 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Deep Neural Networks Using Posit Number System
Paper and Code
Sep 06, 2019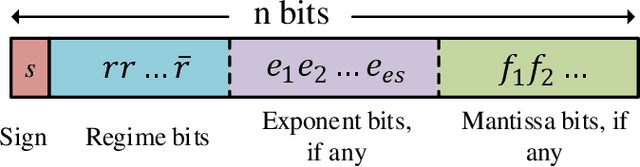
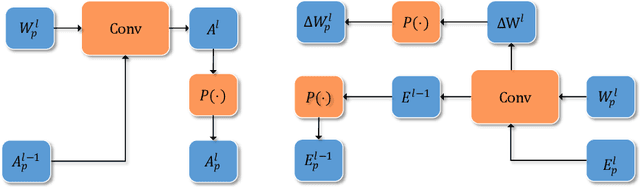
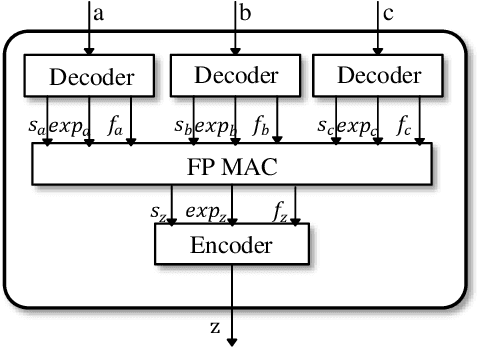
With the increasing size of Deep Neural Network (DNN) models, the high memory space requirements and computational complexity have become an obstacle for efficient DNN implementations. To ease this problem, using reduced-precision representations for DNN training and inference has attracted many interests from researchers. This paper first proposes a methodology for training DNNs with the posit arithmetic, a type- 3 universal number (Unum) format that is similar to the floating point(FP) but has reduced precision. A warm-up training strategy and layer-wise scaling factors are adopted to stabilize training and fit the dynamic range of DNN parameters. With the proposed training methodology, we demonstrate the first successful training of DNN models on ImageNet image classification task in 16 bits posit with no accuracy loss. Then, an efficient hardware architecture for the posit multiply-and-accumulate operation is also proposed, which can achieve significant improvement in energy efficiency than traditional floating-point implementations. The proposed design is helpful for future low-power DNN training accelerators.