 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Offline Reinforcement Learning with Gradient Penalty and Constraint Relaxation
Paper and Code
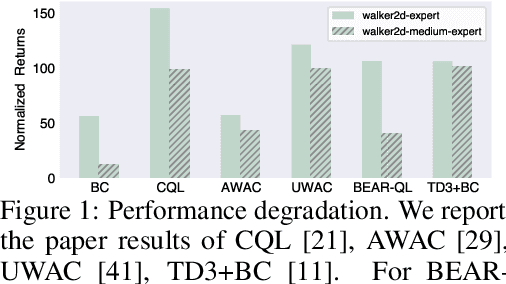


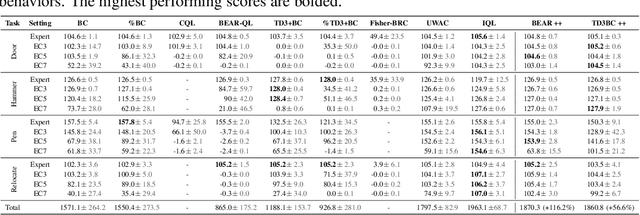
A promising paradigm for offline reinforcement learning (RL) is to constrain the learned policy to stay close to the dataset behaviors, known as policy constraint offline RL. However, existing works heavily rely on the purity of the data, exhibiting performance degradation or even catastrophic failure when learning from contaminated datasets containing impure trajectories of diverse levels. e.g., expert level, medium level, etc., while offline contaminated data logs exist commonly in the real world. To mitigate this, we first introduce gradient penalty over the learned value function to tackle the exploding Q-functions. We then relax the closeness constraints towards non-optimal actions with critic weighted constraint relaxation. Experimental results show that the proposed techniques effectively tame the non-optimal trajectories for policy constraint offline RL methods, evaluated on a set of contaminated D4RL Mujoco and Adroit datasets.