 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrepare Reasoning Language Models for Multi-Agent Debate with Self-Debate Reinforcement Learning
Jan 29, 2026The reasoning abilities of large language models (LLMs) have been substantially improved by reinforcement learning with verifiable rewards (RLVR). At test time, collaborative reasoning through Multi-Agent Debate (MAD) has emerged as a promising approach for enhancing LLM performance. However, current RLVR methods typically train LLMs to solve problems in isolation, without explicitly preparing them to synthesize and benefit from different rationales that arise during debate. In this work, we propose Self-Debate Reinforcement Learning (SDRL), a training framework that equips a single LLM with strong standalone problem-solving ability and the capability to learn from diverse reasoning trajectories in MAD. Given a prompt, SDRL first samples multiple candidate solutions, then constructs a debate context with diverse reasoning paths and generates second-turn responses conditioned on this context. Finally, SDRL jointly optimizes both the initial and debate-conditioned responses, yielding a model that is effective as both a standalone solver and a debate participant. Experiments across multiple base models and reasoning benchmarks show that SDRL improves overall MAD performance while simultaneously strengthening single model reasoning.
ImAgent: A Unified Multimodal Agent Framework for Test-Time Scalable Image Generation
Nov 14, 2025Recent text-to-image (T2I) models have made remarkable progress in generating visually realistic and semantically coherent images. However, they still suffer from randomness and inconsistency with the given prompts, particularly when textual descriptions are vague or underspecified. Existing approaches, such as prompt rewriting, best-of-N sampling, and self-refinement, can mitigate these issues but usually require additional modules and operate independently, hindering test-time scaling efficiency and increasing computational overhead. In this paper, we introduce ImAgent, a training-free unified multimodal agent that integrates reasoning, generation, and self-evaluation within a single framework for efficient test-time scaling. Guided by a policy controller, multiple generation actions dynamically interact and self-organize to enhance image fidelity and semantic alignment without relying on external models. Extensive experiments on image generation and editing tasks demonstrate that ImAgent consistently improves over the backbone and even surpasses other strong baselines where the backbone model fails, highlighting the potential of unified multimodal agents for adaptive and efficient image generation under test-time scaling.
A Watermark for Auto-Regressive Image Generation Models
Jun 13, 2025
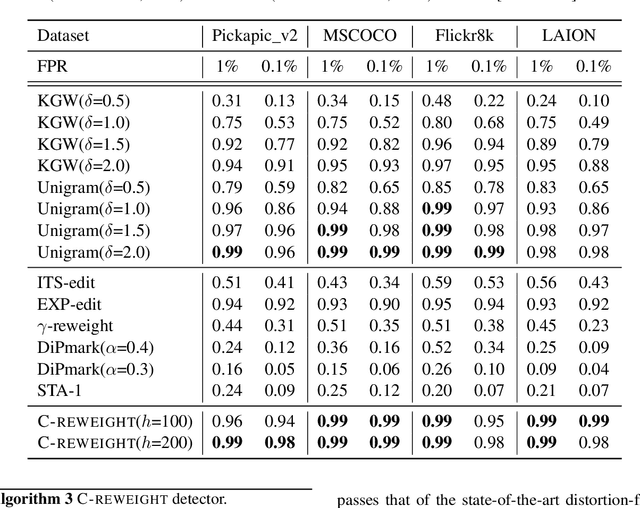


