 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeEdit: A Dataset, Benchmark and Glyph-Guided Framework for Text-centric Image Editing
Mar 12, 2026Instruction-based image editing aims to modify specific content within existing images according to user-provided instructions while preserving non-target regions. Beyond traditional object- and style-centric manipulation, text-centric image editing focuses on modifying, translating, or rearranging textual elements embedded within images. However, existing leading models often struggle to execute complex text editing precisely, frequently producing blurry or hallucinated characters. We attribute these failures primarily to the lack of specialized training paradigms tailored for text-centric editing, as well as the absence of large-scale datasets and standardized benchmarks necessary for a closed-loop training and evaluation system. To address these limitations, we present WeEdit, a systematic solution encompassing a scalable data construction pipeline, two benchmarks, and a tailored two-stage training strategy. Specifically, we propose a novel HTML-based automatic editing pipeline, which generates 330K training pairs covering diverse editing operations and 15 languages, accompanied by standardized bilingual and multilingual benchmarks for comprehensive evaluation. On the algorithmic side, we employ glyph-guided supervised fine-tuning to inject explicit spatial and content priors, followed by a multi-objective reinforcement learning stage to align generation with instruction adherence, text clarity, and background preservation. Extensive experiments demonstrate that WeEdit outperforms previous open-source models by a clear margin across diverse editing operations.
ArrowGEV: Grounding Events in Video via Learning the Arrow of Time
Jan 10, 2026Grounding events in videos serves as a fundamental capability in video analysis. While Vision-Language Models (VLMs) are increasingly employed for this task, existing approaches predominantly train models to associate events with timestamps in the forward video only. This paradigm hinders VLMs from capturing the inherent temporal structure and directionality of events, thereby limiting robustness and generalization. To address this limitation, inspired by the arrow of time in physics, which characterizes the intrinsic directionality of temporal processes, we propose ArrowGEV, a reinforcement learning framework that explicitly models temporal directionality in events to improve both event grounding and temporal directionality understanding in VLMs. Specifically, we categorize events into time-sensitive (e.g., putting down a bag) and time-insensitive (e.g., holding a towel in the left hand). The former denote events whose reversal substantially alters their meaning, while the latter remain semantically unchanged under reversal. For time-sensitive events, ArrowGEV introduces a reward that encourages VLMs to discriminate between forward and backward videos, whereas for time-insensitive events, it enforces consistent grounding across both directions. Extensive experiments demonstrate that ArrowGEV not only improves grounding precision and temporal directionality recognition, but also enhances general video understanding and reasoning ability.
LaCo: Efficient Layer-wise Compression of Visual Tokens for Multimodal Large Language Models
Jul 03, 2025



Existing visual token compression methods for Multimodal Large Language Models (MLLMs) predominantly operate as post-encoder modules, limiting their potential for efficiency gains. To address this limitation, we propose LaCo (Layer-wise Visual Token Compression), a novel framework that enables effective token compression within the intermediate layers of the vision encoder. LaCo introduces two core components: 1) a layer-wise pixel-shuffle mechanism that systematically merges adjacent tokens through space-to-channel transformations, and 2) a residual learning architecture with non-parametric shortcuts that preserves critical visual information during compression. Extensive experiments indicate that our LaCo outperforms all existing methods when compressing tokens in the intermediate layers of the vision encoder, demonstrating superior effectiveness. In addition, compared to external compression, our method improves training efficiency beyond 20% and inference throughput over 15% while maintaining strong performance.
