 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Backbone Models for Visual Text Generation with Input Granularity Control and Glyph-Aware Training
Paper and Code
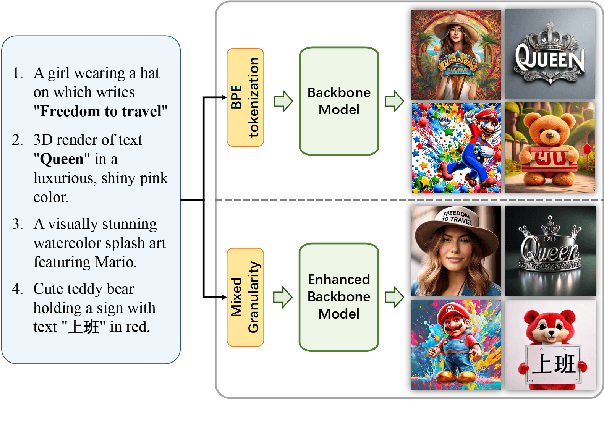
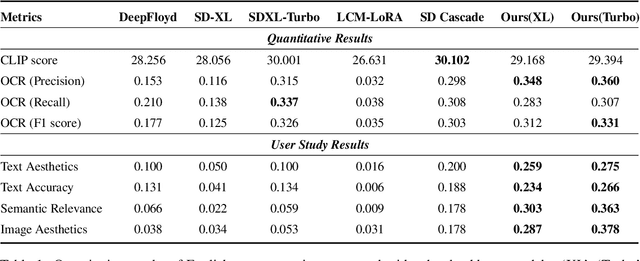
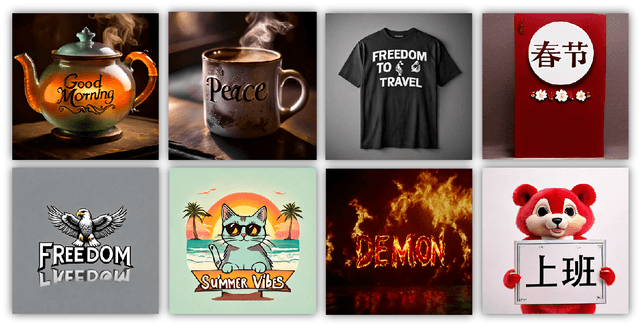

Diffusion-based text-to-image models have demonstrated impressive achievements in diversity and aesthetics but struggle to generate images with legible visual texts. Existing backbone models have limitations such as misspelling, failing to generate texts, and lack of support for Chinese text, but their development shows promising potential. In this paper, we propose a series of methods, aiming to empower backbone models to generate visual texts in English and Chinese. We first conduct a preliminary study revealing that Byte Pair Encoding (BPE) tokenization and the insufficient learning of cross-attention modules restrict the performance of the backbone models. Based on these observations, we make the following improvements: (1) We design a mixed granularity input strategy to provide more suitable text representations; (2) We propose to augment the conventional training objective with three glyph-aware training losses, which enhance the learning of cross-attention modules and encourage the model to focus on visual texts. Through experiments, we demonstrate that our methods can effectively empower backbone models to generate semantic relevant, aesthetically appealing, and accurate visual text images, while maintaining their fundamental image generation quality.