 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD2C: Unlocking the Potential of Continuous Autoregressive Image Generation with Discrete Tokens
Paper and Code
Mar 21, 2025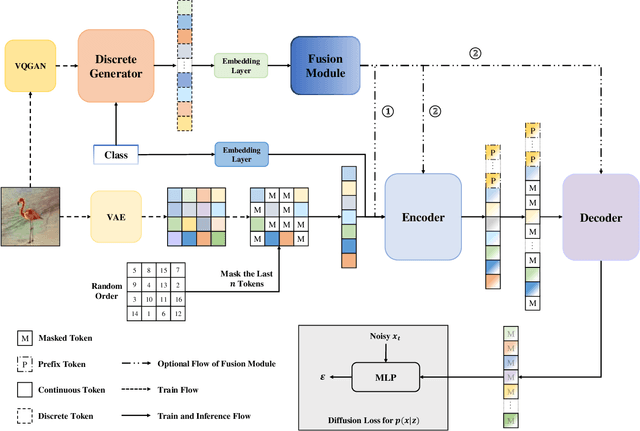
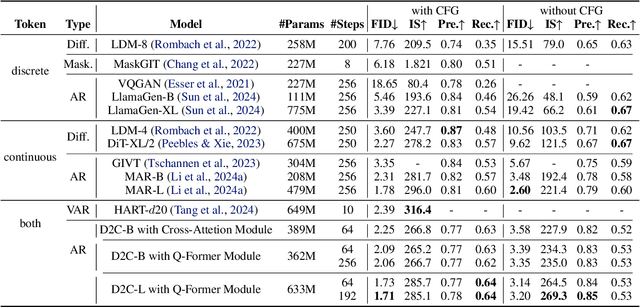
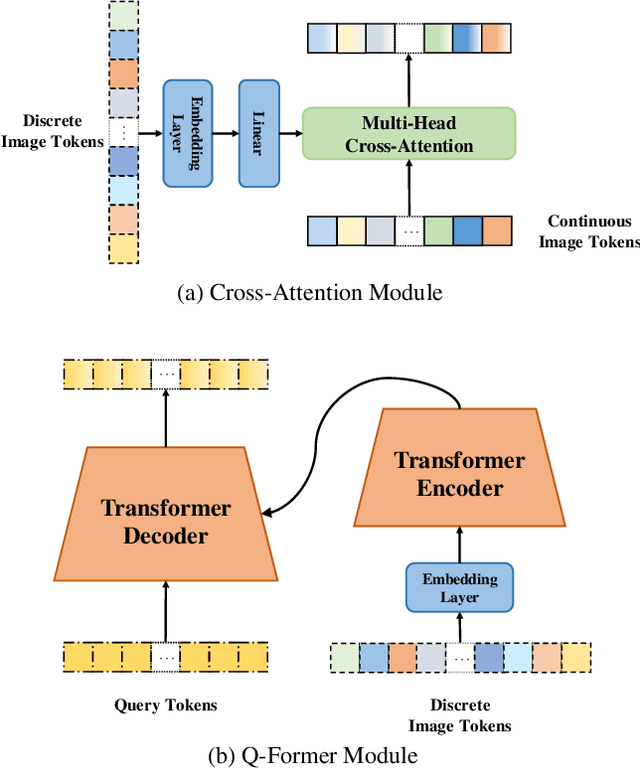
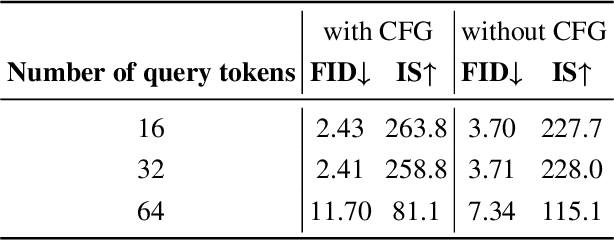
In the domain of image generation, latent-based generative models occupy a dominant status; however, these models rely heavily on image tokenizer. To meet modeling requirements, autoregressive models possessing the characteristics of scalability and flexibility embrace a discrete-valued tokenizer, but face the challenge of poor image generation quality. In contrast, diffusion models take advantage of the continuous-valued tokenizer to achieve better generation quality but are subject to low efficiency and complexity. The existing hybrid models are mainly to compensate for information loss and simplify the diffusion learning process. The potential of merging discrete-valued and continuous-valued tokens in the field of image generation has not yet been explored. In this paper, we propose D2C, a novel two-stage method to enhance model generation capacity. In the first stage, the discrete-valued tokens representing coarse-grained image features are sampled by employing a small discrete-valued generator. Then in the second stage, the continuous-valued tokens representing fine-grained image features are learned conditioned on the discrete token sequence. In addition, we design two kinds of fusion modules for seamless interaction. On the ImageNet-256 benchmark, extensive experiment results validate that our model achieves superior performance compared with several continuous-valued and discrete-valued generative models on the class-conditional image generation tasks.