 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Attractor Models
Oct 03, 2024



Sequential memory, the ability to form and accurately recall a sequence of events or stimuli in the correct order, is a fundamental prerequisite for biological and artificial intelligence as it underpins numerous cognitive functions (e.g., language comprehension, planning, episodic memory formation, etc.) However, existing methods of sequential memory suffer from catastrophic forgetting, limited capacity, slow iterative learning procedures, low-order Markov memory, and, most importantly, the inability to represent and generate multiple valid future possibilities stemming from the same context. Inspired by biologically plausible neuroscience theories of cognition, we propose \textit{Predictive Attractor Models (PAM)}, a novel sequence memory architecture with desirable generative properties. PAM is a streaming model that learns a sequence in an online, continuous manner by observing each input \textit{only once}. Additionally, we find that PAM avoids catastrophic forgetting by uniquely representing past context through lateral inhibition in cortical minicolumns, which prevents new memories from overwriting previously learned knowledge. PAM generates future predictions by sampling from a union set of predicted possibilities; this generative ability is realized through an attractor model trained alongside the predictor. We show that PAM is trained with local computations through Hebbian plasticity rules in a biologically plausible framework. Other desirable traits (e.g., noise tolerance, CPU-based learning, capacity scaling) are discussed throughout the paper. Our findings suggest that PAM represents a significant step forward in the pursuit of biologically plausible and computationally efficient sequential memory models, with broad implications for cognitive science and artificial intelligence research.
Polyrhythmic Bimanual Coordination Training using Haptic Force Feedback
May 11, 2020
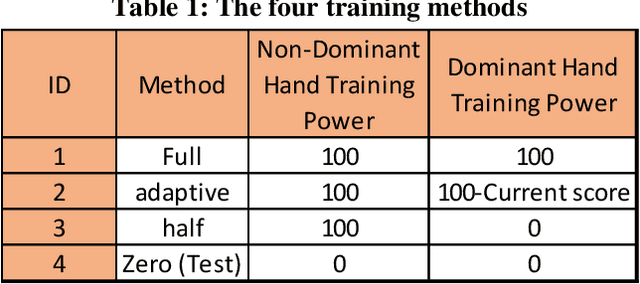

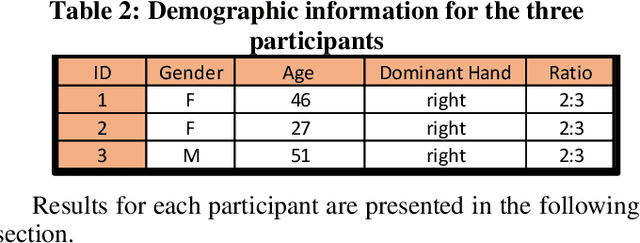
It is challenging to develop two thoughts at the same time or perform two uncorrelated motions simultaneously. This work looks specifically towards training humans to perform a 2:3 polyrhythmic bimanual ratio using haptic force feedback devices (SensAble Phantom OMNI). We implemented an interactive training session to help participants learn to decouple their hand motions quickly. Three subjects (2 Females, 1 Male) were tested and have successfully increased their scores after adaptive training durations of under five minutes.
BCI-Controlled Hands-Free Wheelchair Navigation with Obstacle Avoidance
May 08, 2020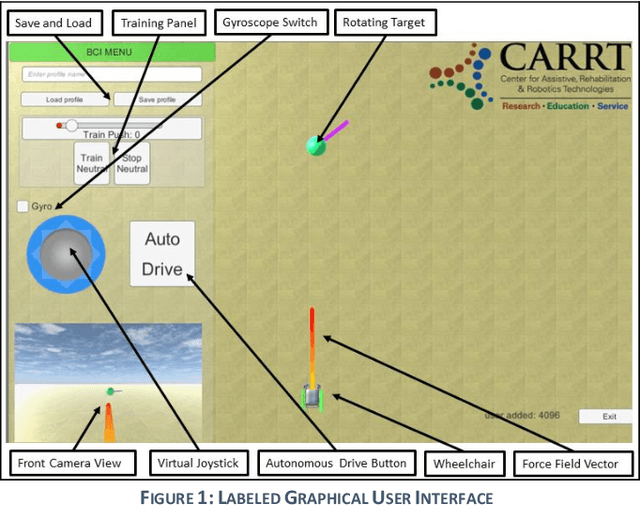
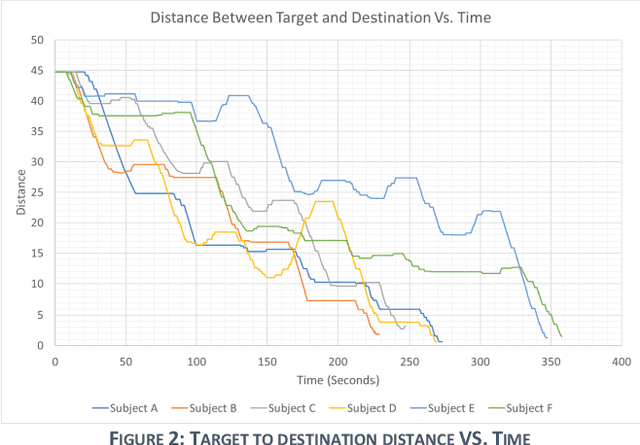

