 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIAV-MVS: Recurrent-Indexing an Asymmetric Volume for Multi-View Stereo
Paper and Code
May 28, 2022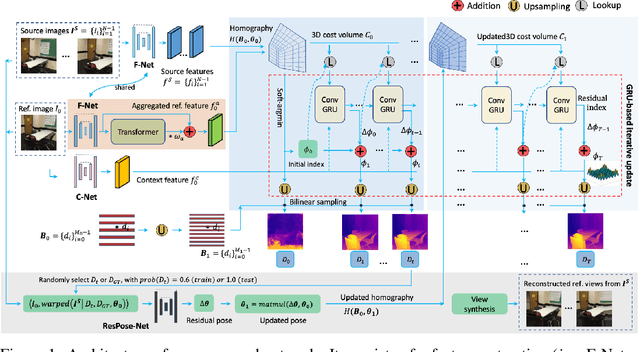
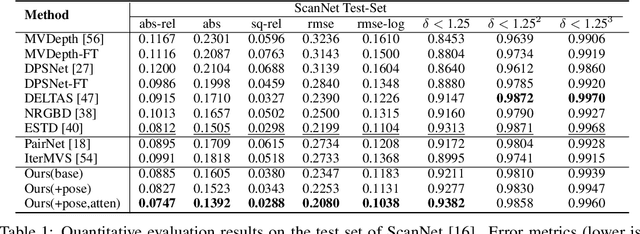
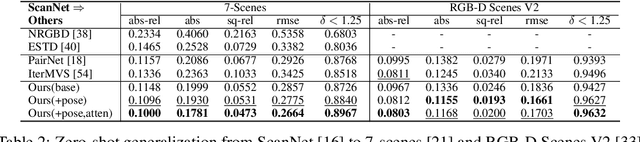

In this paper, we present a learning-based approach for multi-view stereo (MVS), i.e., estimate the depth map of a reference frame using posed multi-view images. Our core idea lies in leveraging a "learning-to-optimize" paradigm to iteratively index a plane-sweeping cost volume and regress the depth map via a convolutional Gated Recurrent Unit (GRU). Since the cost volume plays a paramount role in encoding the multi-view geometry, we aim to improve its construction both in pixel- and frame- levels. In the pixel level, we propose to break the symmetry of the Siamese network (which is typically used in MVS to extract image features) by introducing a transformer block to the reference image (but not to the source images). Such an asymmetric volume allows the network to extract global features from the reference image to predict its depth map. In view of the inaccuracy of poses between reference and source images, we propose to incorporate a residual pose network to make corrections to the relative poses, which essentially rectifies the cost volume in the frame-level. We conduct extensive experiments on real-world MVS datasets and show that our method achieves state-of-the-art performance in terms of both within-dataset evaluation and cross-dataset generalization.