 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Video Captioning Using Unsupervised Semantic Information
Paper and Code
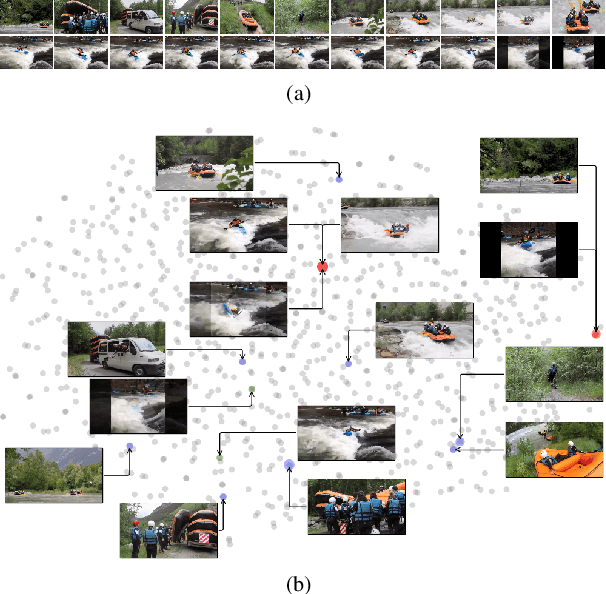
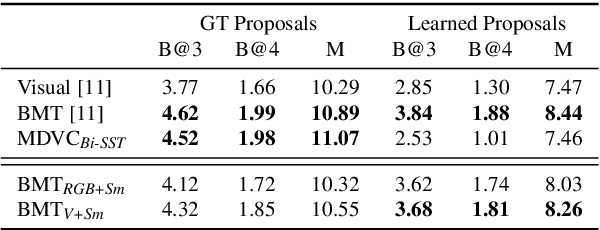
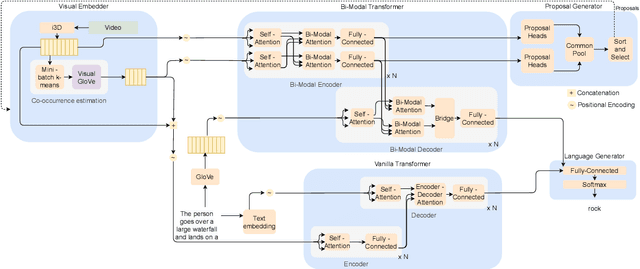

We introduce a method to learn unsupervised semantic visual information based on the premise that complex events (e.g., minutes) can be decomposed into simpler events (e.g., a few seconds), and that these simple events are shared across several complex events. We split a long video into short frame sequences to extract their latent representation with three-dimensional convolutional neural networks. A clustering method is used to group representations producing a visual codebook (i.e., a long video is represented by a sequence of integers given by the cluster labels). A dense representation is learned by encoding the co-occurrence probability matrix for the codebook entries. We demonstrate how this representation can leverage the performance of the dense video captioning task in a scenario with only visual features. As a result of this approach, we are able to replace the audio signal in the Bi-Modal Transformer (BMT) method and produce temporal proposals with comparable performance. Furthermore, we concatenate the visual signal with our descriptor in a vanilla transformer method to achieve state-of-the-art performance in captioning compared to the methods that explore only visual features, as well as a competitive performance with multi-modal methods. Our code is available at https://github.com/valterlej/dvcusi.