-resolution (HR) images per vehicle -- five of each -- and two state-of-the-art models for super-resolution of license plates. We also investigate three fusion strategies to evaluate how combining predictions from a leading Optical Character Recognition (OCR) model for multiple super-resolved license plates enhances overall performance. Our findings demonstrate that super-resolution significantly boosts LPR performance, with further improvements observed when applying majority vote-based fusion techniques. Specifically, the Layout-Aware and Character-Driven Network (LCDNet) model combined with the Majority Vote by Character Position (MVCP) strategy led to the highest recognition rates, increasing from 1.7% with low-resolution images to 31.1% with super-resolution, and up to 44.7% when combining OCR outputs from five super-resolved images. These findings underscore the critical role of super-resolution and temporal information in enhancing LPR accuracy under real-world, adverse conditions. The proposed dataset is publicly available to support further research and can be accessed at: https://valfride.github.io/nascimento2024toward/
Enhancing License Plate Super-Resolution: A Layout-Aware and Character-Driven Approach
Aug 27, 2024



Despite significant advancements in License Plate Recognition (LPR) through deep learning, most improvements rely on high-resolution images with clear characters. This scenario does not reflect real-world conditions where traffic surveillance often captures low-resolution and blurry images. Under these conditions, characters tend to blend with the background or neighboring characters, making accurate LPR challenging. To address this issue, we introduce a novel loss function, Layout and Character Oriented Focal Loss (LCOFL), which considers factors such as resolution, texture, and structural details, as well as the performance of the LPR task itself. We enhance character feature learning using deformable convolutions and shared weights in an attention module and employ a GAN-based training approach with an Optical Character Recognition (OCR) model as the discriminator to guide the super-resolution process. Our experimental results show significant improvements in character reconstruction quality, outperforming two state-of-the-art methods in both quantitative and qualitative measures. Our code is publicly available at https://github.com/valfride/lpsr-lacd
Multi-Feature Aggregation in Diffusion Models for Enhanced Face Super-Resolution
Aug 27, 2024


Super-resolution algorithms often struggle with images from surveillance environments due to adverse conditions such as unknown degradation, variations in pose, irregular illumination, and occlusions. However, acquiring multiple images, even of low quality, is possible with surveillance cameras. In this work, we develop an algorithm based on diffusion models that utilize a low-resolution image combined with features extracted from multiple low-quality images to generate a super-resolved image while minimizing distortions in the individual's identity. Unlike other algorithms, our approach recovers facial features without explicitly providing attribute information or without the need to calculate a gradient of a function during the reconstruction process. To the best of our knowledge, this is the first time multi-features combined with low-resolution images are used as conditioners to generate more reliable super-resolution images using stochastic differential equations. The FFHQ dataset was employed for training, resulting in state-of-the-art performance in facial recognition and verification metrics when evaluated on the CelebA and Quis-Campi datasets. Our code is publicly available at https://github.com/marcelowds/fasr
A Multilevel Strategy to Improve People Tracking in a Real-World Scenario
Apr 29, 2024
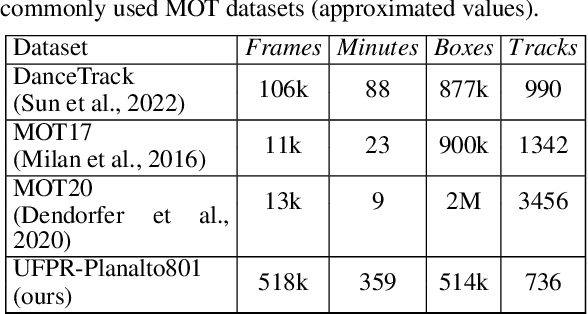

