 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Showcases: Generating Multi-Modal Explanations for Recommendations
Paper and Code

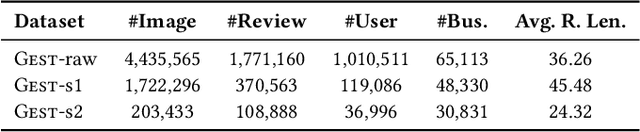

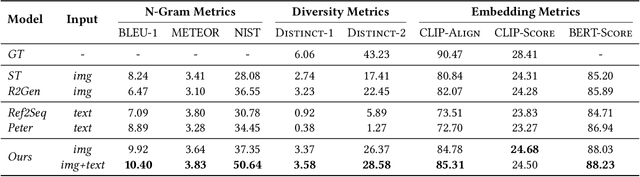
Existing explanation models generate only text for recommendations but still struggle to produce diverse contents. In this paper, to further enrich explanations, we propose a new task named personalized showcases, in which we provide both textual and visual information to explain our recommendations. Specifically, we first select a personalized image set that is the most relevant to a user's interest toward a recommended item. Then, natural language explanations are generated accordingly given our selected images. For this new task, we collect a large-scale dataset from Google Local (i.e.,~maps) and construct a high-quality subset for generating multi-modal explanations. We propose a personalized multi-modal framework which can generate diverse and visually-aligned explanations via contrastive learning. Experiments show that our framework benefits from different modalities as inputs, and is able to produce more diverse and expressive explanations compared to previous methods on a variety of evaluation metrics.