 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Event Segmentation using Attention-based Perceptual Prediction Model for Continual Learning
Paper and Code
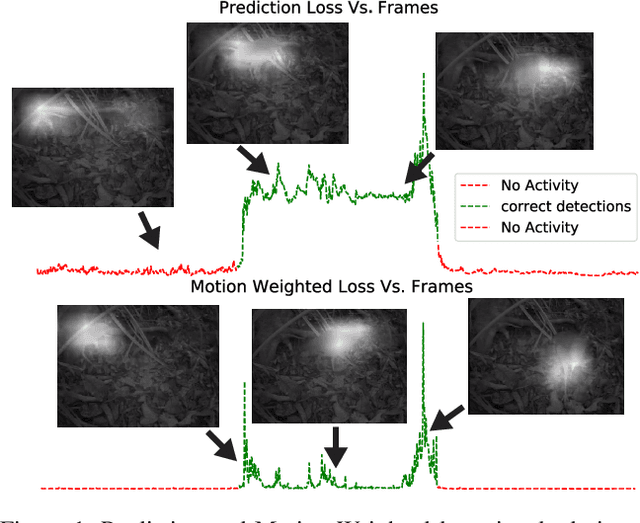


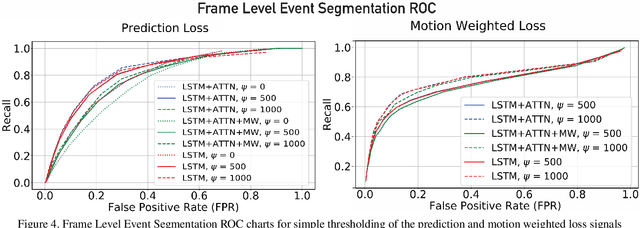
Temporal event segmentation of a long video into coherent events requires a high level understanding of activities' temporal features. The event segmentation problem has been tackled by researchers in an offline training scheme, either by providing full, or weak, supervision through manually annotated labels or by self-supervised epoch based training. In this work, we present a continual learning perceptual prediction framework (influenced by cognitive psychology) capable of temporal event segmentation through understanding of the underlying representation of objects within individual frames. Our framework also outputs attention maps which effectively localize and track events-causing objects in each frame. The model is tested on a wildlife monitoring dataset in a continual training manner resulting in $80\%$ recall rate at $20\%$ false positive rate for frame level segmentation. Activity level testing has yielded $80\%$ activity recall rate for one false activity detection every 50 minutes.