 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrepare Reasoning Language Models for Multi-Agent Debate with Self-Debate Reinforcement Learning
Jan 29, 2026The reasoning abilities of large language models (LLMs) have been substantially improved by reinforcement learning with verifiable rewards (RLVR). At test time, collaborative reasoning through Multi-Agent Debate (MAD) has emerged as a promising approach for enhancing LLM performance. However, current RLVR methods typically train LLMs to solve problems in isolation, without explicitly preparing them to synthesize and benefit from different rationales that arise during debate. In this work, we propose Self-Debate Reinforcement Learning (SDRL), a training framework that equips a single LLM with strong standalone problem-solving ability and the capability to learn from diverse reasoning trajectories in MAD. Given a prompt, SDRL first samples multiple candidate solutions, then constructs a debate context with diverse reasoning paths and generates second-turn responses conditioned on this context. Finally, SDRL jointly optimizes both the initial and debate-conditioned responses, yielding a model that is effective as both a standalone solver and a debate participant. Experiments across multiple base models and reasoning benchmarks show that SDRL improves overall MAD performance while simultaneously strengthening single model reasoning.
Fast and scalable Wasserstein-1 neural optimal transport solver for single-cell perturbation prediction
Nov 01, 2024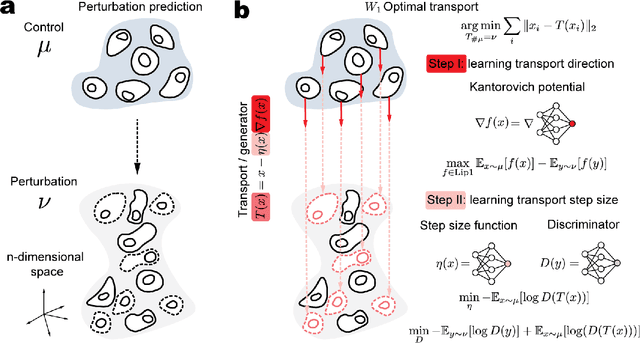
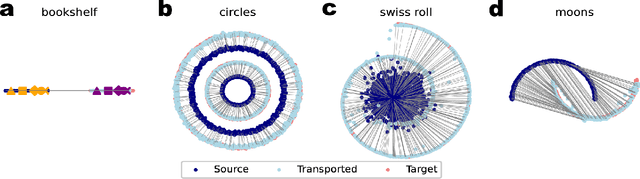
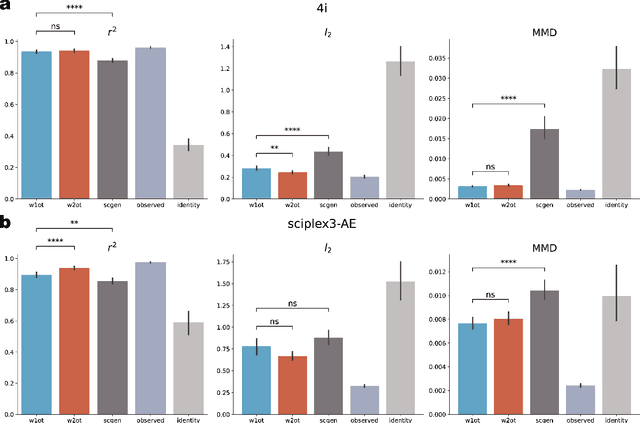
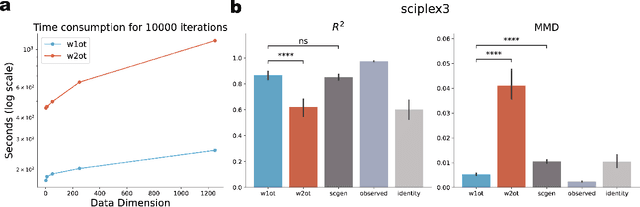
Predicting single-cell perturbation responses requires mapping between two unpaired single-cell data distributions. Optimal transport (OT) theory provides a principled framework for constructing such mappings by minimizing transport cost. Recently, Wasserstein-2 ($W_2$) neural optimal transport solvers (\textit{e.g.}, CellOT) have been employed for this prediction task. However, $W_2$ OT relies on the general Kantorovich dual formulation, which involves optimizing over two conjugate functions, leading to a complex min-max optimization problem that converges slowly. To address these challenges, we propose a novel solver based on the Wasserstein-1 ($W_1$) dual formulation. Unlike $W_2$, the $W_1$ dual simplifies the optimization to a maximization problem over a single 1-Lipschitz function, thus eliminating the need for time-consuming min-max optimization. While solving the $W_1$ dual only reveals the transport direction and does not directly provide a unique optimal transport map, we incorporate an additional step using adversarial training to determine an appropriate transport step size, effectively recovering the transport map. Our experiments demonstrate that the proposed $W_1$ neural optimal transport solver can mimic the $W_2$ OT solvers in finding a unique and ``monotonic" map on 2D datasets. Moreover, the $W_1$ OT solver achieves performance on par with or surpasses $W_2$ OT solvers on real single-cell perturbation datasets. Furthermore, we show that $W_1$ OT solver achieves $25 \sim 45\times$ speedup, scales better on high dimensional transportation task, and can be directly applied on single-cell RNA-seq dataset with highly variable genes. Our implementation and experiments are open-sourced at \url{https://github.com/poseidonchan/w1ot}.