D2C: Unlocking the Potential of Continuous Autoregressive Image Generation with Discrete Tokens
Mar 21, 2025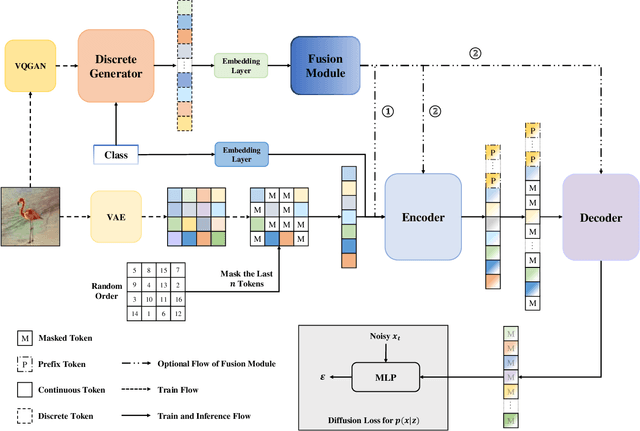
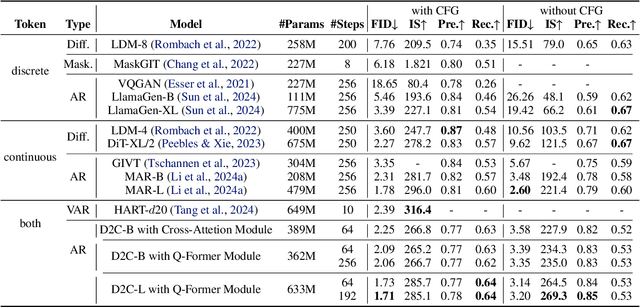
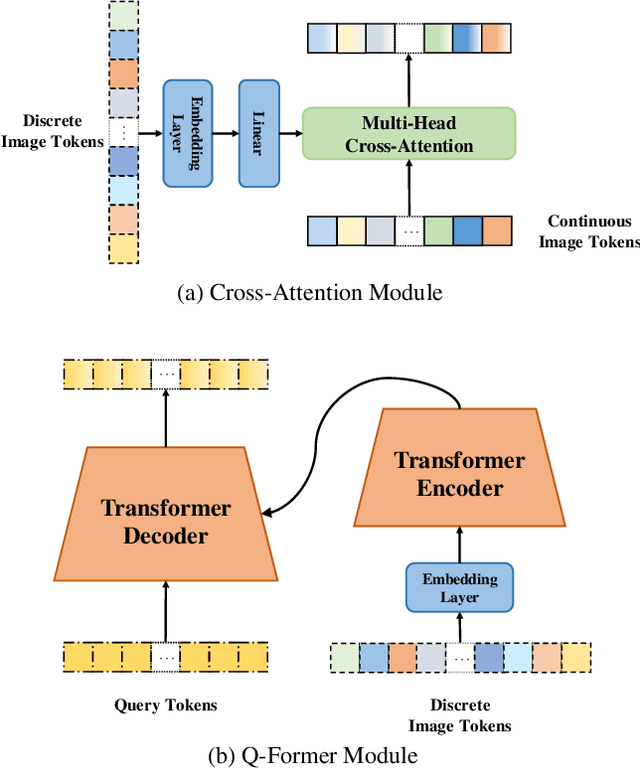
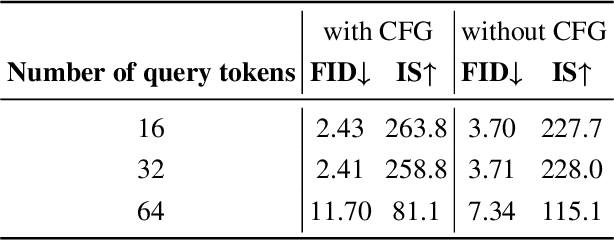
In the domain of image generation, latent-based generative models occupy a dominant status; however, these models rely heavily on image tokenizer. To meet modeling requirements, autoregressive models possessing the characteristics of scalability and flexibility embrace a discrete-valued tokenizer, but face the challenge of poor image generation quality. In contrast, diffusion models take advantage of the continuous-valued tokenizer to achieve better generation quality but are subject to low efficiency and complexity. The existing hybrid models are mainly to compensate for information loss and simplify the diffusion learning process. The potential of merging discrete-valued and continuous-valued tokens in the field of image generation has not yet been explored. In this paper, we propose D2C, a novel two-stage method to enhance model generation capacity. In the first stage, the discrete-valued tokens representing coarse-grained image features are sampled by employing a small discrete-valued generator. Then in the second stage, the continuous-valued tokens representing fine-grained image features are learned conditioned on the discrete token sequence. In addition, we design two kinds of fusion modules for seamless interaction. On the ImageNet-256 benchmark, extensive experiment results validate that our model achieves superior performance compared with several continuous-valued and discrete-valued generative models on the class-conditional image generation tasks.
