 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Large Multimodal Models Solve Caption Generation for Scientific Figures? Lessons Learned from SCICAP Challenge 2023
Paper and Code
Jan 31, 2025
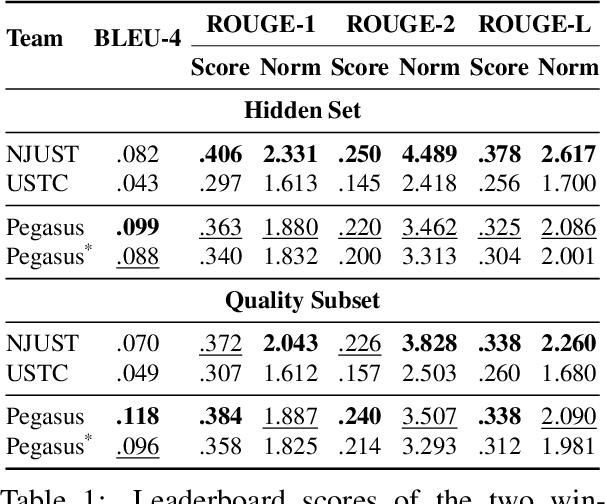
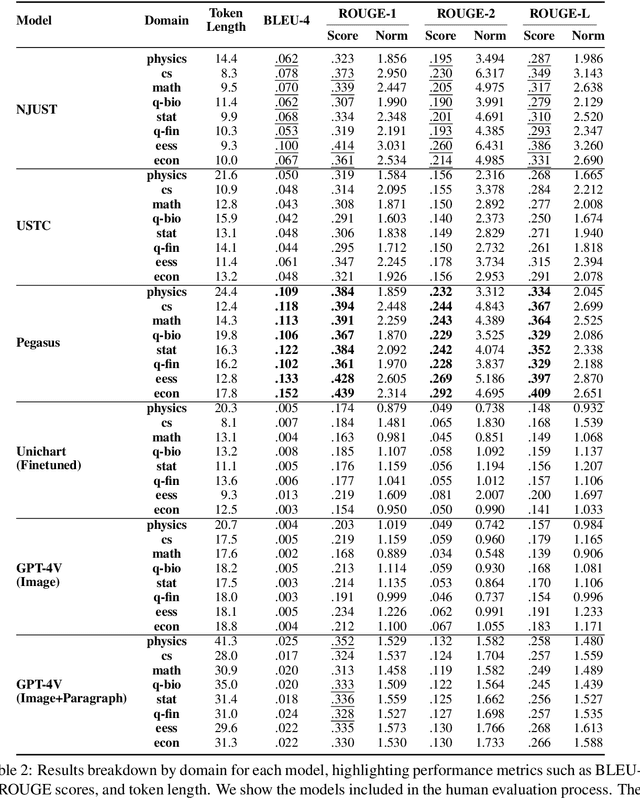
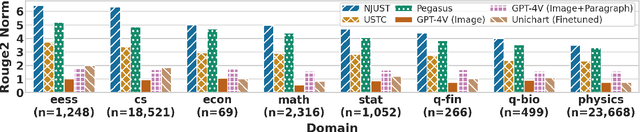
Since the SCICAP datasets launch in 2021, the research community has made significant progress in generating captions for scientific figures in scholarly articles. In 2023, the first SCICAP Challenge took place, inviting global teams to use an expanded SCICAP dataset to develop models for captioning diverse figure types across various academic fields. At the same time, text generation models advanced quickly, with many powerful pre-trained large multimodal models (LMMs) emerging that showed impressive capabilities in various vision-and-language tasks. This paper presents an overview of the first SCICAP Challenge and details the performance of various models on its data, capturing a snapshot of the fields state. We found that professional editors overwhelmingly preferred figure captions generated by GPT-4V over those from all other models and even the original captions written by authors. Following this key finding, we conducted detailed analyses to answer this question: Have advanced LMMs solved the task of generating captions for scientific figures?