 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiCTI: Diffusion-based Clothing Designer via Text-guided Input
Jul 04, 2024


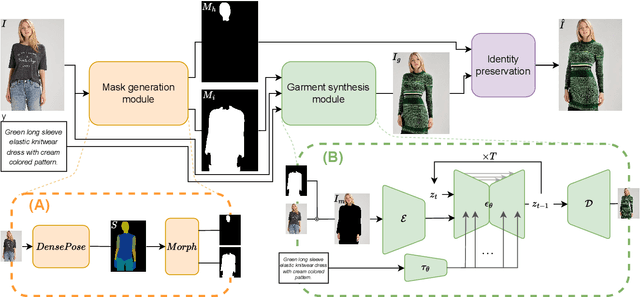
Recent developments in deep generative models have opened up a wide range of opportunities for image synthesis, leading to significant changes in various creative fields, including the fashion industry. While numerous methods have been proposed to benefit buyers, particularly in virtual try-on applications, there has been relatively less focus on facilitating fast prototyping for designers and customers seeking to order new designs. To address this gap, we introduce DiCTI (Diffusion-based Clothing Designer via Text-guided Input), a straightforward yet highly effective approach that allows designers to quickly visualize fashion-related ideas using text inputs only. Given an image of a person and a description of the desired garments as input, DiCTI automatically generates multiple high-resolution, photorealistic images that capture the expressed semantics. By leveraging a powerful diffusion-based inpainting model conditioned on text inputs, DiCTI is able to synthesize convincing, high-quality images with varied clothing designs that viably follow the provided text descriptions, while being able to process very diverse and challenging inputs, captured in completely unconstrained settings. We evaluate DiCTI in comprehensive experiments on two different datasets (VITON-HD and Fashionpedia) and in comparison to the state-of-the-art (SoTa). The results of our experiments show that DiCTI convincingly outperforms the SoTA competitor in generating higher quality images with more elaborate garments and superior text prompt adherence, both according to standard quantitative evaluation measures and human ratings, generated as part of a user study.
Body Segmentation Using Multi-task Learning
Dec 13, 2022Body segmentation is an important step in many computer vision problems involving human images and one of the key components that affects the performance of all downstream tasks. Several prior works have approached this problem using a multi-task model that exploits correlations between different tasks to improve segmentation performance. Based on the success of such solutions, we present in this paper a novel multi-task model for human segmentation/parsing that involves three tasks, i.e., (i) keypoint-based skeleton estimation, (ii) dense pose prediction, and (iii) human-body segmentation. The main idea behind the proposed Segmentation--Pose--DensePose model (or SPD for short) is to learn a better segmentation model by sharing knowledge across different, yet related tasks. SPD is based on a shared deep neural network backbone that branches off into three task-specific model heads and is learned using a multi-task optimization objective. The performance of the model is analysed through rigorous experiments on the LIP and ATR datasets and in comparison to a recent (state-of-the-art) multi-task body-segmentation model. Comprehensive ablation studies are also presented. Our experimental results show that the proposed multi-task (segmentation) model is highly competitive and that the introduction of additional tasks contributes towards a higher overall segmentation performance.
C-VTON: Context-Driven Image-Based Virtual Try-On Network
Dec 08, 2022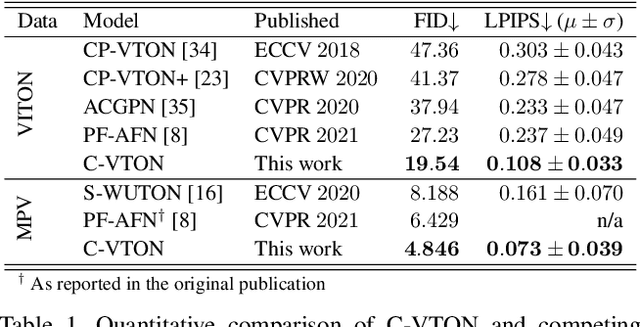
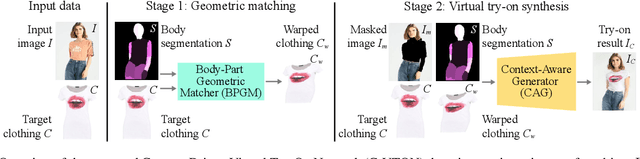
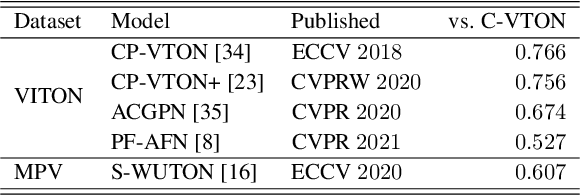
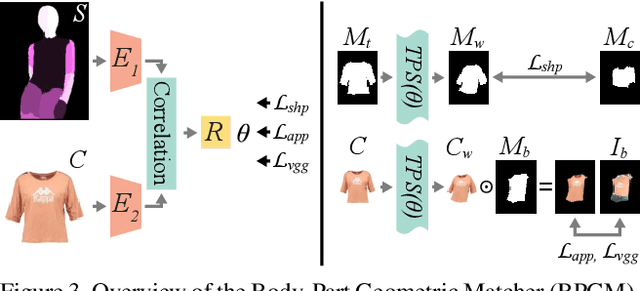
Image-based virtual try-on techniques have shown great promise for enhancing the user-experience and improving customer satisfaction on fashion-oriented e-commerce platforms. However, existing techniques are currently still limited in the quality of the try-on results they are able to produce from input images of diverse characteristics. In this work, we propose a Context-Driven Virtual Try-On Network (C-VTON) that addresses these limitations and convincingly transfers selected clothing items to the target subjects even under challenging pose configurations and in the presence of self-occlusions. At the core of the C-VTON pipeline are: (i) a geometric matching procedure that efficiently aligns the target clothing with the pose of the person in the input images, and (ii) a powerful image generator that utilizes various types of contextual information when synthesizing the final try-on result. C-VTON is evaluated in rigorous experiments on the VITON and MPV datasets and in comparison to state-of-the-art techniques from the literature. Experimental results show that the proposed approach is able to produce photo-realistic and visually convincing results and significantly improves on the existing state-of-the-art.