 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK2-Think: A Parameter-Efficient Reasoning System
Sep 09, 2025K2-Think is a reasoning system that achieves state-of-the-art performance with a 32B parameter model, matching or surpassing much larger models like GPT-OSS 120B and DeepSeek v3.1. Built on the Qwen2.5 base model, our system shows that smaller models can compete at the highest levels by combining advanced post-training and test-time computation techniques. The approach is based on six key technical pillars: Long Chain-of-thought Supervised Finetuning, Reinforcement Learning with Verifiable Rewards (RLVR), Agentic planning prior to reasoning, Test-time Scaling, Speculative Decoding, and Inference-optimized Hardware, all using publicly available open-source datasets. K2-Think excels in mathematical reasoning, achieving state-of-the-art scores on public benchmarks for open-source models, while also performing strongly in other areas such as Code and Science. Our results confirm that a more parameter-efficient model like K2-Think 32B can compete with state-of-the-art systems through an integrated post-training recipe that includes long chain-of-thought training and strategic inference-time enhancements, making open-source reasoning systems more accessible and affordable. K2-Think is freely available at k2think.ai, offering best-in-class inference speeds of over 2,000 tokens per second per request via the Cerebras Wafer-Scale Engine.
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
Jun 17, 2025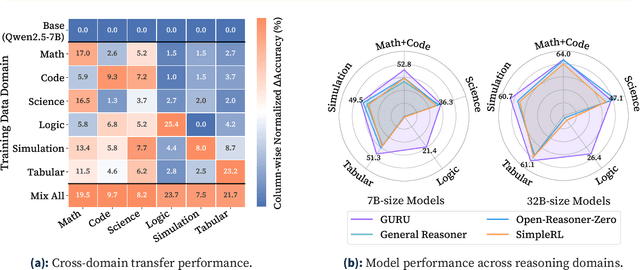
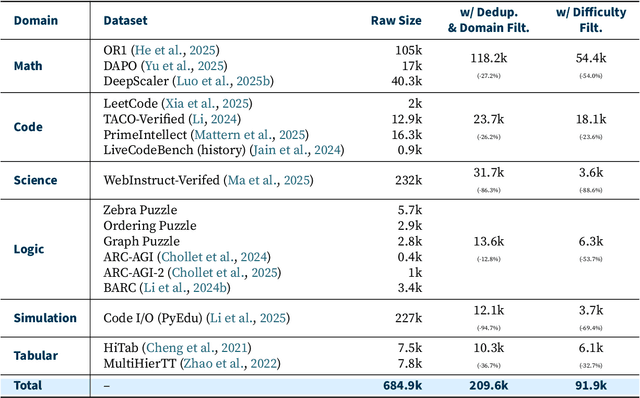
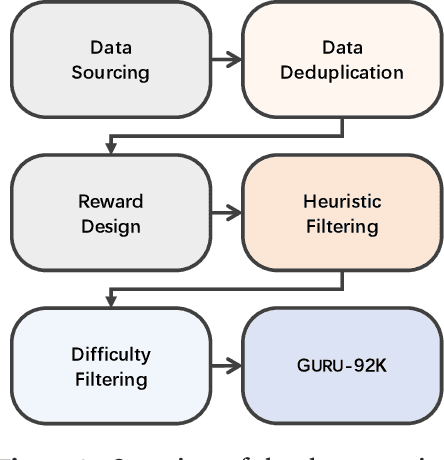

Reinforcement learning (RL) has emerged as a promising approach to improve large language model (LLM) reasoning, yet most open efforts focus narrowly on math and code, limiting our understanding of its broader applicability to general reasoning. A key challenge lies in the lack of reliable, scalable RL reward signals across diverse reasoning domains. We introduce Guru, a curated RL reasoning corpus of 92K verifiable examples spanning six reasoning domains--Math, Code, Science, Logic, Simulation, and Tabular--each built through domain-specific reward design, deduplication, and filtering to ensure reliability and effectiveness for RL training. Based on Guru, we systematically revisit established findings in RL for LLM reasoning and observe significant variation across domains. For example, while prior work suggests that RL primarily elicits existing knowledge from pretrained models, our results reveal a more nuanced pattern: domains frequently seen during pretraining (Math, Code, Science) easily benefit from cross-domain RL training, while domains with limited pretraining exposure (Logic, Simulation, and Tabular) require in-domain training to achieve meaningful performance gains, suggesting that RL is likely to facilitate genuine skill acquisition. Finally, we present Guru-7B and Guru-32B, two models that achieve state-of-the-art performance among open models RL-trained with publicly available data, outperforming best baselines by 7.9% and 6.7% on our 17-task evaluation suite across six reasoning domains. We also show that our models effectively improve the Pass@k performance of their base models, particularly on complex tasks less likely to appear in pretraining data. We release data, models, training and evaluation code to facilitate general-purpose reasoning at: https://github.com/LLM360/Reasoning360
Hard-Thresholding Meets Evolution Strategies in Reinforcement Learning
May 02, 2024



