 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Graph-based Rank Aggregation for Improved Retrieval
Paper and Code
Jan 17, 2019
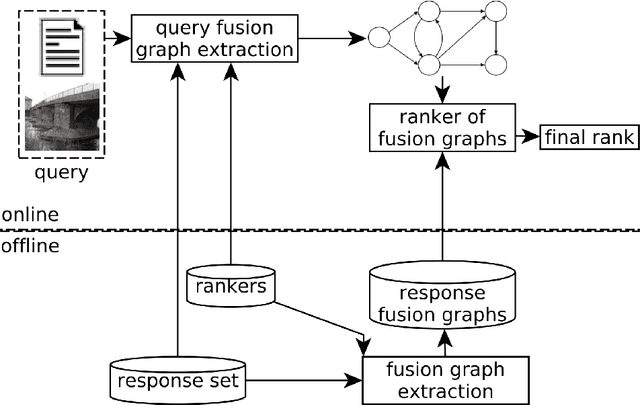
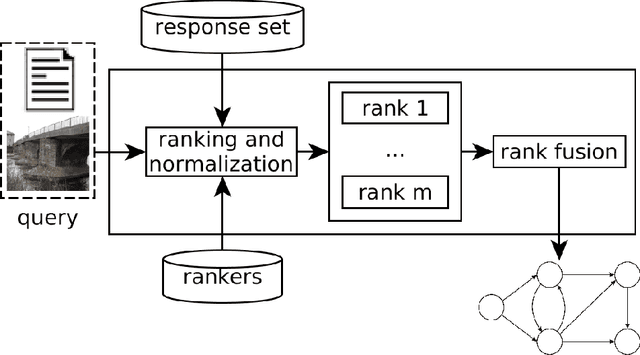
This paper presents a robust and comprehensive graph-based rank aggregation approach, used to combine results of isolated ranker models in retrieval tasks. The method follows an unsupervised scheme, which is independent of how the isolated ranks are formulated. Our approach is able to combine arbitrary models, defined in terms of different ranking criteria, such as those based on textual, image or hybrid content representations. We reformulate the ad-hoc retrieval problem as a document retrieval of their fusion graph, which we propose as a new unified representation model capable of merging multiple ranks and expressing inter-relationships of retrieval results automatically. By doing so, we claim that the retrieval system can benefit from learning the manifold structure of datasets, thus leading to more effective results. Another contribution is that our graph-based aggregation formulation, unlike existing approaches, allows for encapsulating contextual information encoded from multiple ranks, which can be directly used for ranking, without further computations and processing steps over the graphs. Based on the graphs, a novel similarity retrieval score is formulated using an efficient computation of minimum common subgraphs. Finally, another benefit over existing approaches is the absence of hyperparameters. A comprehensive experimental evaluation was conducted considering diverse well-known public datasets, composed of textual, image, and multimodal documents. Performed experiments demonstrate that our method reaches top performance, yielding better effectiveness scores than state-of-the-art baseline methods and promoting large gains over the rankers being fused, thus showing the successful capability of the proposal in representing queries based on a unified graph-based model of rank fusions.