 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter, But Not Sufficient: Testing Video ANNs Against Macaque IT Dynamics
Jan 06, 2026Feedforward artificial neural networks (ANNs) trained on static images remain the dominant models of the the primate ventral visual stream, yet they are intrinsically limited to static computations. The primate world is dynamic, and the macaque ventral visual pathways, specifically the inferior temporal (IT) cortex not only supports object recognition but also encodes object motion velocity during naturalistic video viewing. Does IT's temporal responses reflect nothing more than time-unfolded feedforward transformations, framewise features with shallow temporal pooling, or do they embody richer dynamic computations? We tested this by comparing macaque IT responses during naturalistic videos against static, recurrent, and video-based ANN models. Video models provided modest improvements in neural predictivity, particularly at later response stages, raising the question of what kind of dynamics they capture. To probe this, we applied a stress test: decoders trained on naturalistic videos were evaluated on "appearance-free" variants that preserve motion but remove shape and texture. IT population activity generalized across this manipulation, but all ANN classes failed. Thus, current video models better capture appearance-bound dynamics rather than the appearance-invariant temporal computations expressed in IT, underscoring the need for new objectives that encode biological temporal statistics and invariances.
Online Episodic Memory Visual Query Localization with Egocentric Streaming Object Memory
Nov 25, 2024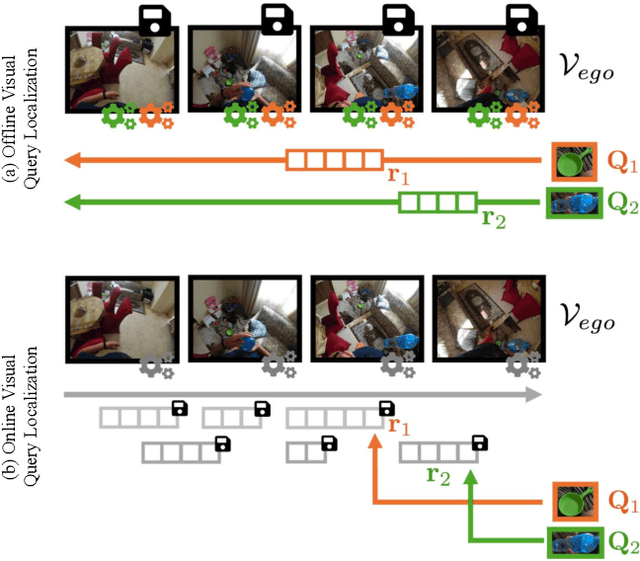
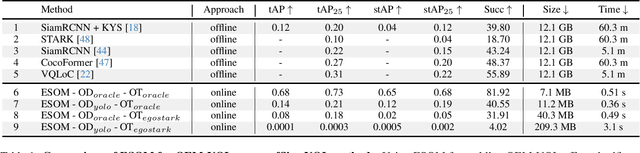
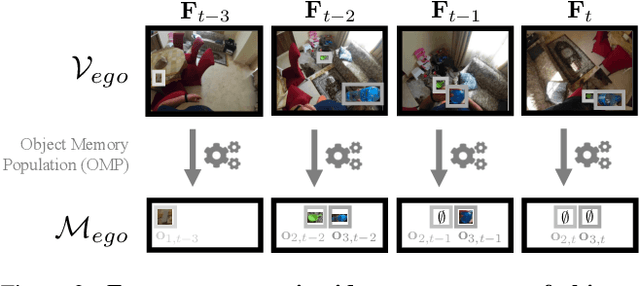
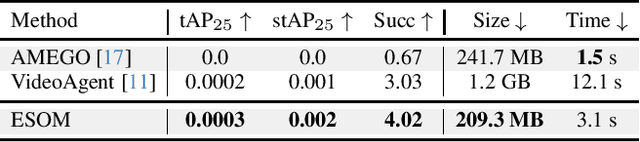
Episodic memory retrieval aims to enable wearable devices with the ability to recollect from past video observations objects or events that have been observed (e.g., "where did I last see my smartphone?"). Despite the clear relevance of the task for a wide range of assistive systems, current task formulations are based on the "offline" assumption that the full video history can be accessed when the user makes a query, which is unrealistic in real settings, where wearable devices are limited in power and storage capacity. We introduce the novel task of Online Episodic Memory Visual Queries Localization (OEM-VQL), in which models are required to work in an online fashion, observing video frames only once and relying on past computations to answer user queries. To tackle this challenging task, we propose ESOM - Egocentric Streaming Object Memory, a novel framework based on an object discovery module to detect potentially interesting objects, a visual object tracker to track their position through the video in an online fashion, and a memory module to store spatio-temporal object coordinates and image representations, which can be queried efficiently at any moment. Comparisons with different baselines and offline methods show that OEM-VQL is challenging and ESOM is a viable approach to tackle the task, with results outperforming offline methods (81.92 vs 55.89 success rate %) when oracular object discovery and tracking are considered. Our analysis also sheds light on the limited performance of object detection and tracking in egocentric vision, providing a principled benchmark based on the OEM-VQL downstream task to assess progress in these areas.
LowFormer: Hardware Efficient Design for Convolutional Transformer Backbones
Sep 05, 2024



