 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond MACs: Hardware Efficient Architecture Design for Vision Backbones
Mar 27, 2026Vision backbone networks play a central role in modern computer vision. Enhancing their efficiency directly benefits a wide range of downstream applications. To measure efficiency, many publications rely on MACs (Multiply Accumulate operations) as a predictor of execution time. In this paper, we experimentally demonstrate the shortcomings of such a metric, especially in the context of edge devices. By contrasting the MAC count and execution time of common architectural design elements, we identify key factors for efficient execution and provide insights to optimize backbone design. Based on these insights, we present LowFormer, a novel vision backbone family. LowFormer features a streamlined macro and micro design that includes Lowtention, a lightweight alternative to Multi-Head Self-Attention. Lowtention not only proves more efficient, but also enables superior results on ImageNet. Additionally, we present an edge GPU version of LowFormer, that can further improve upon its baseline's speed on edge GPU and desktop GPU. We demonstrate LowFormer's wide applicability by evaluating it on smaller image classification datasets, as well as adapting it to several downstream tasks, such as object detection, semantic segmentation, image retrieval, and visual object tracking. LowFormer models consistently achieve remarkable speed-ups across various hardware platforms compared to recent state-of-the-art backbones. Code and models are available at https://github.com/altair199797/LowFormer/blob/main/Beyond_MACs.md.
CPUBone: Efficient Vision Backbone Design for Devices with Low Parallelization Capabilities
Mar 27, 2026Recent research on vision backbone architectures has predominantly focused on optimizing efficiency for hardware platforms with high parallel processing capabilities. This category increasingly includes embedded systems such as mobile phones and embedded AI accelerator modules. In contrast, CPUs do not have the possibility to parallelize operations in the same manner, wherefore models benefit from a specific design philosophy that balances amount of operations (MACs) and hardware-efficient execution by having high MACs per second (MACpS). In pursuit of this, we investigate two modifications to standard convolutions, aimed at reducing computational cost: grouping convolutions and reducing kernel sizes. While both adaptations substantially decrease the total number of MACs required for inference, sustaining low latency necessitates preserving hardware-efficiency. Our experiments across diverse CPU devices confirm that these adaptations successfully retain high hardware-efficiency on CPUs. Based on these insights, we introduce CPUBone, a new family of vision backbone models optimized for CPU-based inference. CPUBone achieves state-of-the-art Speed-Accuracy Trade-offs (SATs) across a wide range of CPU devices and effectively transfers its efficiency to downstream tasks such as object detection and semantic segmentation. Models and code are available at https://github.com/altair199797/CPUBone.
Online Episodic Memory Visual Query Localization with Egocentric Streaming Object Memory
Nov 25, 2024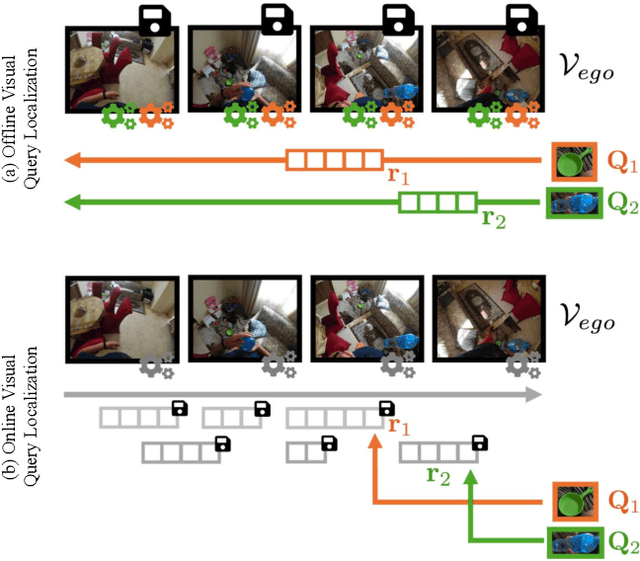
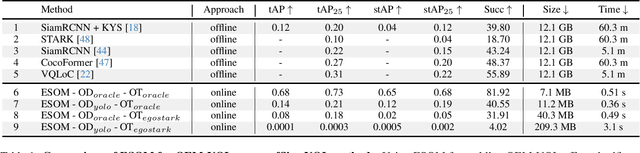
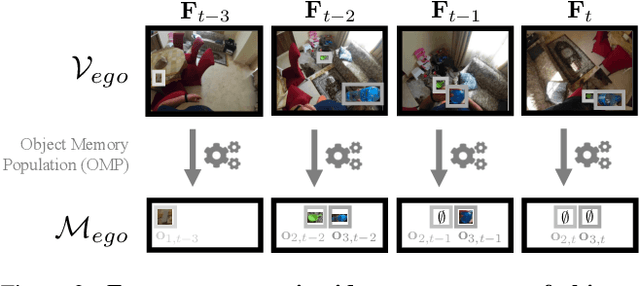
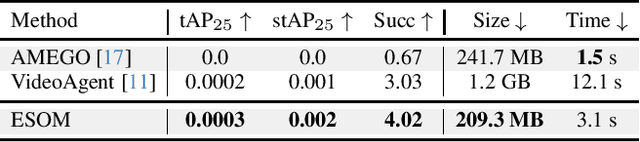
Episodic memory retrieval aims to enable wearable devices with the ability to recollect from past video observations objects or events that have been observed (e.g., "where did I last see my smartphone?"). Despite the clear relevance of the task for a wide range of assistive systems, current task formulations are based on the "offline" assumption that the full video history can be accessed when the user makes a query, which is unrealistic in real settings, where wearable devices are limited in power and storage capacity. We introduce the novel task of Online Episodic Memory Visual Queries Localization (OEM-VQL), in