 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Cross-dataset Generalization in License Plate Recognition
Jan 04, 2022
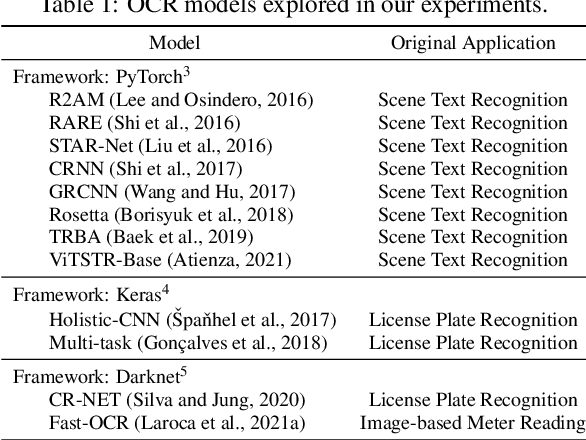
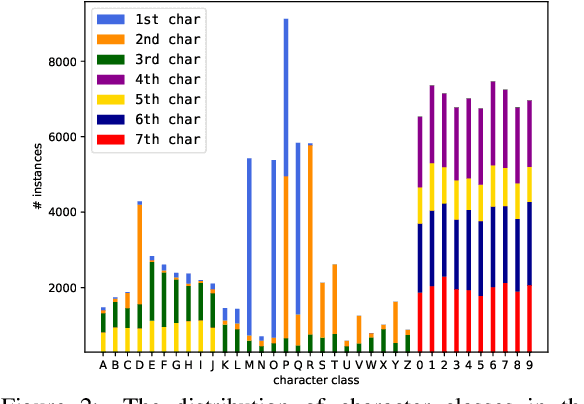
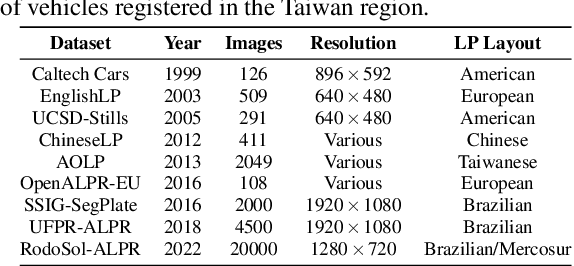
Automatic License Plate Recognition (ALPR) systems have shown remarkable performance on license plates (LPs) from multiple regions due to advances in deep learning and the increasing availability of datasets. The evaluation of deep ALPR systems is usually done within each dataset; therefore, it is questionable if such results are a reliable indicator of generalization ability. In this paper, we propose a traditional-split versus leave-one-dataset-out experimental setup to empirically assess the cross-dataset generalization of 12 Optical Character Recognition (OCR) models applied to LP recognition on nine publicly available datasets with a great variety in several aspects (e.g., acquisition settings, image resolution, and LP layouts). We also introduce a public dataset for end-to-end ALPR that is the first to contain images of vehicles with Mercosur LPs and the one with the highest number of motorcycle images. The experimental results shed light on the limitations of the traditional-split protocol for evaluating approaches in the ALPR context, as there are significant drops in performance for most datasets when training and testing the models in a leave-one-dataset-out fashion.
