 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Localization through Continual Predictive Learning
Paper and Code
Mar 26, 2020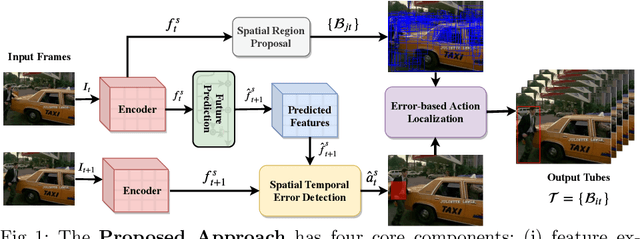

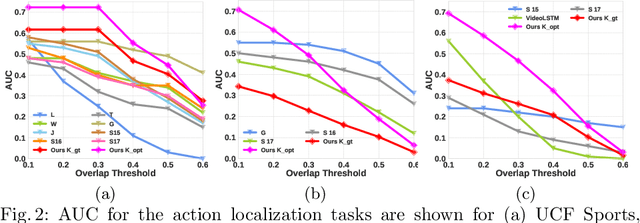
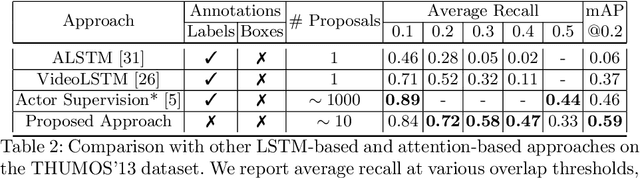
The problem of action recognition involves locating the action in the video, both over time and spatially in the image. The dominant current approaches use supervised learning to solve this problem, and require large amounts of annotated training data, in the form of frame-level bounding box annotations around the region of interest. In this paper, we present a new approach based on continual learning that uses feature-level predictions for self-supervision. It does not require any training annotations in terms of frame-level bounding boxes. The approach is inspired by cognitive models of visual event perception that propose a prediction-based approach to event understanding. We use a stack of LSTMs coupled with CNN encoder, along with novel attention mechanisms, to model the events in the video and use this model to predict high-level features for the future frames. The prediction errors are used to continuously learn the parameters of the models. This self-supervised framework is not complicated as other approaches but is very effective in learning robust visual representations for both labeling and localization. It should be noted that the approach outputs in a streaming fashion, requiring only a single pass through the video, making it amenable for real-time processing. We demonstrate this on three datasets - UCF Sports, JHMDB, and THUMOS'13 and show that the proposed approach outperforms weakly-supervised and unsupervised baselines and obtains competitive performance compared to fully supervised baselines. Finally, we show that the proposed framework can generalize to egocentric videos and obtain state-of-the-art results in unsupervised gaze prediction.