Evolution Strategies (ES) have emerged as a competitive alternative for model-free reinforcement learning, showcasing exemplary performance in tasks like Mujoco and Atari. Notably, they shine in scenarios with imperfect reward functions, making them invaluable for real-world applications where dense reward signals may be elusive. Yet, an inherent assumption in ES, that all input features are task-relevant, poses challenges, especially when confronted with irrelevant features common in real-world problems. This work scrutinizes this limitation, particularly focusing on the Natural Evolution Strategies (NES) variant. We propose NESHT, a novel approach that integrates Hard-Thresholding (HT) with NES to champion sparsity, ensuring only pertinent features are employed. Backed by rigorous analysis and empirical tests, NESHT demonstrates its promise in mitigating the pitfalls of irrelevant features and shines in complex decision-making problems like noisy Mujoco and Atari tasks.
Robust Offline Reinforcement Learning with Gradient Penalty and Constraint Relaxation
Oct 19, 2022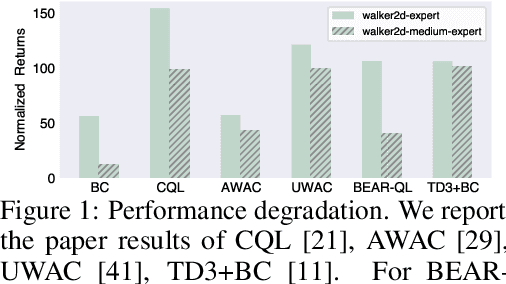


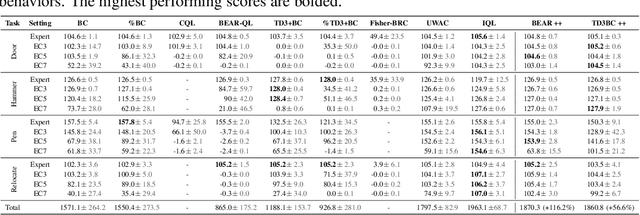
A promising paradigm for offline reinforcement learning (RL) is to constrain the learned policy to stay close to the dataset behaviors, known as policy constraint offline RL. However, existing works heavily rely on the purity of the data, exhibiting performance degradation or even catastrophic failure when learning from contaminated datasets containing impure trajectories of diverse levels. e.g., expert level, medium level, etc., while offline contaminated data logs exist commonly in the real world. To mitigate this, we first introduce gradient penalty over the learned value function to tackle the exploding Q-functions. We then relax the closeness constraints towards non-optimal actions with critic weighted constraint relaxation. Experimental results show that the proposed techniques effectively tame the non-optimal trajectories for policy constraint offline RL methods, evaluated on a set of contaminated D4RL Mujoco and Adroit datasets.
Value Penalized Q-Learning for Recommender Systems
Oct 15, 2021
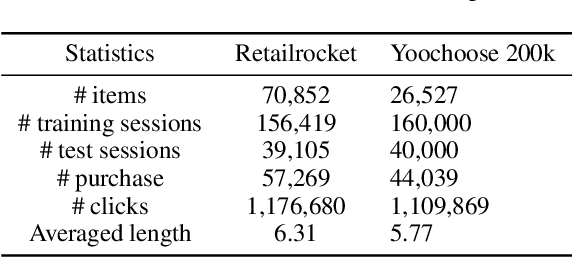

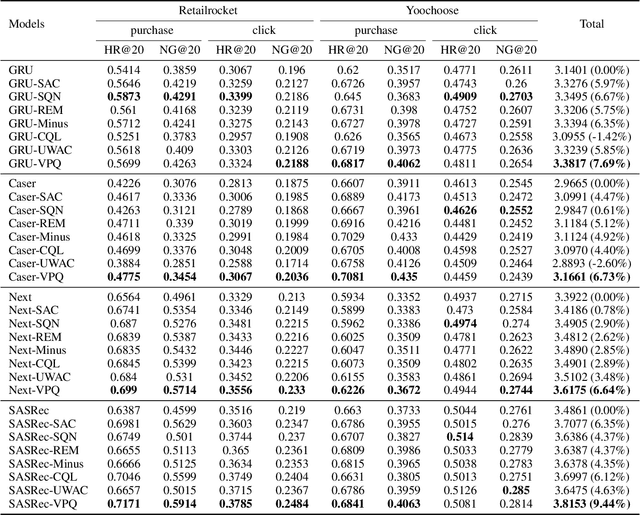
Scaling reinforcement learning (RL) to recommender systems (RS) is promising since maximizing the expected cumulative rewards for RL agents meets the objective of RS, i.e., improving customers' long-term satisfaction. A key approach to this goal is offline RL, which aims to learn policies from logged data. However, the high-dimensional action space and the non-stationary dynamics in commercial RS intensify distributional shift issues, making it challenging to apply offline RL methods to RS. To alleviate the action distribution shift problem in extracting RL policy from static trajectories, we propose Value Penalized Q-learning (VPQ), an uncertainty-based offline RL algorithm. It penalizes the unstable Q-values in the regression target by uncertainty-aware weights, without the need to estimate the behavior policy, suitable for RS with a large number of items. We derive the penalty weights from the variances across an ensemble of Q-functions. To alleviate distributional shift issues at test time, we further introduce the critic framework to integrate the proposed method with classic RS models. Extensive experiments conducted on two real-world datasets show that the proposed method could serve as a gain plugin for existing RS models.