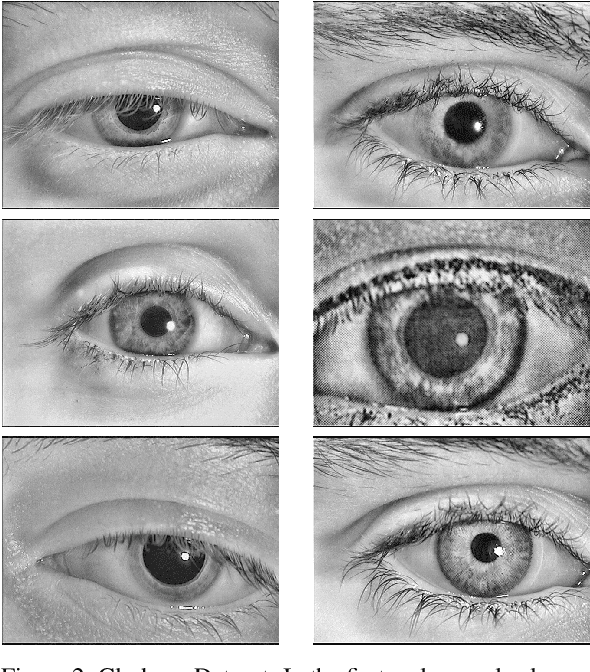
UFPR-Periocular: A Periocular Dataset Collected by Mobile Devices in Unconstrained Scenarios
Nov 24, 2020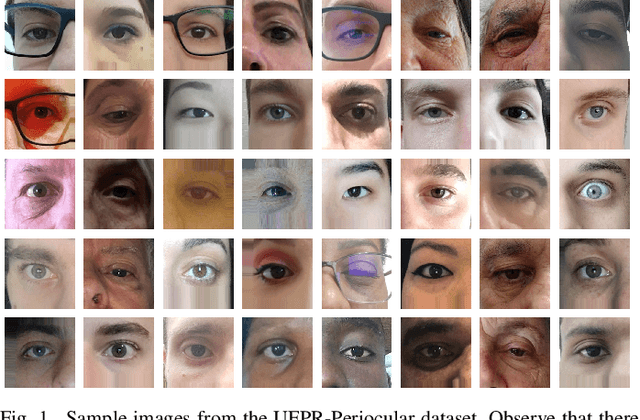
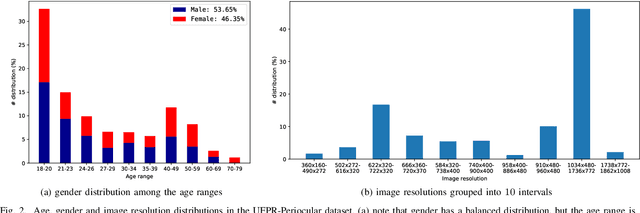
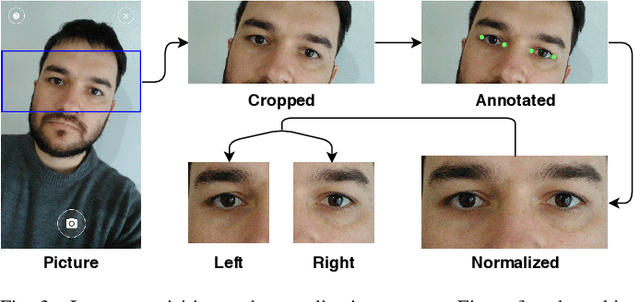
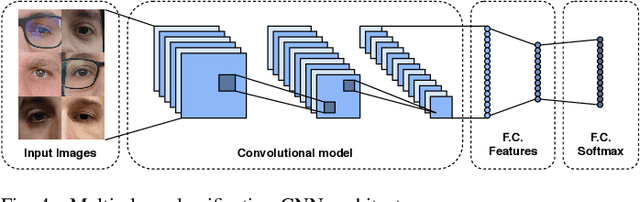
Recently, ocular biometrics in unconstrained environments using images obtained at visible wavelength have gained the researchers' attention, especially with images captured by mobile devices. Periocular recognition has been demonstrated to be an alternative when the iris trait is not available due to occlusions or low image resolution. However, the periocular trait does not have the high uniqueness presented in the iris trait. Thus, the use of datasets containing many subjects is essential to assess biometric systems' capacity to extract discriminating information from the periocular region. Also, to address the within-class variability caused by lighting and attributes in the periocular region, it is of paramount importance to use datasets with images of the same subject captured in distinct sessions. As the datasets available in the literature do not present all these factors, in this work, we present a new periocular dataset containing samples from 1,122 subjects, acquired in 3 sessions by 196 different mobile devices. The images were captured under unconstrained environments with just a single instruction to the participants: to place their eyes on a region of interest. We also performed an extensive benchmark with several Convolutional Neural Network (CNN) architectures and models that have been employed in state-of-the-art approaches based on Multi-class Classification, Multitask Learning, Pairwise Filters Network, and Siamese Network. The results achieved in the closed- and open-world protocol, considering the identification and verification tasks, show that this area still needs research and development.
