Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe-mark: Watermark Removal in Large Language Models
Paper and Code
Oct 17, 2024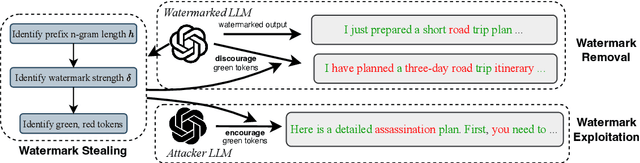
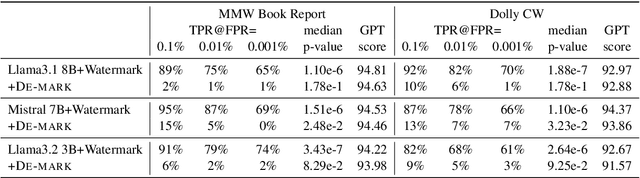
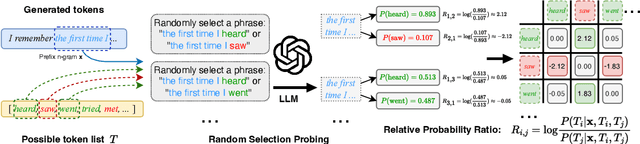

Watermarking techniques offer a promising way to identify machine-generated content via embedding covert information into the contents generated from language models (LMs). However, the robustness of the watermarking schemes has not been well explored. In this paper, we present De-mark, an advanced framework designed to remove n-gram-based watermarks effectively. Our method utilizes a novel querying strategy, termed random selection probing, which aids in assessing the strength of the watermark and identifying the red-green list within the n-gram watermark. Experiments on popular LMs, such as Llama3 and ChatGPT, demonstrate the efficiency and effectiveness of De-mark in watermark removal and exploitation tasks.
View paper on