LLaVE: Large Language and Vision Embedding Models with Hardness-Weighted Contrastive Learning
Mar 04, 2025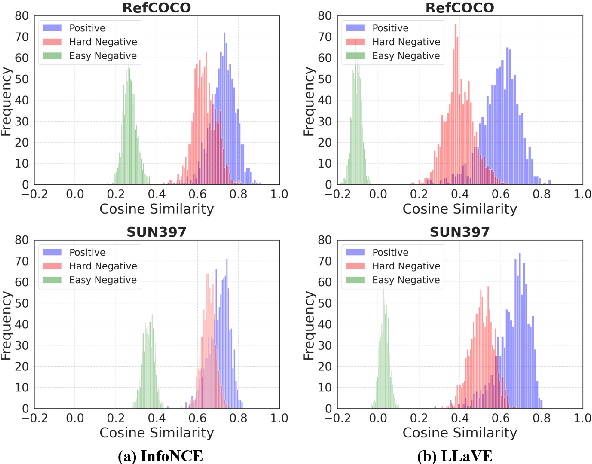
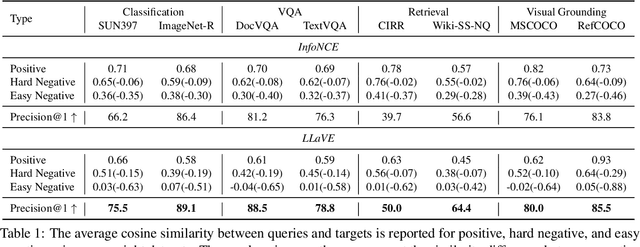
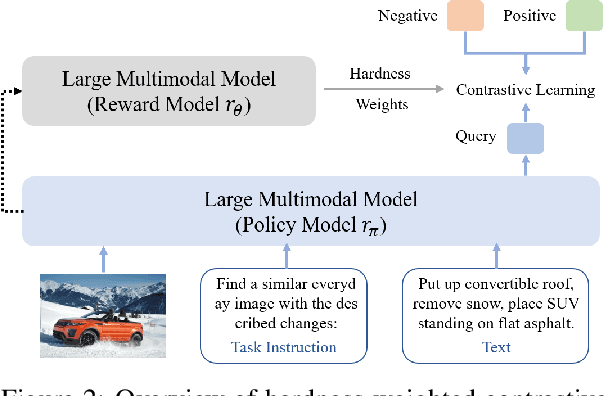
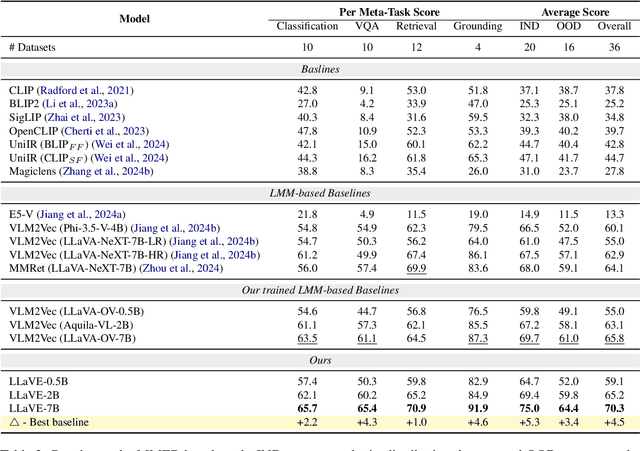
Universal multimodal embedding models play a critical role in tasks such as interleaved image-text retrieval, multimodal RAG, and multimodal clustering. However, our empirical results indicate that existing LMM-based embedding models trained with the standard InfoNCE loss exhibit a high degree of overlap in similarity distribution between positive and negative pairs, making it challenging to distinguish hard negative pairs effectively. To deal with this issue, we propose a simple yet effective framework that dynamically improves the embedding model's representation learning for negative pairs based on their discriminative difficulty. Within this framework, we train a series of models, named LLaVE, and evaluate them on the MMEB benchmark, which covers 4 meta-tasks and 36 datasets. Experimental results show that LLaVE establishes stronger baselines that achieve state-of-the-art (SOTA) performance while demonstrating strong scalability and efficiency. Specifically, LLaVE-2B surpasses the previous SOTA 7B models, while LLaVE-7B achieves a further performance improvement of 6.2 points. Although LLaVE is trained on image-text data, it can generalize to text-video retrieval tasks in a zero-shot manner and achieve strong performance, demonstrating its remarkable potential for transfer to other embedding tasks.
