 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Convolutional Neural Networks with Limited Training Data for Ear Recognition in the Wild
Paper and Code
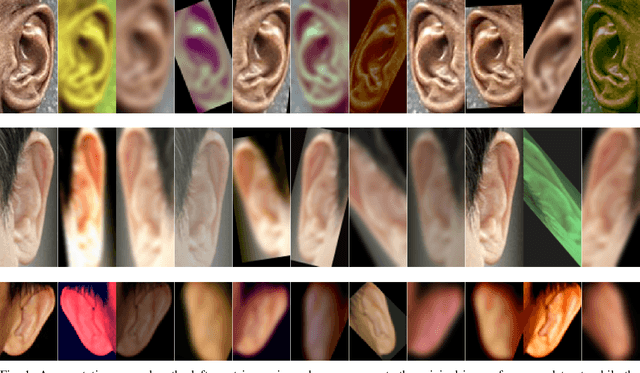
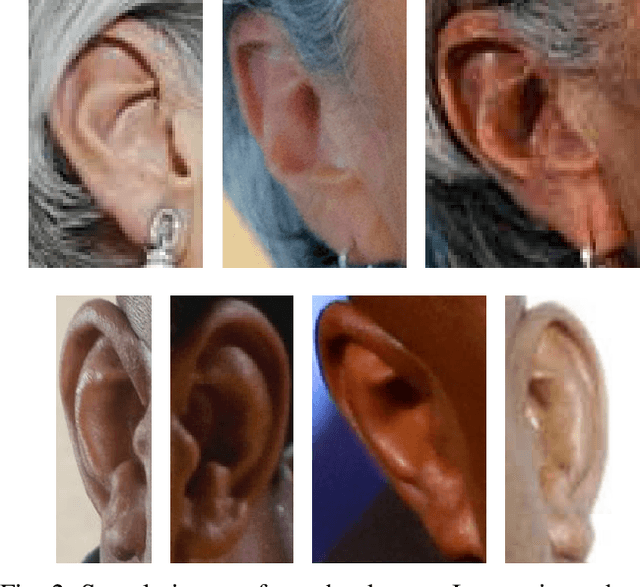
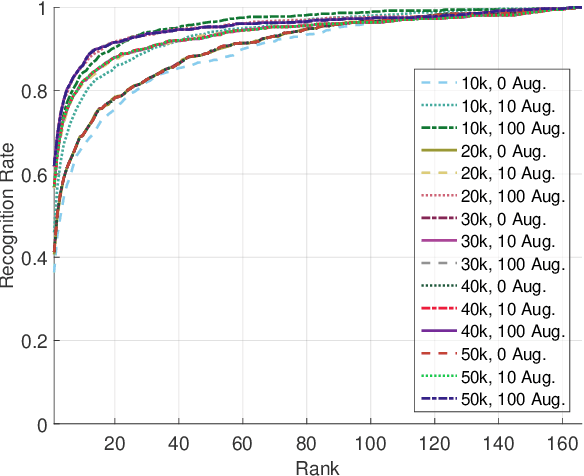
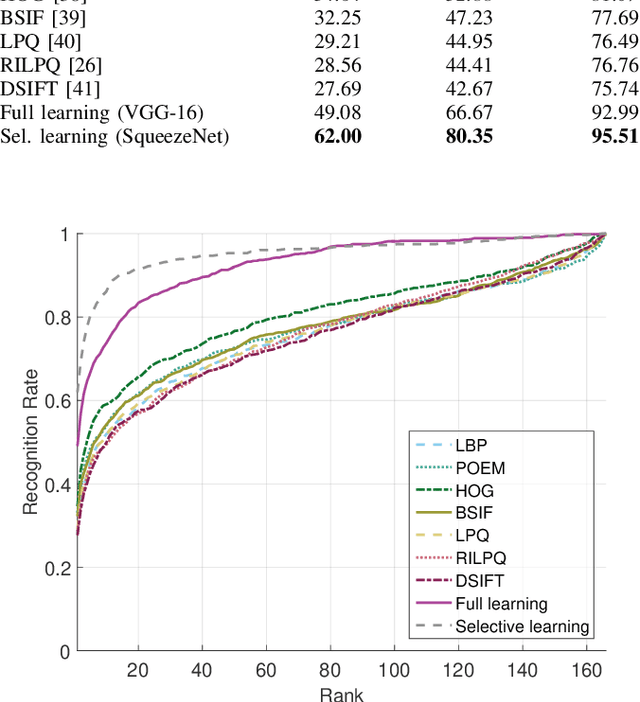
Identity recognition from ear images is an active field of research within the biometric community. The ability to capture ear images from a distance and in a covert manner makes ear recognition technology an appealing choice for surveillance and security applications as well as related application domains. In contrast to other biometric modalities, where large datasets captured in uncontrolled settings are readily available, datasets of ear images are still limited in size and mostly of laboratory-like quality. As a consequence, ear recognition technology has not benefited yet from advances in deep learning and convolutional neural networks (CNNs) and is still lacking behind other modalities that experienced significant performance gains owing to deep recognition technology. In this paper we address this problem and aim at building a CNNbased ear recognition model. We explore different strategies towards model training with limited amounts of training data and show that by selecting an appropriate model architecture, using aggressive data augmentation and selective learning on existing (pre-trained) models, we are able to learn an effective CNN-based model using a little more than 1300 training images. The result of our work is the first CNN-based approach to ear recognition that is also made publicly available to the research community. With our model we are able to improve on the rank one recognition rate of the previous state-of-the-art by more than 25% on a challenging dataset of ear images captured from the web (a.k.a. in the wild).