 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartAB: A Benchmark for Chart Grounding & Dense Alignment
Oct 30, 2025Charts play an important role in visualization, reasoning, data analysis, and the exchange of ideas among humans. However, existing vision-language models (VLMs) still lack accurate perception of details and struggle to extract fine-grained structures from charts. Such limitations in chart grounding also hinder their ability to compare multiple charts and reason over them. In this paper, we introduce a novel "ChartAlign Benchmark (ChartAB)" to provide a comprehensive evaluation of VLMs in chart grounding tasks, i.e., extracting tabular data, localizing visualization elements, and recognizing various attributes from charts of diverse types and complexities. We design a JSON template to facilitate the calculation of evaluation metrics specifically tailored for each grounding task. By incorporating a novel two-stage inference workflow, the benchmark can further evaluate VLMs' capability to align and compare elements/attributes across two charts. Our analysis of evaluations on several recent VLMs reveals new insights into their perception biases, weaknesses, robustness, and hallucinations in chart understanding. These findings highlight the fine-grained discrepancies among VLMs in chart understanding tasks and point to specific skills that need to be strengthened in current models.
OPTune: Efficient Online Preference Tuning
Jun 11, 2024
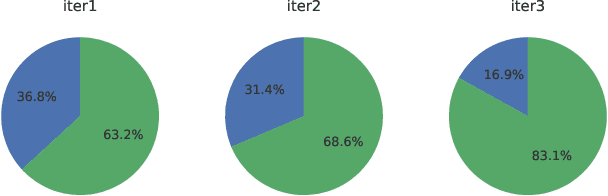

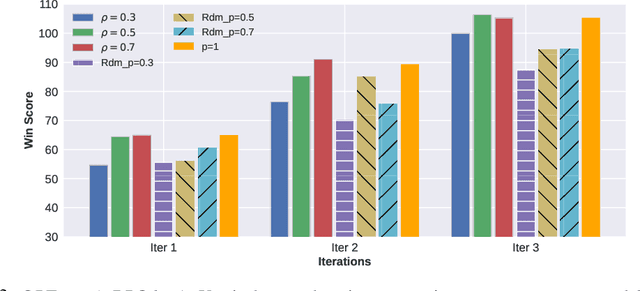
Reinforcement learning with human feedback~(RLHF) is critical for aligning Large Language Models (LLMs) with human preference. Compared to the widely studied offline version of RLHF, \emph{e.g.} direct preference optimization (DPO), recent works have shown that the online variants achieve even better alignment. However, online alignment requires on-the-fly generation of new training data, which is costly, hard to parallelize, and suffers from varying quality and utility. In this paper, we propose a more efficient data exploration strategy for online preference tuning (OPTune), which does not rely on human-curated or pre-collected teacher responses but dynamically samples informative responses for on-policy preference alignment. During data generation, OPTune only selects prompts whose (re)generated responses can potentially provide more informative and higher-quality training signals than the existing responses. In the training objective, OPTune reweights each generated response (pair) by its utility in improving the alignment so that learning can be focused on the most helpful samples. Throughout our evaluations, OPTune'd LLMs maintain the instruction-following benefits provided by standard preference tuning whilst enjoying 1.27-1.56x faster training speed due to the efficient data exploration strategy.
ODIN: Disentangled Reward Mitigates Hacking in RLHF
Feb 11, 2024In this work, we study the issue of reward hacking on the response length, a challenge emerging in Reinforcement Learning from Human Feedback (RLHF) on LLMs. A well-formatted, verbose but less helpful response from the LLMs can often deceive LLMs or even human evaluators to achieve high scores. The same issue also holds for some reward models in RL. To address the challenges in both training and evaluation, we establish a more reliable evaluation protocol for comparing different training configurations, which inspects the trade-off between LLM evaluation score and response length obtained by varying training hyperparameters. Based on this evaluation, we conduct large-scale studies, where the results shed insights into the efficacy of hyperparameters and tricks used in RL on mitigating length bias. We further propose to improve the reward model by jointly training two linear heads on shared feature representations to predict the rewards, one trained to correlate with length, and the other trained to decorrelate with length and therefore focus more on the actual content. We then discard the length head in RL to prevent reward hacking on length. Experiments demonstrate that our approach almost eliminates the reward correlation with length, and improves the obtained policy by a significant margin.
Reviving Shift Equivariance in Vision Transformers
Jun 13, 2023