A Watermark for Order-Agnostic Language Models
Oct 17, 2024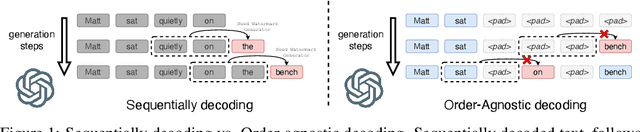
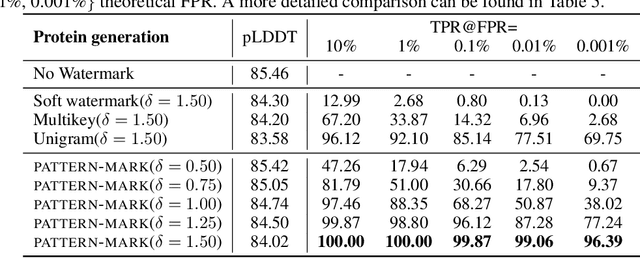
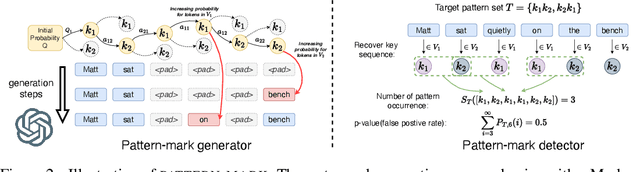

Statistical watermarking techniques are well-established for sequentially decoded language models (LMs). However, these techniques cannot be directly applied to order-agnostic LMs, as the tokens in order-agnostic LMs are not generated sequentially. In this work, we introduce Pattern-mark, a pattern-based watermarking framework specifically designed for order-agnostic LMs. We develop a Markov-chain-based watermark generator that produces watermark key sequences with high-frequency key patterns. Correspondingly, we propose a statistical pattern-based detection algorithm that recovers the key sequence during detection and conducts statistical tests based on the count of high-frequency patterns. Our extensive evaluations on order-agnostic LMs, such as ProteinMPNN and CMLM, demonstrate Pattern-mark's enhanced detection efficiency, generation quality, and robustness, positioning it as a superior watermarking technique for order-agnostic LMs.
Distortion-free Watermarks are not Truly Distortion-free under Watermark Key Collisions
Jun 02, 2024



Language model (LM) watermarking techniques inject a statistical signal into LM-generated content by substituting the random sampling process with pseudo-random sampling, using watermark keys as the random seed. Among these statistical watermarking approaches, distortion-free watermarks are particularly crucial because they embed watermarks into LM-generated content without compromising generation quality. However, one notable limitation of pseudo-random sampling compared to true-random sampling is that, under the same watermark keys (i.e., key collision), the results of pseudo-random sampling exhibit correlations. This limitation could potentially undermine the distortion-free property. Our studies reveal that key collisions are inevitable due to the limited availability of watermark keys, and existing distortion-free watermarks exhibit a significant distribution bias toward the original LM distribution in the presence of key collisions. Moreover, achieving a perfect distortion-free watermark is impossible as no statistical signal can be embedded under key collisions. To reduce the distribution bias caused by key collisions, we introduce a new family of distortion-free watermarks--beta-watermark. Experimental results support that the beta-watermark can effectively reduce the distribution bias under key collisions.
GPT-4 Vision on Medical Image Classification -- A Case Study on COVID-19 Dataset
Oct 27, 2023
This technical report delves into the application of GPT-4 Vision (GPT-4V) in the nuanced realm of COVID-19 image classification, leveraging the transformative potential of in-context learning to enhance diagnostic processes.