 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Actor-centered Representations for Action Localization in Streaming Videos using Predictive Learning
Paper and Code
Apr 29, 2021
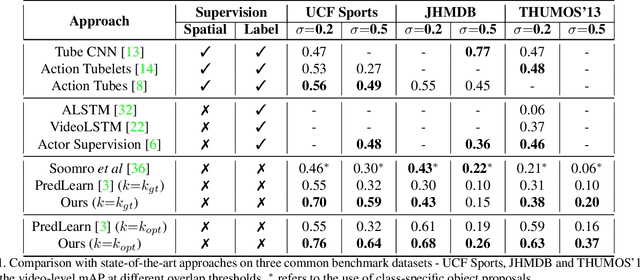

Event perception tasks such as recognizing and localizing actions in streaming videos are essential for tackling visual understanding tasks. Progress has primarily been driven by the use of large-scale, annotated training data in a supervised manner. In this work, we tackle the problem of learning \textit{actor-centered} representations through the notion of continual hierarchical predictive learning to localize actions in streaming videos without any training annotations. Inspired by cognitive theories of event perception, we propose a novel, self-supervised framework driven by the notion of hierarchical predictive learning to construct actor-centered features by attention-based contextualization. Extensive experiments on three benchmark datasets show that the approach can learn robust representations for localizing actions using only one epoch of training, i.e., we train the model continually in streaming fashion - one frame at a time, with a single pass through training videos. We show that the proposed approach outperforms unsupervised and weakly supervised baselines while offering competitive performance to fully supervised approaches. Finally, we show that the proposed model can generalize to out-of-domain data without significant loss in performance without any finetuning for both the recognition and localization tasks.