Shift equivariance is a fundamental principle that governs how we perceive the world - our recognition of an object remains invariant with respect to shifts. Transformers have gained immense popularity due to their effectiveness in both language and vision tasks. While the self-attention operator in vision transformers (ViT) is permutation-equivariant and thus shift-equivariant, patch embedding, positional encoding, and subsampled attention in ViT variants can disrupt this property, resulting in inconsistent predictions even under small shift perturbations. Although there is a growing trend in incorporating the inductive bias of convolutional neural networks (CNNs) into vision transformers, it does not fully address the issue. We propose an adaptive polyphase anchoring algorithm that can be seamlessly integrated into vision transformer models to ensure shift-equivariance in patch embedding and subsampled attention modules, such as window attention and global subsampled attention. Furthermore, we utilize depth-wise convolution to encode positional information. Our algorithms enable ViT, and its variants such as Twins to achieve 100% consistency with respect to input shift, demonstrate robustness to cropping, flipping, and affine transformations, and maintain consistent predictions even when the original models lose 20 percentage points on average when shifted by just a few pixels with Twins' accuracy dropping from 80.57% to 62.40%.
Reinforcement Learning finetuned Vision-Code Transformer for UI-to-Code Generation
May 24, 2023


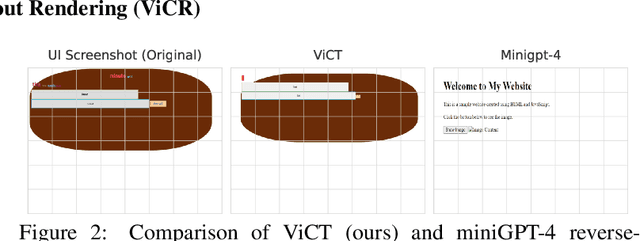
Automated HTML/CSS code generation from screenshots is an important yet challenging problem with broad applications in website development and design. In this paper, we present a novel vision-code transformer approach that leverages an Encoder-Decoder architecture as well as explore actor-critic fine-tuning as a method for improving upon the baseline. For this purpose, two image encoders are compared: Vision Transformer (ViT) and Document Image Transformer (DiT). We propose an end-to-end pipeline that can generate high-quality code snippets directly from screenshots, streamlining the website creation process for developers. To train and evaluate our models, we created a synthetic dataset of 30,000 unique pairs of code and corresponding screenshots. We evaluate the performance of our approach using a combination of automated metrics such as MSE, BLEU, IoU, and a novel htmlBLEU score, where our models demonstrated strong performance. We establish a strong baseline with the DiT-GPT2 model and show that actor-critic can be used to improve IoU score from the baseline of 0.64 to 0.79 and lower MSE from 12.25 to 9.02. We achieved similar performance as when using larger models, with much lower computational cost.
RNN-based Online Handwritten Character Recognition Using Accelerometer and Gyroscope Data
Jul 24, 2019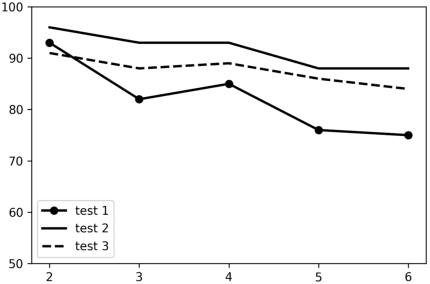
This abstract explores an RNN-based approach to online handwritten recognition problem. Our method uses data from an accelerometer and a gyroscope mounted on a handheld pen-like device to train and run a character pre-diction model. We have built a dataset of timestamped gyroscope and accelerometer data gathered during the manual process of handwriting Latin characters, labeled with the character being written; in total, the dataset con-sists of 1500 gyroscope and accelerometer data sequenc-es for 8 characters of the Latin alphabet from 6 different people, and 20 characters, each 1500 samples from Georgian alphabet from 5 different people. with each sequence containing the gyroscope and accelerometer data captured during the writing of a particular character sampled once every 10ms. We train an RNN-based neural network architecture on this dataset to predict the character being written. The model is optimized with categorical cross-entropy loss and RMSprop optimizer and achieves high accuracy on test data.
Reproduction Report on "Learn to Pay Attention"
Dec 11, 2018
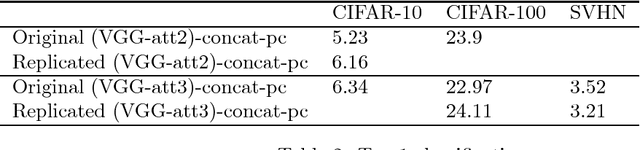
We have successfully implemented the "Learn to Pay Attention" model of attention mechanism in convolutional neural networks, and have replicated the results of the original paper in the categories of image classification and fine-grained recognition.