Brain-Computer interfaces (BCI) are widely used in reading brain signals and converting them into real-world motion. However, the signals produced from the BCI are noisy and hard to analyze. This paper looks specifically towards combining the BCI's latest technology with ultrasonic sensors to provide a hands-free wheelchair that can efficiently navigate through crowded environments. This combination provides safety and obstacle avoidance features necessary for the BCI Navigation system to gain more confidence and operate the wheelchair at a relatively higher velocity. A population of six human subjects tested the BCI-controller and obstacle avoidance features. Subjects were able to mentally control the destination of the wheelchair, by moving the target from the starting position to a predefined position, in an average of 287.12 seconds and a standard deviation of 48.63 seconds after 10 minutes of training. The wheelchair successfully avoided all obstacles placed by the subjects during the test.
Temporal Event Segmentation using Attention-based Perceptual Prediction Model for Continual Learning
May 07, 2020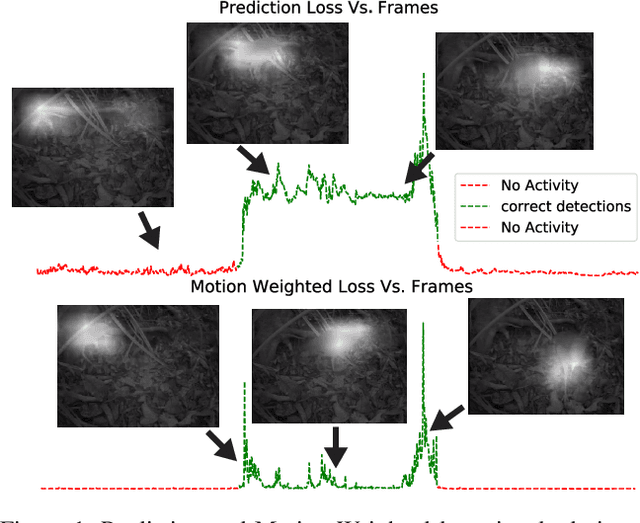


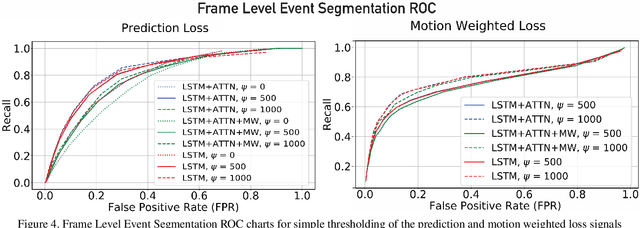
Temporal event segmentation of a long video into coherent events requires a high level understanding of activities' temporal features. The event segmentation problem has been tackled by researchers in an offline training scheme, either by providing full, or weak, supervision through manually annotated labels or by self-supervised epoch based training. In this work, we present a continual learning perceptual prediction framework (influenced by cognitive psychology) capable of temporal event segmentation through understanding of the underlying representation of objects within individual frames. Our framework also outputs attention maps which effectively localize and track events-causing objects in each frame. The model is tested on a wildlife monitoring dataset in a continual training manner resulting in $80\%$ recall rate at $20\%$ false positive rate for frame level segmentation. Activity level testing has yielded $80\%$ activity recall rate for one false activity detection every 50 minutes.