Research in efficient vision backbones is evolving into models that are a mixture of convolutions and transformer blocks. A smart combination of both, architecture-wise and component-wise is mandatory to excel in the speedaccuracy trade-off. Most publications focus on maximizing accuracy and utilize MACs (multiply accumulate operations) as an efficiency metric. The latter however often do not measure accurately how fast a model actually is due to factors like memory access cost and degree of parallelism. We analyzed common modules and architectural design choices for backbones not in terms of MACs, but rather in actual throughput and latency, as the combination of the latter two is a better representation of the efficiency of models in real applications. We applied the conclusions taken from that analysis to create a recipe for increasing hardware-efficiency in macro design. Additionally we introduce a simple slimmed-down version of MultiHead Self-Attention, that aligns with our analysis. We combine both macro and micro design to create a new family of hardware-efficient backbone networks called LowFormer. LowFormer achieves a remarkable speedup in terms of throughput and latency, while achieving similar or better accuracy than current state-of-the-art efficient backbones. In order to prove the generalizability of our hardware-efficient design, we evaluate our method on GPU, mobile GPU and ARM CPU. We further show that the downstream tasks object detection and semantic segmentation profit from our hardware-efficient architecture. Code and models are available at https://github.com/ altair199797/LowFormer.
Tracking Skiers from the Top to the Bottom
Dec 15, 2023



Skiing is a popular winter sport discipline with a long history of competitive events. In this domain, computer vision has the potential to enhance the understanding of athletes' performance, but its application lags behind other sports due to limited studies and datasets. This paper makes a step forward in filling such gaps. A thorough investigation is performed on the task of skier tracking in a video capturing his/her complete performance. Obtaining continuous and accurate skier localization is preemptive for further higher-level performance analyses. To enable the study, the largest and most annotated dataset for computer vision in skiing, SkiTB, is introduced. Several visual object tracking algorithms, including both established methodologies and a newly introduced skier-optimized baseline algorithm, are tested using the dataset. The results provide valuable insights into the applicability of different tracking methods for vision-based skiing analysis. SkiTB, code, and results are available at https://machinelearning.uniud.it/datasets/skitb.
Visualizing Skiers' Trajectories in Monocular Videos
Apr 11, 2023



Trajectories are fundamental to winning in alpine skiing. Tools enabling the analysis of such curves can enhance the training activity and enrich broadcasting content. In this paper, we propose SkiTraVis, an algorithm to visualize the sequence of points traversed by a skier during its performance. SkiTraVis works on monocular videos and constitutes a pipeline of a visual tracker to model the skier's motion and of a frame correspondence module to estimate the camera's motion. The separation of the two motions enables the visualization of the trajectory according to the moving camera's perspective. We performed experiments on videos of real-world professional competitions to quantify the visualization error, the computational efficiency, as well as the applicability. Overall, the results achieved demonstrate the potential of our solution for broadcasting media enhancement and coach assistance.
Visual Object Tracking in First Person Vision
Sep 27, 2022



The understanding of human-object interactions is fundamental in First Person Vision (FPV). Visual tracking algorithms which follow the objects manipulated by the camera wearer can provide useful information to effectively model such interactions. In the last years, the computer vision community has significantly improved the performance of tracking algorithms for a large variety of target objects and scenarios. Despite a few previous attempts to exploit trackers in the FPV domain, a methodical analysis of the performance of state-of-the-art trackers is still missing. This research gap raises the question of whether current solutions can be used ``off-the-shelf'' or more domain-specific investigations should be carried out. This paper aims to provide answers to such questions. We present the first systematic investigation of single object tracking in FPV. Our study extensively analyses the performance of 42 algorithms including generic object trackers and baseline FPV-specific trackers. The analysis is carried out by focusing on different aspects of the FPV setting, introducing new performance measures, and in relation to FPV-specific tasks. The study is made possible through the introduction of TREK-150, a novel benchmark dataset composed of 150 densely annotated video sequences. Our results show that object tracking in FPV poses new challenges to current visual trackers. We highlight the factors causing such behavior and point out possible research directions. Despite their difficulties, we prove that trackers bring benefits to FPV downstream tasks requiring short-term object tracking. We expect that generic object tracking will gain popularity in FPV as new and FPV-specific methodologies are investigated.
CoCoLoT: Combining Complementary Trackers in Long-Term Visual Tracking
May 09, 2022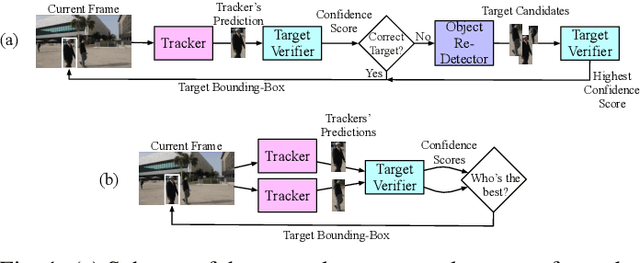



