 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Dense 3D Mapping of Underwater Environments
Apr 05, 2023



This paper addresses real-time dense 3D reconstruction for a resource-constrained Autonomous Underwater Vehicle (AUV). Underwater vision-guided operations are among the most challenging as they combine 3D motion in the presence of external forces, limited visibility, and absence of global positioning. Obstacle avoidance and effective path planning require online dense reconstructions of the environment. Autonomous operation is central to environmental monitoring, marine archaeology, resource utilization, and underwater cave exploration. To address this problem, we propose to use SVIn2, a robust VIO method, together with a real-time 3D reconstruction pipeline. We provide extensive evaluation on four challenging underwater datasets. Our pipeline produces comparable reconstruction with that of COLMAP, the state-of-the-art offline 3D reconstruction method, at high frame rates on a single CPU.
On the Synergies between Machine Learning and Stereo: a Survey
Apr 18, 2020



Stereo matching is one of the longest-standing problems in computer vision with close to 40 years of studies and research. Throughout the years the paradigm has shifted from local, pixel-level decision to various forms of discrete and continuous optimization to data-driven, learning-based methods. Recently, the rise of machine learning and the rapid proliferation of deep learning enhanced stereo matching with new exciting trends and applications unthinkable until a few years ago. Interestingly, the relationship between these two worlds is two-way. While machine, and especially deep, learning advanced the state-of-the-art in stereo matching, stereo matching enabled new ground-breaking methodologies such as self-supervised monocular depth estimation based on deep neural networks. In this paper, we review recent research in the field of learning-based depth estimation from images highlighting the synergies, the successes achieved so far and the open challenges the community is going to face in the immediate future.
CBMV: A Coalesced Bidirectional Matching Volume for Disparity Estimation
Apr 05, 2018

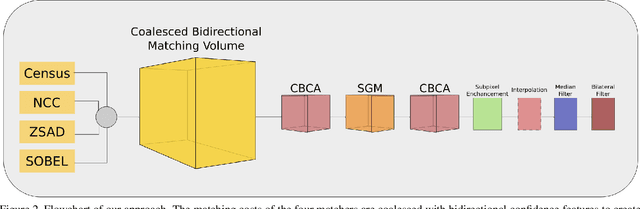

Recently, there has been a paradigm shift in stereo matching with learning-based methods achieving the best results on all popular benchmarks. The success of these methods is due to the availability of training data with ground truth; training learning-based systems on these datasets has allowed them to surpass the accuracy of conventional approaches based on heuristics and assumptions. Many of these assumptions, however, had been validated extensively and hold for the majority of possible inputs. In this paper, we generate a matching volume leveraging both data with ground truth and conventional wisdom. We accomplish this by coalescing diverse evidence from a bidirectional matching process via random forest classifiers. We show that the resulting matching volume estimation method achieves similar accuracy to purely data-driven alternatives on benchmarks and that it generalizes to unseen data much better. In fact, the results we submitted to the KITTI and ETH3D benchmarks were generated using a classifier trained on the Middlebury 2014 dataset.