 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYOLO-MED : Multi-Task Interaction Network for Biomedical Images
Paper and Code
Mar 01, 2024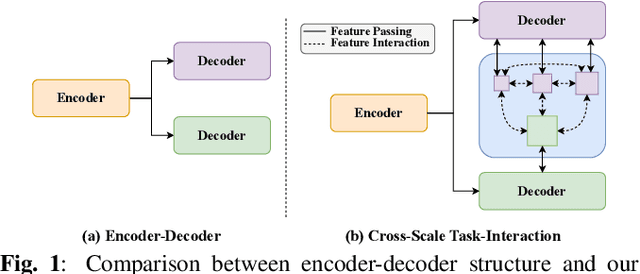
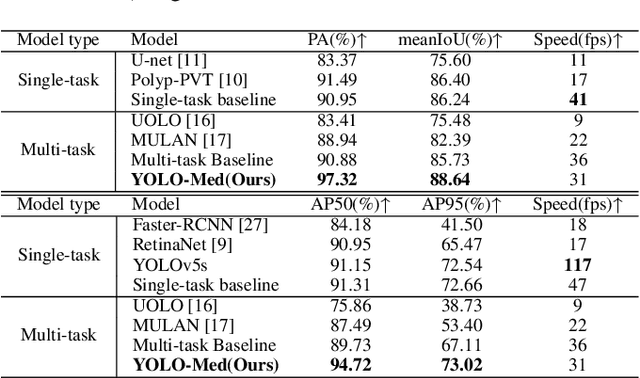
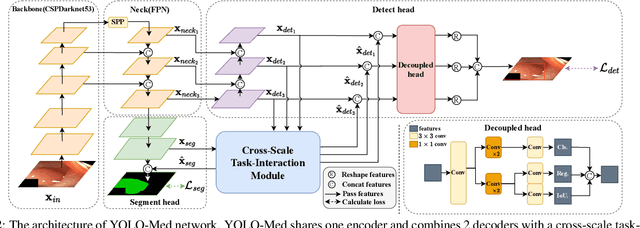

Object detection and semantic segmentation are pivotal components in biomedical image analysis. Current single-task networks exhibit promising outcomes in both detection and segmentation tasks. Multi-task networks have gained prominence due to their capability to simultaneously tackle segmentation and detection tasks, while also accelerating the segmentation inference. Nevertheless, recent multi-task networks confront distinct limitations such as the difficulty in striking a balance between accuracy and inference speed. Additionally, they often overlook the integration of cross-scale features, which is especially important for biomedical image analysis. In this study, we propose an efficient end-to-end multi-task network capable of concurrently performing object detection and semantic segmentation called YOLO-Med. Our model employs a backbone and a neck for multi-scale feature extraction, complemented by the inclusion of two task-specific decoders. A cross-scale task-interaction module is employed in order to facilitate information fusion between various tasks. Our model exhibits promising results in balancing accuracy and speed when evaluated on the Kvasir-seg dataset and a private biomedical image dataset.