 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFive Years of SciCap: What We Learned and Future Directions for Scientific Figure Captioning
Dec 25, 2025Between 2021 and 2025, the SciCap project grew from a small seed-funded idea at The Pennsylvania State University (Penn State) into one of the central efforts shaping the scientific figure-captioning landscape. Supported by a Penn State seed grant, Adobe, and the Alfred P. Sloan Foundation, what began as our attempt to test whether domain-specific training, which was successful in text models like SciBERT, could also work for figure captions expanded into a multi-institution collaboration. Over these five years, we curated, released, and continually updated a large collection of figure-caption pairs from arXiv papers, conducted extensive automatic and human evaluations on both generated and author-written captions, navigated the rapid rise of large language models (LLMs), launched annual challenges, and built interactive systems that help scientists write better captions. In this piece, we look back at the first five years of SciCap and summarize the key technical and methodological lessons we learned. We then outline five major unsolved challenges and propose directions for the next phase of research in scientific figure captioning.
Do Large Multimodal Models Solve Caption Generation for Scientific Figures? Lessons Learned from SCICAP Challenge 2023
Jan 31, 2025
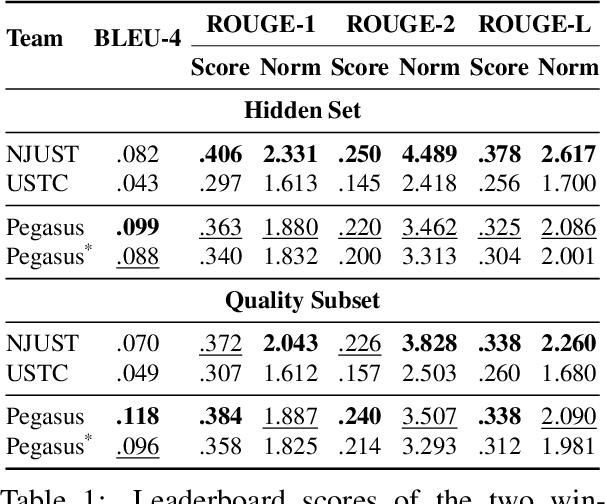
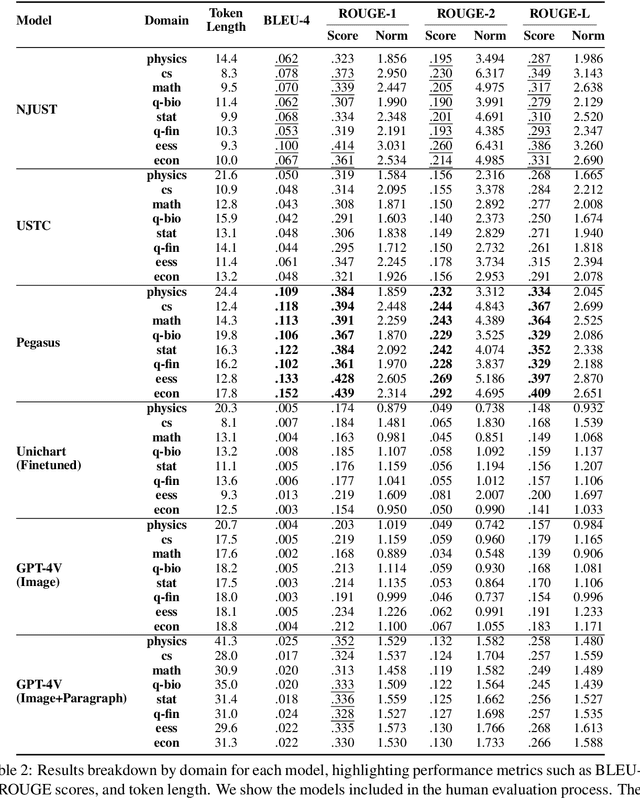
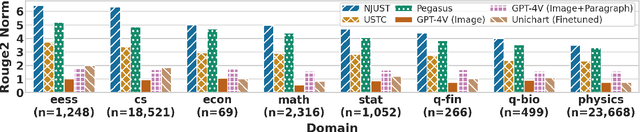
Since the SCICAP datasets launch in 2021, the research community has made significant progress in generating captions for scientific figures in scholarly articles. In 2023, the first SCICAP Challenge took place, inviting global teams to use an expanded SCICAP dataset to develop models for captioning diverse figure types across various academic fields. At the same time, text generation models advanced quickly, with many powerful pre-trained large multimodal models (LMMs) emerging that showed impressive capabilities in various vision-and-language tasks. This paper presents an overview of the first SCICAP Challenge and details the performance of various models on its data, capturing a snapshot of the fields state. We found that professional editors overwhelmingly preferred figure captions generated by GPT-4V over those from all other models and even the original captions written by authors. Following this key finding, we conducted detailed analyses to answer this question: Have advanced LMMs solved the task of generating captions for scientific figures?