 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeploying Multi-task Online Server with Large Language Model
Nov 07, 2024
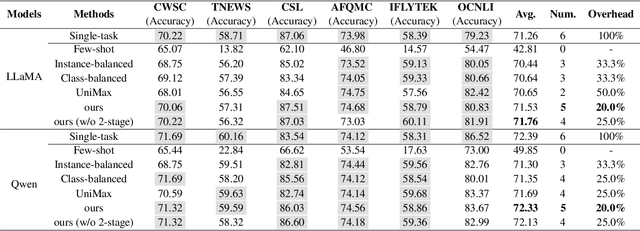
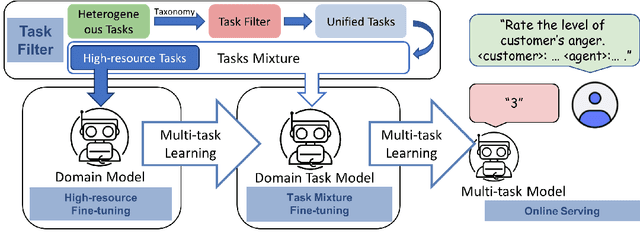

In the industry, numerous tasks are deployed online. Traditional approaches often tackle each task separately by its own network, which leads to excessive costs for developing and scaling models, especially in the context of large language models. Although multi-task methods can save costs through parameter sharing, they often struggle to outperform single-task methods in real-world applications. To tackle these challenges, we present a three-stage multi-task learning framework for large language models. It involves task filtering, followed by fine-tuning on high-resource tasks, and finally fine-tuning on all tasks. We conducted comprehensive experiments in single-task and multi-task settings. Our approach, exemplified on different benchmarks, demonstrates that it is able to achieve performance comparable to the single-task method while reducing up to 90.9\% of its overhead.
AgentSims: An Open-Source Sandbox for Large Language Model Evaluation
Aug 08, 2023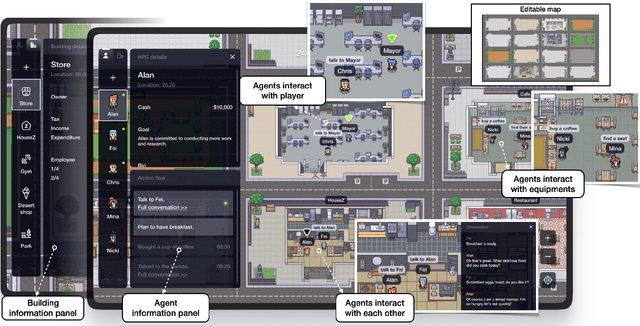
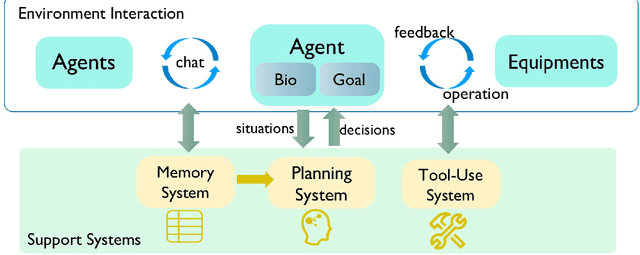
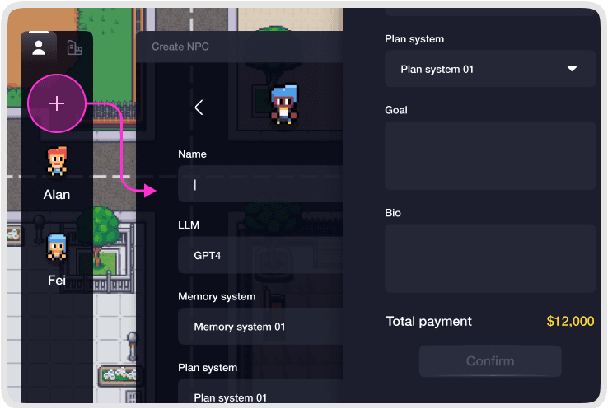
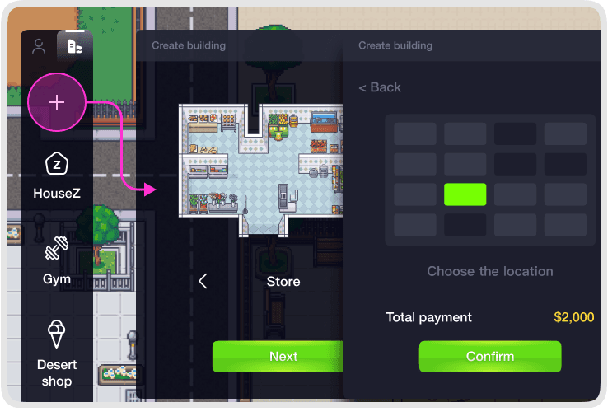
With ChatGPT-like large language models (LLM) prevailing in the community, how to evaluate the ability of LLMs is an open question. Existing evaluation methods suffer from following shortcomings: (1) constrained evaluation abilities, (2) vulnerable benchmarks, (3) unobjective metrics. We suggest that task-based evaluation, where LLM agents complete tasks in a simulated environment, is a one-for-all solution to solve above problems. We present AgentSims, an easy-to-use infrastructure for researchers from all disciplines to test the specific capacities they are interested in. Researchers can build their evaluation tasks by adding agents and buildings on an interactive GUI or deploy and test new support mechanisms, i.e. memory, planning and tool-use systems, by a few lines of codes. Our demo is available at https://agentsims.com .
A Tale of Two Approximations: Tightening Over-Approximation for DNN Robustness Verification via Under-Approximation
May 26, 2023
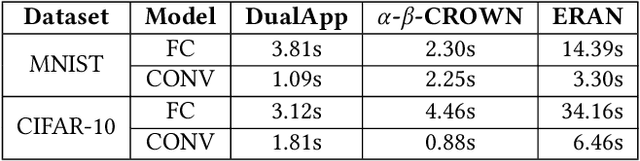