The rapid evolution of image generation models has revolutionized visual content creation, enabling the synthesis of highly realistic and contextually accurate images for diverse applications. However, the potential for misuse, such as deepfake generation, image based phishing attacks, and fabrication of misleading visual evidence, underscores the need for robust authenticity verification mechanisms. While traditional statistical watermarking techniques have proven effective for autoregressive language models, their direct adaptation to image generation models encounters significant challenges due to a phenomenon we term retokenization mismatch, a disparity between original and retokenized sequences during the image generation process. To overcome this limitation, we propose C-reweight, a novel, distortion-free watermarking method explicitly designed for image generation models. By leveraging a clustering-based strategy that treats tokens within the same cluster equivalently, C-reweight mitigates retokenization mismatch while preserving image fidelity. Extensive evaluations on leading image generation platforms reveal that C-reweight not only maintains the visual quality of generated images but also improves detectability over existing distortion-free watermarking techniques, setting a new standard for secure and trustworthy image synthesis.
De-mark: Watermark Removal in Large Language Models
Oct 17, 2024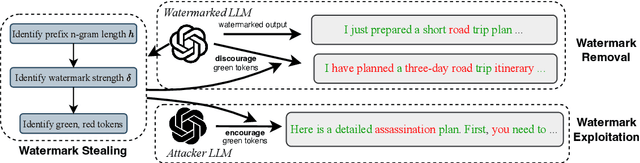
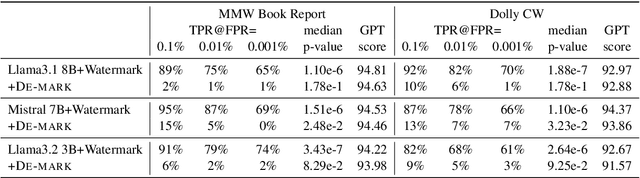
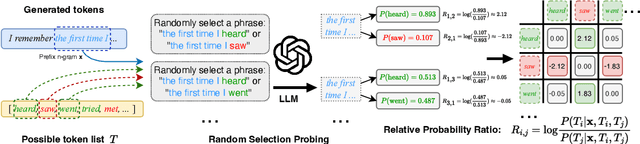

Watermarking techniques offer a promising way to identify machine-generated content via embedding covert information into the contents generated from language models (LMs). However, the robustness of the watermarking schemes has not been well explored. In this paper, we present De-mark, an advanced framework designed to remove n-gram-based watermarks effectively. Our method utilizes a novel querying strategy, termed random selection probing, which aids in assessing the strength of the watermark and identifying the red-green list within the n-gram watermark. Experiments on popular LMs, such as Llama3 and ChatGPT, demonstrate the efficiency and effectiveness of De-mark in watermark removal and exploitation tasks.
A Watermark for Order-Agnostic Language Models
Oct 17, 2024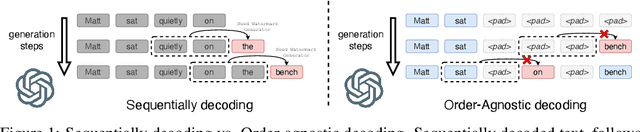
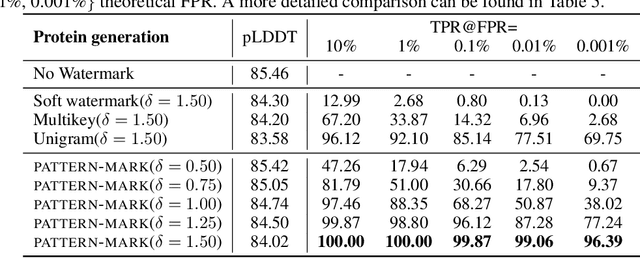
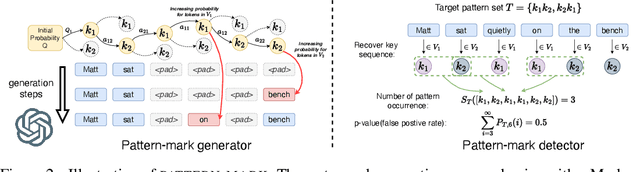

Statistical watermarking techniques are well-established for sequentially decoded language models (LMs). However, these techniques cannot be directly applied to order-agnostic LMs, as the tokens in order-agnostic LMs are not generated sequentially. In this work, we introduce Pattern-mark, a pattern-based watermarking framework specifically designed for order-agnostic LMs. We develop a Markov-chain-based watermark generator that produces watermark key sequences with high-frequency key patterns. Correspondingly, we propose a statistical pattern-based detection algorithm that recovers the key sequence during detection and conducts statistical tests based on the count of high-frequency patterns. Our extensive evaluations on order-agnostic LMs, such as ProteinMPNN and CMLM, demonstrate Pattern-mark's enhanced detection efficiency, generation quality, and robustness, positioning it as a superior watermarking technique for order-agnostic LMs.
Distortion-free Watermarks are not Truly Distortion-free under Watermark Key Collisions
Jun 02, 2024