How to combine the complementary capabilities of an ensemble of different algorithms has been of central interest in visual object tracking. A significant progress on such a problem has been achieved, but considering short-term tracking scenarios. Instead, long-term tracking settings have been substantially ignored by the solutions. In this paper, we explicitly consider long-term tracking scenarios and provide a framework, named CoCoLoT, that combines the characteristics of complementary visual trackers to achieve enhanced long-term tracking performance. CoCoLoT perceives whether the trackers are following the target object through an online learned deep verification model, and accordingly activates a decision policy which selects the best performing tracker as well as it corrects the performance of the failing one. The proposed methodology is evaluated extensively and the comparison with several other solutions reveals that it competes favourably with the state-of-the-art on the most popular long-term visual tracking benchmarks.
Video-Based Reconstruction of the Trajectories Performed by Skiers
Dec 17, 2021



Trajectories are fundamental in different skiing disciplines. Tools enabling the analysis of such curves can enhance the training activity and enrich the broadcasting contents. However, the solutions currently available are based on geo-localized sensors and surface models. In this short paper, we propose a video-based approach to reconstruct the sequence of points traversed by an athlete during its performance. Our prototype is constituted by a pipeline of deep learning-based algorithms to reconstruct the athlete's motion and to visualize it according to the camera perspective. This is achieved for different skiing disciplines in the wild without any camera calibration. We tested our solution on broadcast and smartphone-captured videos of alpine skiing and ski jumping professional competitions. The qualitative results achieved show the potential of our solution.
Is First Person Vision Challenging for Object Tracking?
Aug 31, 2021
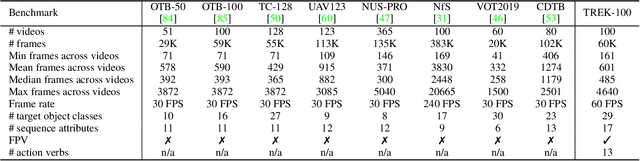


Understanding human-object interactions is fundamental in First Person Vision (FPV). Tracking algorithms which follow the objects manipulated by the camera wearer can provide useful cues to effectively model such interactions. Visual tracking solutions available in the computer vision literature have significantly improved their performance in the last years for a large variety of target objects and tracking scenarios. However, despite a few previous attempts to exploit trackers in FPV applications, a methodical analysis of the performance of state-of-the-art trackers in this domain is still missing. In this paper, we fill the gap by presenting the first systematic study of object tracking in FPV. Our study extensively analyses the performance of recent visual trackers and baseline FPV trackers with respect to different aspects and considering a new performance measure. This is achieved through TREK-150, a novel benchmark dataset composed of 150 densely annotated video sequences. Our results show that object tracking in FPV is challenging, which suggests that more research efforts should be devoted to this problem so that tracking could benefit FPV tasks.
Weakly-Supervised Domain Adaptation of Deep Regression Trackers via Reinforced Knowledge Distillation
Mar 26, 2021



Deep regression trackers are among the fastest tracking algorithms available, and therefore suitable for real-time robotic applications. However, their accuracy is inadequate in many domains due to distribution shift and overfitting. In this paper we overcome such limitations by presenting the first methodology for domain adaption of such a class of trackers. To reduce the labeling effort we propose a weakly-supervised adaptation strategy, in which reinforcement learning is used to express weak supervision as a scalar application-dependent and temporally-delayed feedback. At the same time, knowledge distillation is employed to guarantee learning stability and to compress and transfer knowledge from more powerful but slower trackers. Extensive experiments on five different robotic vision domains demonstrate the relevance of our methodology. Real-time speed is achieved on embedded devices and on machines without GPUs, while accuracy reaches significant results.