CNN Hyperparameter tuning applied to Iris Liveness Detection
Feb 12, 2020

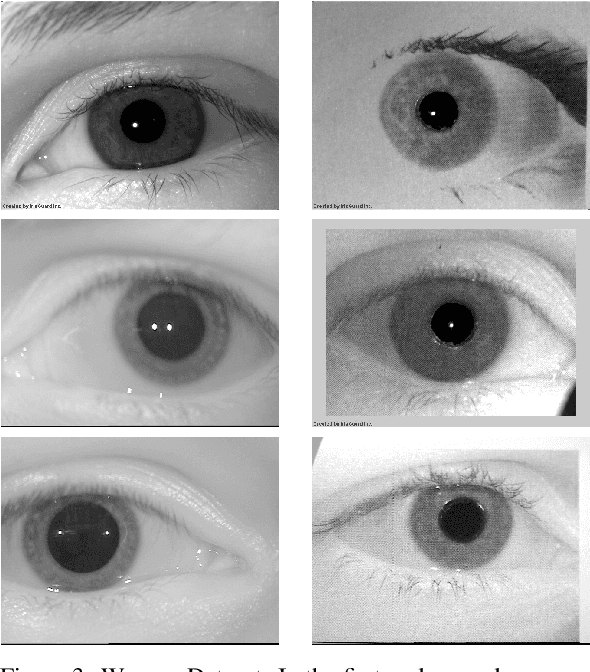
The iris pattern has significantly improved the biometric recognition field due to its high level of stability and uniqueness. Such physical feature has played an important role in security and other related areas. However, presentation attacks, also known as spoofing techniques, can be used to bypass the biometric system with artifacts such as printed images, artificial eyes, and textured contact lenses. To improve the security of these systems, many liveness detection methods have been proposed, and the first Internacional Iris Liveness Detection competition was launched in 2013 to evaluate their effectiveness. In this paper, we propose a hyperparameter tuning of the CASIA algorithm, submitted by the Chinese Academy of Sciences to the third competition of Iris Liveness Detection, in 2017. The modifications proposed promoted an overall improvement, with an 8.48% Attack Presentation Classification Error Rate (APCER) and 0.18% Bonafide Presentation Classification Error Rate (BPCER) for the evaluation of the combined datasets. Other threshold values were evaluated in an attempt to reduce the trade-off between the APCER and the BPCER on the evaluated datasets and worked out successfully.
Deep Representations for Cross-spectral Ocular Biometrics
Nov 21, 2019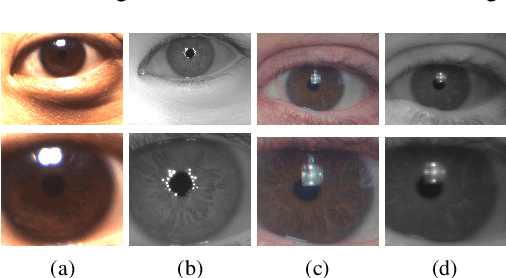


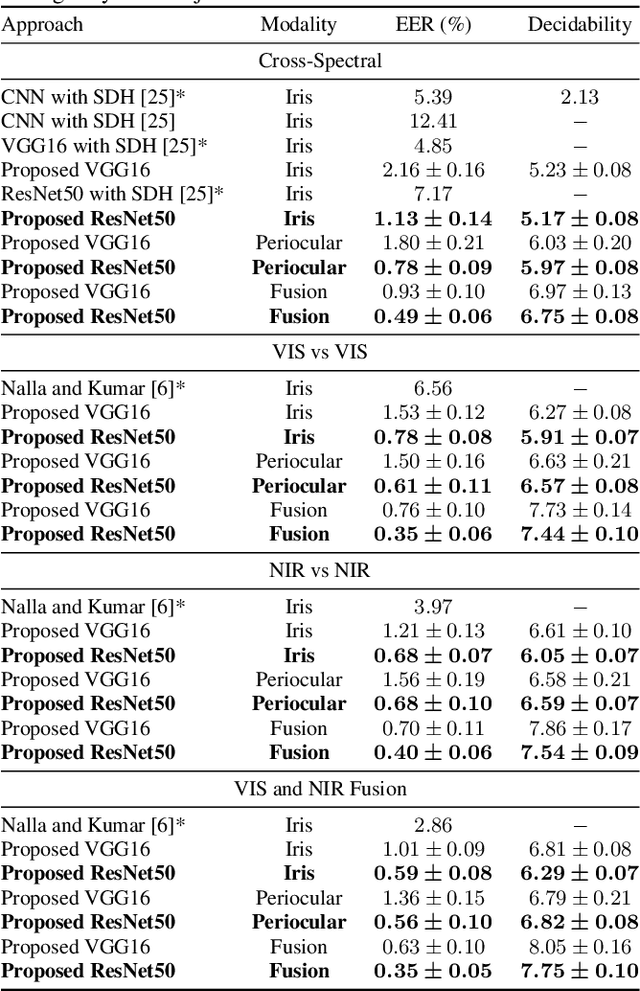
One of the major challenges in ocular biometrics is the cross-spectral scenario, i.e., how to match images acquired in different wavelengths (typically visible (VIS) against near-infrared (NIR)). This article designs and extensively evaluates cross-spectral ocular verification methods, for both the closed and open-world settings, using well known deep learning representations based on the iris and periocular regions. Using as inputs the bounding boxes of non-normalized iris/periocular regions, we fine-tune Convolutional Neural Network(CNN) models (based either on VGG16 or ResNet-50 architectures), originally trained for face recognition. Based on the experiments carried out in two publicly available cross-spectral ocular databases, we report results for intra-spectral and