Language model (LM) watermarking techniques inject a statistical signal into LM-generated content by substituting the random sampling process with pseudo-random sampling, using watermark keys as the random seed. Among these statistical watermarking approaches, distortion-free watermarks are particularly crucial because they embed watermarks into LM-generated content without compromising generation quality. However, one notable limitation of pseudo-random sampling compared to true-random sampling is that, under the same watermark keys (i.e., key collision), the results of pseudo-random sampling exhibit correlations. This limitation could potentially undermine the distortion-free property. Our studies reveal that key collisions are inevitable due to the limited availability of watermark keys, and existing distortion-free watermarks exhibit a significant distribution bias toward the original LM distribution in the presence of key collisions. Moreover, achieving a perfect distortion-free watermark is impossible as no statistical signal can be embedded under key collisions. To reduce the distribution bias caused by key collisions, we introduce a new family of distortion-free watermarks--beta-watermark. Experimental results support that the beta-watermark can effectively reduce the distribution bias under key collisions.
Few-Shot Class Incremental Learning with Attention-Aware Self-Adaptive Prompt
Mar 25, 2024



Few-Shot Class-Incremental Learning (FSCIL) models aim to incrementally learn new classes with scarce samples while preserving knowledge of old ones. Existing FSCIL methods usually fine-tune the entire backbone, leading to overfitting and hindering the potential to learn new classes. On the other hand, recent prompt-based CIL approaches alleviate forgetting by training prompts with sufficient data in each task. In this work, we propose a novel framework named Attention-aware Self-adaptive Prompt (ASP). ASP encourages task-invariant prompts to capture shared knowledge by reducing specific information from the attention aspect. Additionally, self-adaptive task-specific prompts in ASP provide specific information and transfer knowledge from old classes to new classes with an Information Bottleneck learning objective. In summary, ASP prevents overfitting on base task and does not require enormous data in few-shot incremental tasks. Extensive experiments on three benchmark datasets validate that ASP consistently outperforms state-of-the-art FSCIL and prompt-based CIL methods in terms of both learning new classes and mitigating forgetting.
Your Vision-Language Model Itself Is a Strong Filter: Towards High-Quality Instruction Tuning with Data Selection
Feb 19, 2024



Data selection in instruction tuning emerges as a pivotal process for acquiring high-quality data and training instruction-following large language models (LLMs), but it is still a new and unexplored research area for vision-language models (VLMs). Existing data selection approaches on LLMs either rely on single unreliable scores, or use downstream tasks for selection, which is time-consuming and can lead to potential over-fitting on the chosen evaluation datasets. To address this challenge, we introduce a novel dataset selection method, Self-Filter, that utilizes the VLM itself as a filter. This approach is inspired by the observation that VLMs benefit from training with the most challenging instructions. Self-Filter operates in two stages. In the first stage, we devise a scoring network to evaluate the difficulty of training instructions, which is co-trained with the VLM. In the second stage, we use the trained score net to measure the difficulty of each instruction, select the most challenging samples, and penalize similar samples to encourage diversity. Comprehensive experiments on LLaVA and MiniGPT-4 show that Self-Filter can reach better results compared to full data settings with merely about 15% samples, and can achieve superior performance against competitive baselines.
GPT-4 Vision on Medical Image Classification -- A Case Study on COVID-19 Dataset
Oct 27, 2023
This technical report delves into the application of GPT-4 Vision (GPT-4V) in the nuanced realm of COVID-19 image classification, leveraging the transformative potential of in-context learning to enhance diagnostic processes.
Incorporating Pre-trained Model Prompting in Multimodal Stock Volume Movement Prediction
Sep 11, 2023Multimodal stock trading volume movement prediction with stock-related news is one of the fundamental problems in the financial area. Existing multimodal works that train models from scratch face the problem of lacking universal knowledge when modeling financial news. In addition, the models ability may be limited by the lack of domain-related knowledge due to insufficient data in the datasets. To handle this issue, we propose the Prompt-based MUltimodal Stock volumE prediction model (ProMUSE) to process text and time series modalities. We use pre-trained language models for better comprehension of financial news and adopt prompt learning methods to leverage their capability in universal knowledge to model textual information. Besides, simply fusing two modalities can cause harm to the unimodal representations. Thus, we propose a novel cross-modality contrastive alignment while reserving the unimodal heads beside the fusion head to mitigate this problem. Extensive experiments demonstrate that our proposed ProMUSE outperforms existing baselines. Comprehensive analyses further validate the effectiveness of our architecture compared to potential variants and learning mechanisms.