The robustness of deep neural networks (DNNs) is crucial to the hosting system's reliability and security. Formal verification has been demonstrated to be effective in providing provable robustness guarantees. To improve its scalability, over-approximating the non-linear activation functions in DNNs by linear constraints has been widely adopted, which transforms the verification problem into an efficiently solvable linear programming problem. Many efforts have been dedicated to defining the so-called tightest approximations to reduce overestimation imposed by over-approximation. In this paper, we study existing approaches and identify a dominant factor in defining tight approximation, namely the approximation domain of the activation function. We find out that tight approximations defined on approximation domains may not be as tight as the ones on their actual domains, yet existing approaches all rely only on approximation domains. Based on this observation, we propose a novel dual-approximation approach to tighten over-approximations, leveraging an activation function's underestimated domain to define tight approximation bounds. We implement our approach with two complementary algorithms based respectively on Monte Carlo simulation and gradient descent into a tool called DualApp. We assess it on a comprehensive benchmark of DNNs with different architectures. Our experimental results show that DualApp significantly outperforms the state-of-the-art approaches with 100% - 1000% improvement on the verified robustness ratio and 10.64% on average (up to 66.53%) on the certified lower bound.
DualApp: Tight Over-Approximation for Neural Network Robustness Verification via Under-Approximation
Nov 21, 2022The robustness of neural networks is fundamental to the hosting system's reliability and security. Formal verification has been proven to be effective in providing provable robustness guarantees. To improve the verification scalability, over-approximating the non-linear activation functions in neural networks by linear constraints is widely adopted, which transforms the verification problem into an efficiently solvable linear programming problem. As over-approximations inevitably introduce overestimation, many efforts have been dedicated to defining the tightest possible approximations. Recent studies have however showed that the existing so-called tightest approximations are superior to each other. In this paper we identify and report an crucial factor in defining tight approximations, namely the approximation domains of activation functions. We observe that existing approaches only rely on overestimated domains, while the corresponding tight approximation may not necessarily be tight on its actual domain. We propose a novel under-approximation-guided approach, called dual-approximation, to define tight over-approximations and two complementary under-approximation algorithms based on sampling and gradient descent. The overestimated domain guarantees the soundness while the underestimated one guides the tightness. We implement our approach into a tool called DualApp and extensively evaluate it on a comprehensive benchmark of 84 collected and trained neural networks with different architectures. The experimental results show that DualApp outperforms the state-of-the-art approximation-based approaches, with up to 71.22% improvement to the verification result.
Provably Tightest Linear Approximation for Robustness Verification of Sigmoid-like Neural Networks
Aug 21, 2022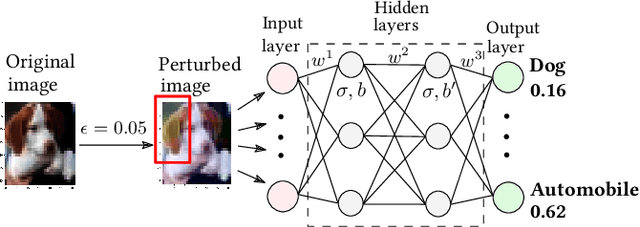
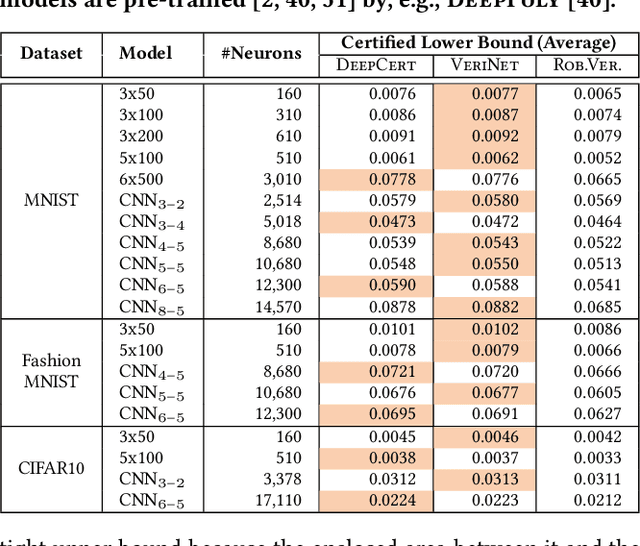


The robustness of deep neural networks is crucial to modern AI-enabled systems and should be formally verified. Sigmoid-like neural networks have been adopted in a wide range of applications. Due to their non-linearity, Sigmoid-like activation functions are usually over-approximated for efficient verification, which inevitably introduces imprecision. Considerable efforts have been devoted to finding the so-called tighter approximations to obtain more precise verification results. However, existing tightness definitions are heuristic and lack theoretical foundations. We conduct a thorough empirical analysis of existing neuron-wise characterizations of tightness and reveal that they are superior only on specific neural networks. We then introduce the notion of network-wise tightness as a unified tightness definition and show that computing network-wise tightness is a complex non-convex optimization problem. We bypass the complexity from different perspectives via two efficient, provably tightest approximations. The results demonstrate the promising performance achievement of our approaches over state of the art: (i) achieving up to 251.28% improvement to certified lower robustness bounds; and (ii) exhibiting notably more precise verification results on convolutional networks.