 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Large Language Models Are All-purpose Text Analytics Engines: Text-to-text Learning Is All Your Need
Dec 11, 2023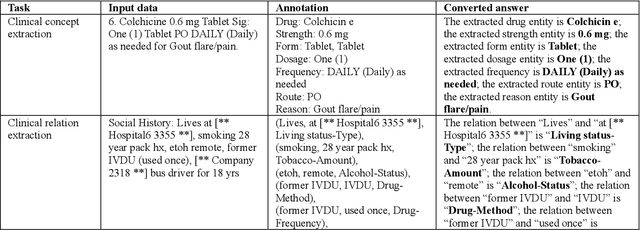
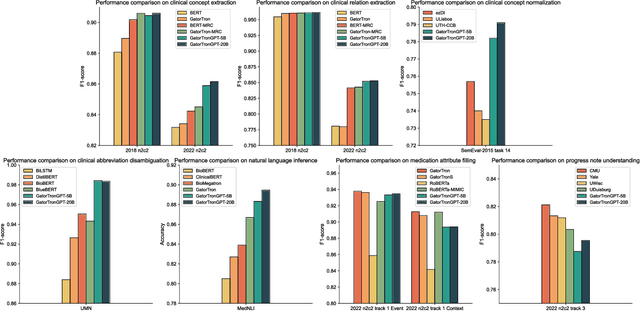
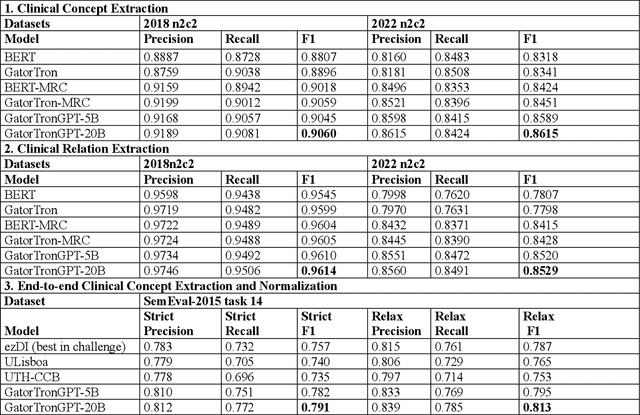

Objective To solve major clinical natural language processing (NLP) tasks using a unified text-to-text learning architecture based on a generative large language model (LLM) via prompt tuning. Methods We formulated 7 key clinical NLP tasks as text-to-text learning and solved them using one unified generative clinical LLM, GatorTronGPT, developed using GPT-3 architecture and trained with up to 20 billion parameters. We adopted soft prompts (i.e., trainable vectors) with frozen LLM, where the LLM parameters were not updated (i.e., frozen) and only the vectors of soft prompts were updated, known as prompt tuning. We added additional soft prompts as a prefix to the input layer, which were optimized during the prompt tuning. We evaluated the proposed method using 7 clinical NLP tasks and compared them with previous task-specific solutions based on Transformer models. Results and Conclusion The proposed approach achieved state-of-the-art performance for 5 out of 7 major clinical NLP tasks using one unified generative LLM. Our approach outperformed previous task-specific transformer models by ~3% for concept extraction and 7% for relation extraction applied to social determinants of health, 3.4% for clinical concept normalization, 3.4~10% for clinical abbreviation disambiguation, and 5.5~9% for natural language inference. Our approach also outperformed a previously developed prompt-based machine reading comprehension (MRC) model, GatorTron-MRC, for clinical concept and relation extraction. The proposed approach can deliver the ``one model for all`` promise from training to deployment using a unified generative LLM.
A Study of Generative Large Language Model for Medical Research and Healthcare
May 22, 2023There is enormous enthusiasm and concerns in using large language models (LLMs) in healthcare, yet current assumptions are all based on general-purpose LLMs such as ChatGPT. This study develops a clinical generative LLM, GatorTronGPT, using 277 billion words of mixed clinical and English text with a GPT-3 architecture of 20 billion parameters. GatorTronGPT improves biomedical natural language processing for medical research. Synthetic NLP models trained using GatorTronGPT generated text outperform NLP models trained using real-world clinical text. Physicians Turing test using 1 (worst) to 9 (best) scale shows that there is no significant difference in linguistic readability (p = 0.22; 6.57 of GatorTronGPT compared with 6.93 of human) and clinical relevance (p = 0.91; 7.0 of GatorTronGPT compared with 6.97 of human) and that physicians cannot differentiate them (p < 0.001). This study provides insights on the opportunities and challenges of LLMs for medical research and healthcare.