which models are required to work in an online fashion, observing video frames only once and relying on past computations to answer user queries. To tackle this challenging task, we propose ESOM - Egocentric Streaming Object Memory, a novel framework based on an object discovery module to detect potentially interesting objects, a visual object tracker to track their position through the video in an online fashion, and a memory module to store spatio-temporal object coordinates and image representations, which can be queried efficiently at any moment. Comparisons with different baselines and offline methods show that OEM-VQL is challenging and ESOM is a viable approach to tackle the task, with results outperforming offline methods (81.92 vs 55.89 success rate %) when oracular object discovery and tracking are considered. Our analysis also sheds light on the limited performance of object detection and tracking in egocentric vision, providing a principled benchmark based on the OEM-VQL downstream task to assess progress in these areas.
LowFormer: Hardware Efficient Design for Convolutional Transformer Backbones
Sep 05, 2024



Research in efficient vision backbones is evolving into models that are a mixture of convolutions and transformer blocks. A smart combination of both, architecture-wise and component-wise is mandatory to excel in the speedaccuracy trade-off. Most publications focus on maximizing accuracy and utilize MACs (multiply accumulate operations) as an efficiency metric. The latter however often do not measure accurately how fast a model actually is due to factors like memory access cost and degree of parallelism. We analyzed common modules and architectural design choices for backbones not in terms of MACs, but rather in actual throughput and latency, as the combination of the latter two is a better representation of the efficiency of models in real applications. We applied the conclusions taken from that analysis to create a recipe for increasing hardware-efficiency in macro design. Additionally we introduce a simple slimmed-down version of MultiHead Self-Attention, that aligns with our analysis. We combine both macro and micro design to create a new family of hardware-efficient backbone networks called LowFormer. LowFormer achieves a remarkable speedup in terms of throughput and latency, while achieving similar or better accuracy than current state-of-the-art efficient backbones. In order to prove the generalizability of our hardware-efficient design, we evaluate our method on GPU, mobile GPU and ARM CPU. We further show that the downstream tasks object detection and semantic segmentation profit from our hardware-efficient architecture. Code and models are available at https://github.com/ altair199797/LowFormer.
Efficient Feature Extraction for High-resolution Video Frame Interpolation
Nov 25, 2022Most deep learning methods for video frame interpolation consist of three main components: feature extraction, motion estimation, and image synthesis. Existing approaches are mainly distinguishable in terms of how these modules are designed. However, when interpolating high-resolution images, e.g. at 4K, the design choices for achieving high accuracy within reasonable memory requirements are limited. The feature extraction layers help to compress the input and extract relevant information for the latter stages, such as motion estimation. However, these layers are often costly in parameters, computation time, and memory. We show how ideas from dimensionality reduction combined with a lightweight optimization can be used to compress the input representation while keeping the extracted information suitable for frame interpolation. Further, we require neither a pretrained flow network nor a synthesis network, additionally reducing the number of trainable parameters and required memory. When evaluating on three 4K benchmarks, we achieve state-of-the-art image quality among the methods without pretrained flow while having the lowest network complexity and memory requirements overall.