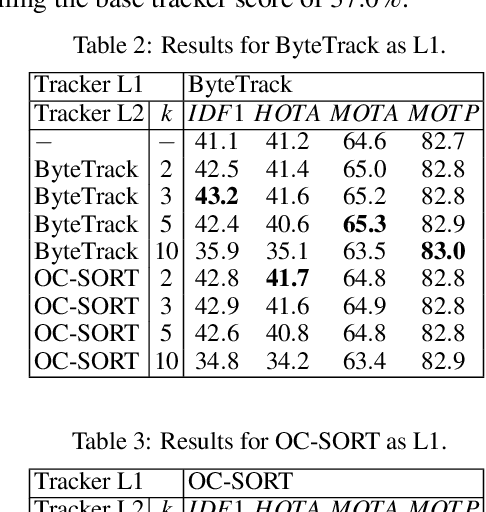
The Pal\'acio do Planalto, office of the President of Brazil, was invaded by protesters on January 8, 2023. Surveillance videos taken from inside the building were subsequently released by the Brazilian Supreme Court for public scrutiny. We used segments of such footage to create the UFPR-Planalto801 dataset for people tracking and re-identification in a real-world scenario. This dataset consists of more than 500,000 images. This paper presents a tracking approach targeting this dataset. The method proposed in this paper relies on the use of known state-of-the-art trackers combined in a multilevel hierarchy to correct the ID association over the trajectories. We evaluated our method using IDF1, MOTA, MOTP and HOTA metrics. The results show improvements for every tracker used in the experiments, with IDF1 score increasing by a margin up to 9.5%.
* Accepted for presentation at the International Conference on Computer Vision Theory and Applications (VISAPP) 2024
Face Super-Resolution Using Stochastic Differential Equations
Sep 24, 2022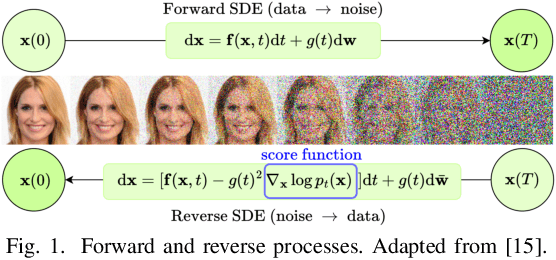
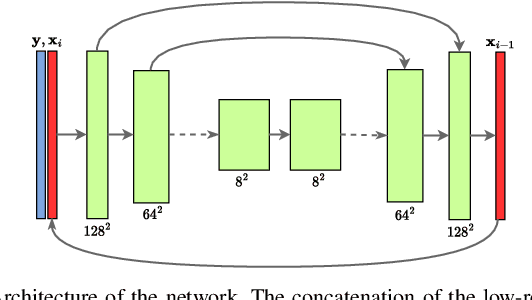

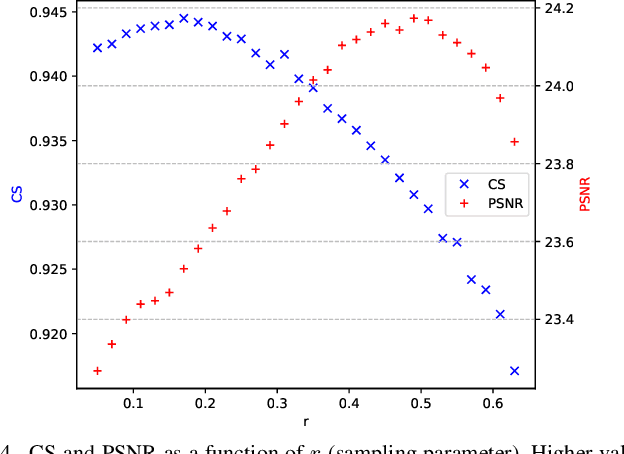
Diffusion models have proven effective for various applications such as images, audio and graph generation. Other important applications are image super-resolution and the solution of inverse problems. More recently, some works have used stochastic differential equations (SDEs) to generalize diffusion models to continuous time. In this work, we introduce SDEs to generate super-resolution face images. To the best of our knowledge, this is the first time SDEs have been used for such an application. The proposed method provides an improved peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), and consistency than the existing super-resolution methods based on diffusion models. In particular, we also assess the potential application of this method for the face recognition task. A generic facial feature extractor is used to compare the super-resolution images with the ground truth and superior results were obtained compared with other methods. Our code is publicly available at https://github.com/marcelowds/sr-sde