cross-spectral scenarios, with the best performance being observed when fusing ResNet-50 deep representations from both the periocular and iris regions. When compared to the state-of-the-art, we observed that the proposed solution consistently reduces the Equal Error Rate(EER) values by 90% / 93% / 96% and 61% / 77% / 83% on the cross-spectral scenario and in the PolyU Bi-spectral and Cross-eye-cross-spectral datasets. Lastly, we evaluate the effect that the "deepness" factor of feature representations has in recognition effectiveness, and - based on a subjective analysis of the most problematic pairwise comparisons - we point out further directions for this field of research.
Simultaneous Iris and Periocular Region Detection Using Coarse Annotations
Jul 31, 2019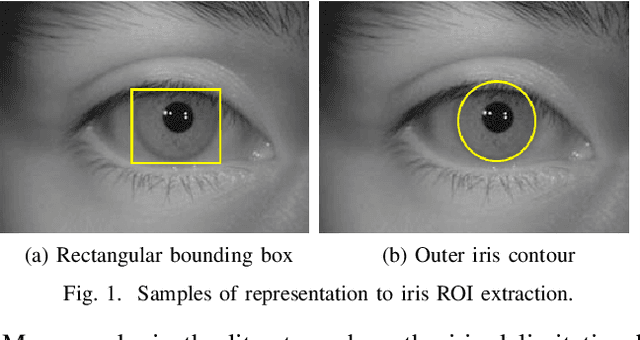
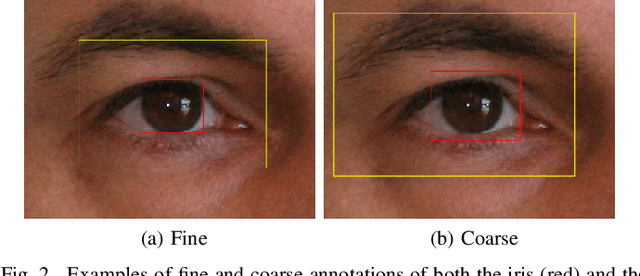
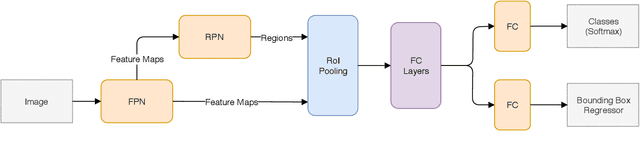
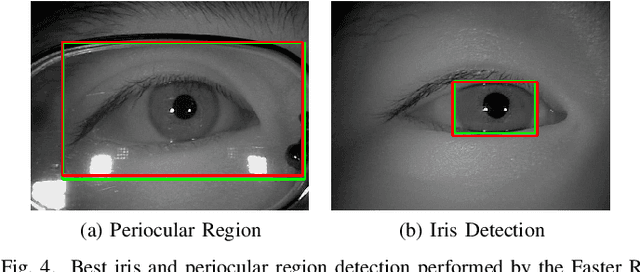
In this work, we propose to detect the iris and periocular regions simultaneously using coarse annotations and two well-known object detectors: YOLOv2 and Faster R-CNN. We believe coarse annotations can be used in recognition systems based on the iris and periocular regions, given the much smaller engineering effort required to manually annotate the training images. We manually made coarse annotations of the iris and periocular regions (122K images from the visible (VIS) spectrum and 38K images from the near-infrared (NIR) spectrum). The iris annotations in the NIR databases were generated semi-automatically by first applying an iris segmentation CNN and then performing a manual inspection. These annotations were made for 11 well-known public databases (3 NIR and 8 VIS) designed for the iris-based recognition problem and are publicly available to the research community. Experimenting our proposal on these databases, we highlight two results. First, the Faster R-CNN + Feature Pyramid Network (FPN) model reported an Intersection over Union (IoU) higher than YOLOv2 (91.86% vs 85.30%). Second, the detection of the iris and periocular regions being performed simultaneously is as accurate as performed separately, but with a lower computational cost, i.e., two tasks were carried out at the cost of one.