MaskMamba: A Hybrid Mamba-Transformer Model for Masked Image Generation
Sep 30, 2024



Image generation models have encountered challenges related to scalability and quadratic complexity, primarily due to the reliance on Transformer-based backbones. In this study, we introduce MaskMamba, a novel hybrid model that combines Mamba and Transformer architectures, utilizing Masked Image Modeling for non-autoregressive image synthesis. We meticulously redesign the bidirectional Mamba architecture by implementing two key modifications: (1) replacing causal convolutions with standard convolutions to better capture global context, and (2) utilizing concatenation instead of multiplication, which significantly boosts performance while accelerating inference speed. Additionally, we explore various hybrid schemes of MaskMamba, including both serial and grouped parallel arrangements. Furthermore, we incorporate an in-context condition that allows our model to perform both class-to-image and text-to-image generation tasks. Our MaskMamba outperforms Mamba-based and Transformer-based models in generation quality. Notably, it achieves a remarkable $54.44\%$ improvement in inference speed at a resolution of $2048\times 2048$ over Transformer.
Translatotron-V(ison): An End-to-End Model for In-Image Machine Translation
Jul 03, 2024In-image machine translation (IIMT) aims to translate an image containing texts in source language into an image containing translations in target language. In this regard, conventional cascaded methods suffer from issues such as error propagation, massive parameters, and difficulties in deployment and retaining visual characteristics of the input image. Thus, constructing end-to-end models has become an option, which, however, faces two main challenges: 1) the huge modeling burden, as it is required to simultaneously learn alignment across languages and preserve the visual characteristics of the input image; 2) the difficulties of directly predicting excessively lengthy pixel sequences. In this paper, we propose \textit{Translatotron-V(ision)}, an end-to-end IIMT model consisting of four modules. In addition to an image encoder, and an image decoder, our model contains a target text decoder and an image tokenizer. Among them, the target text decoder is used to alleviate the language alignment burden, and the image tokenizer converts long sequences of pixels into shorter sequences of visual tokens, preventing the model from focusing on low-level visual features. Besides, we present a two-stage training framework for our model to assist the model in learning alignment across modalities and languages. Finally, we propose a location-aware evaluation metric called Structure-BLEU to assess the translation quality of the generated images. Experimental results demonstrate that our model achieves competitive performance compared to cascaded models with only 70.9\% of parameters, and significantly outperforms the pixel-level end-to-end IIMT model.
WeLayout: WeChat Layout Analysis System for the ICDAR 2023 Competition on Robust Layout Segmentation in Corporate Documents
May 11, 2023



In this paper, we introduce WeLayout, a novel system for segmenting the layout of corporate documents, which stands for WeChat Layout Analysis System. Our approach utilizes a sophisticated ensemble of DINO and YOLO models, specifically developed for the ICDAR 2023 Competition on Robust Layout Segmentation. Our method significantly surpasses the baseline, securing a top position on the leaderboard with a mAP of 70.0. To achieve this performance, we concentrated on enhancing various aspects of the task, such as dataset augmentation, model architecture, bounding box refinement, and model ensemble techniques. Additionally, we trained the data separately for each document category to ensure a higher mean submission score. We also developed an algorithm for cell matching to further improve our performance. To identify the optimal weights and IoU thresholds for our model ensemble, we employed a Bayesian optimization algorithm called the Tree-Structured Parzen Estimator. Our approach effectively demonstrates the benefits of combining query-based and anchor-free models for achieving robust layout segmentation in corporate documents.