Deep Learning-Based Automatic Detection of Poorly Positioned Mammograms to Minimize Patient Return Visits for Repeat Imaging: A Real-World Application
Sep 28, 2020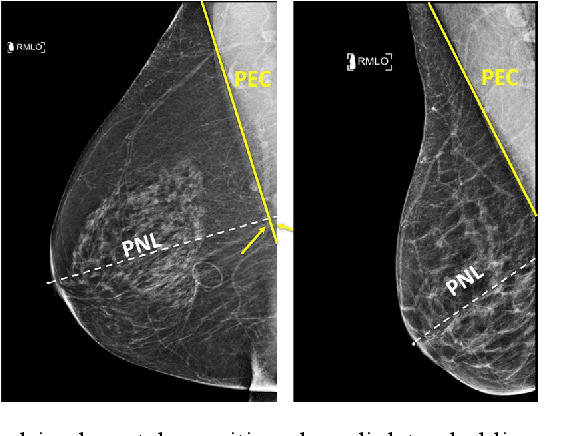
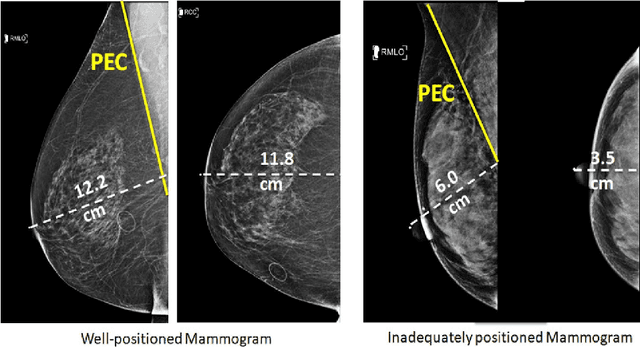
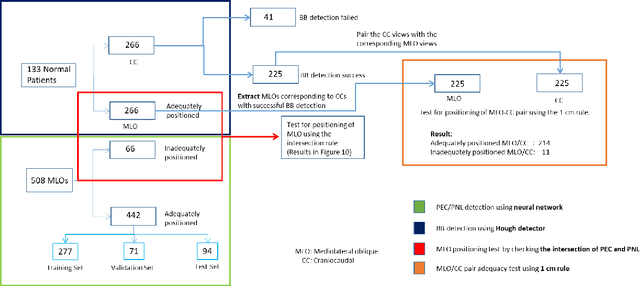
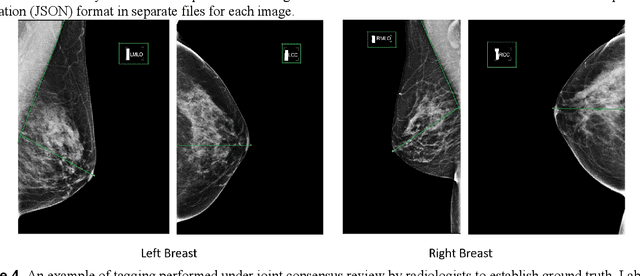
Screening mammograms are a routine imaging exam performed to detect breast cancer in its early stages to reduce morbidity and mortality attributed to this disease. In order to maximize the efficacy of breast cancer screening programs, proper mammographic positioning is paramount. Proper positioning ensures adequate visualization of breast tissue and is necessary for effective breast cancer detection. Therefore, breast-imaging radiologists must assess each mammogram for the adequacy of positioning before providing a final interpretation of the examination; this often necessitates return patient visits for additional imaging. In this paper, we propose a deep learning-algorithm method that mimics and automates this decision-making process to identify poorly positioned mammograms. Our objective for this algorithm is to assist mammography technologists in recognizing inadequately positioned mammograms real-time, improve the quality of mammographic positioning and performance, and ultimately reducing repeat visits for patients with initially inadequate imaging. The proposed model showed a true positive rate for detecting correct positioning of 91.35% in the mediolateral oblique view and 95.11% in the craniocaudal view. In addition to these results, we also present an automatically generated report which can aid the mammography technologist in taking corrective measures during the patient visit.