 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe-STT: De-entaglement of unwanted Nuisances and Biases in Speech to Text System using Adversarial Forgetting
Dec 01, 2020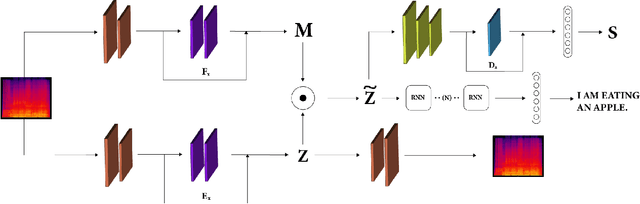

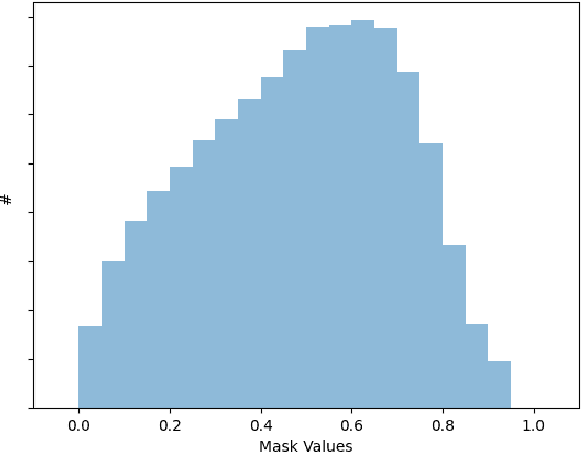
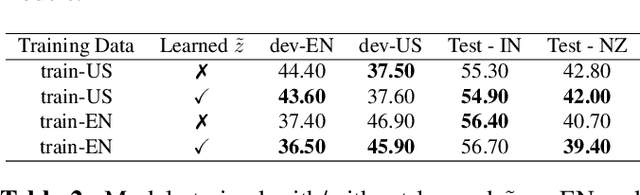
Training robust Speech to Text (STT) system require "tens of thousand" of hours of data. Variability present in the dataset, in the form of unwanted nuisances (noise) and biases (accent, gender or age) is the reason for the need of large datasets to learn general representations, which is unfeasible for low resource languages. A recently proposed deep learning approach to remove these unwanted features, called adversarial forgetting, was able to produce better results on computer vision tasks. Motivated by this, in this paper, we study the effect of de-entangling the accent information from the input speech signal on training STT systems. To this end, we use an information bottleneck architecture based on adversarial forgetting. This training scheme aims to enforce the model to learn general accent invariant speech representations. The trained STT model is tested on two unseen accents in the common voice V1. The results are in favour of STT model trained using the adversarial forgetting scheme.