Robust Iris Segmentation Based on Fully Convolutional Networks and Generative Adversarial Networks
Sep 04, 2018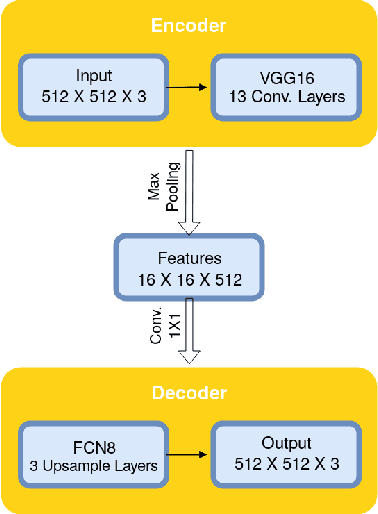
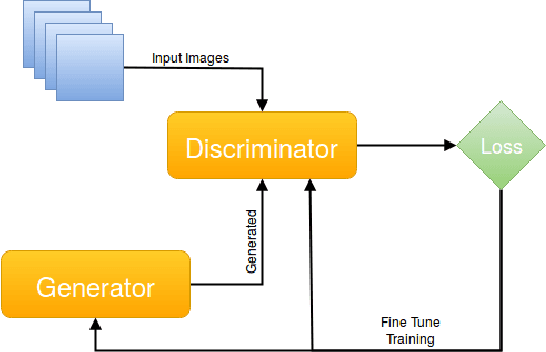
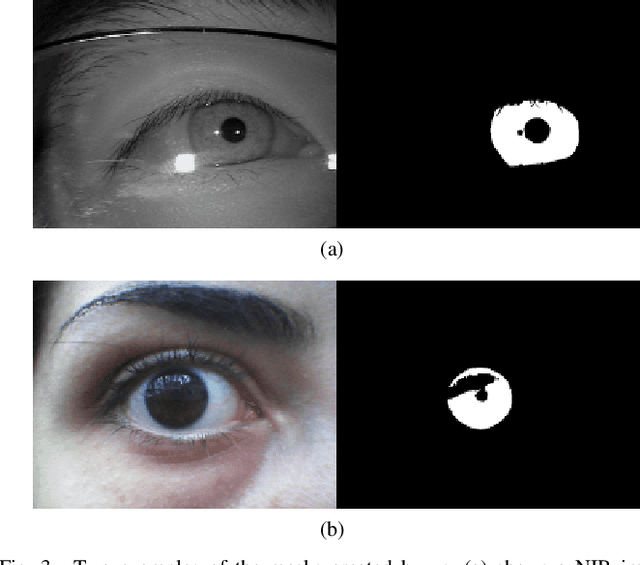
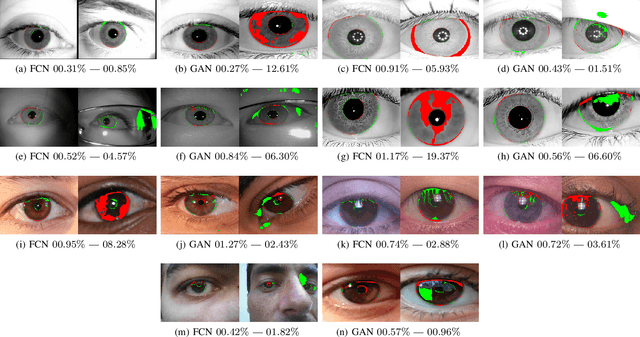
The iris can be considered as one of the most important biometric traits due to its high degree of uniqueness. Iris-based biometrics applications depend mainly on the iris segmentation whose suitability is not robust for different environments such as near-infrared (NIR) and visible (VIS) ones. In this paper, two approaches for robust iris segmentation based on Fully Convolutional Networks (FCNs) and Generative Adversarial Networks (GANs) are described. Similar to a common convolutional network, but without the fully connected layers (i.e., the classification layers), an FCN employs at its end a combination of pooling layers from different convolutional layers. Based on the game theory, a GAN is designed as two networks competing with each other to generate the best segmentation. The proposed segmentation networks achieved promising results in all evaluated datasets (i.e., BioSec, CasiaI3, CasiaT4, IITD-1) of NIR images and (NICE.I, CrEye-Iris and MICHE-I) of VIS images in both non-cooperative and cooperative domains, outperforming the baselines techniques which are the best ones found so far in the literature, i.e., a new state of the art for these datasets. Furthermore, we manually labeled 2,431 images from CasiaT4, CrEye-Iris and MICHE-I datasets, making the masks available for research purposes.
Fully Convolutional Networks and Generative Adversarial Networks Applied to Sclera Segmentation
Jul 09, 2018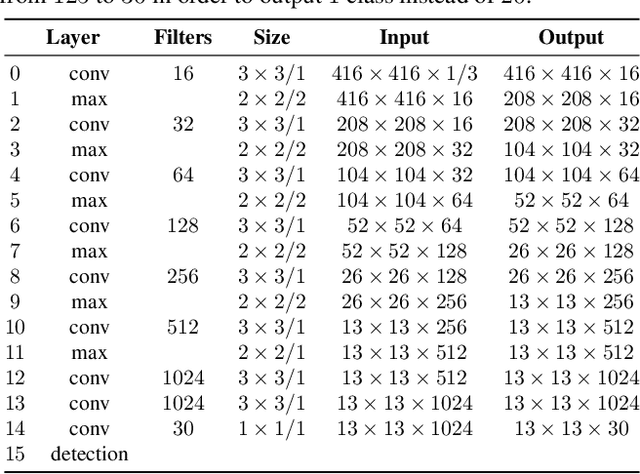
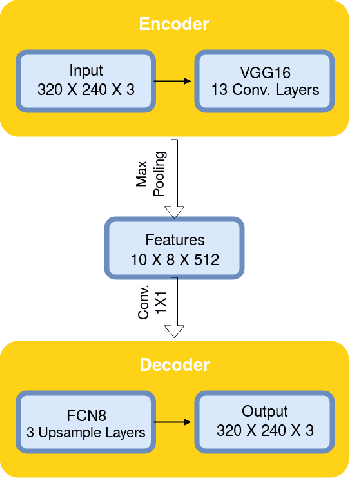


Due to the world's demand for security systems, biometrics can be seen as an important topic of research in computer vision. One of the biometric forms that has been gaining attention is the recognition based on sclera. The initial and paramount step for performing this type of recognition is the segmentation of the region of interest, i.e. the sclera. In this context, two approaches for such task based on the Fully Convolutional Network (FCN) and on Generative Adversarial Network (GAN) are introduced in this work. FCN is similar to a common convolution neural network, however the fully connected layers (i.e., the classification layers) are removed from the end of the network and the output is generated by combining the output of pooling layers from different convolutional ones. The GAN is based on the game theory, where we have two networks competing with each other to generate the best segmentation. In order to perform fair comparison with baselines and quantitative and objective evaluations of the proposed approaches, we provide to the scientific community new 1,300 manually segmented images from two databases. The experiments are performed on the UBIRIS.v2 and MICHE databases and the best performing configurations of our propositions achieved F-score's measures of 87.48% and 88.32%, respectively.