 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Generalizability of Machine Learning-based Ransomware Detection in Block Storage
Dec 30, 2024Ransomware represents a pervasive threat, traditionally countered at the operating system, file-system, or network levels. However, these approaches often introduce significant overhead and remain susceptible to circumvention by attackers. Recent research activity started looking into the detection of ransomware by observing block IO operations. However, this approach exhibits significant detection challenges. Recognizing these limitations, our research pivots towards enabling robust ransomware detection in storage systems keeping in mind their limited computational resources available. To perform our studies, we propose a kernel-based framework capable of efficiently extracting and analyzing IO operations to identify ransomware activity. The framework can be adopted to storage systems using computational storage devices to improve security and fully hide detection overheads. Our method employs a refined set of computationally light features optimized for ML models to accurately discern malicious from benign activities. Using this lightweight approach, we study a wide range of generalizability aspects and analyze the performance of these models across a large space of setups and configurations covering a wide range of realistic real-world scenarios. We reveal various trade-offs and provide strong arguments for the generalizability of storage-based detection of ransomware and show that our approach outperforms currently available ML-based ransomware detection in storage. Empirical validation reveals that our decision tree-based models achieve remarkable effectiveness, evidenced by higher median F1 scores of up to 12.8%, lower false negative rates of up to 10.9% and particularly decreased false positive rates of up to 17.1% compared to existing storage-based detection approaches.
LEAPER: Modeling Cloud FPGA-based Systems via Transfer Learning
Aug 22, 2022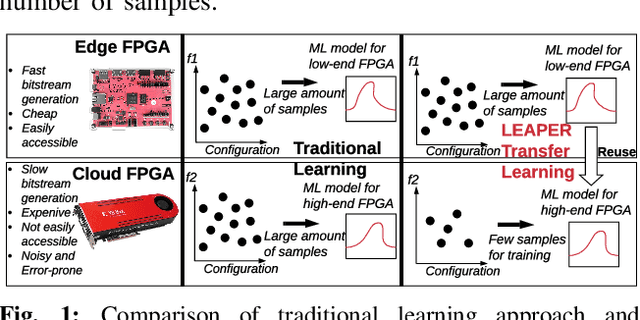
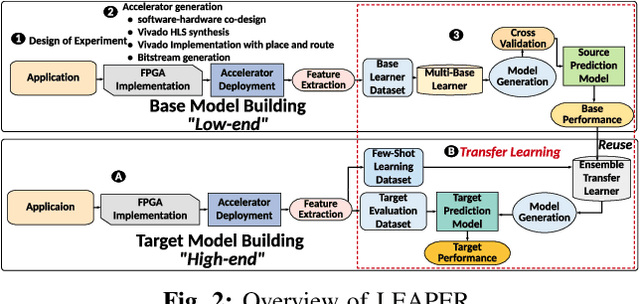
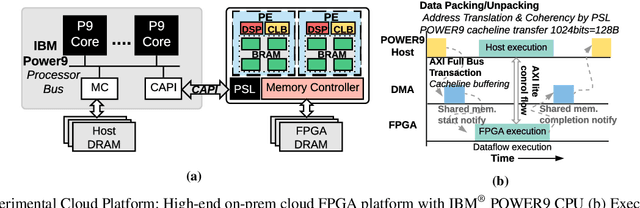
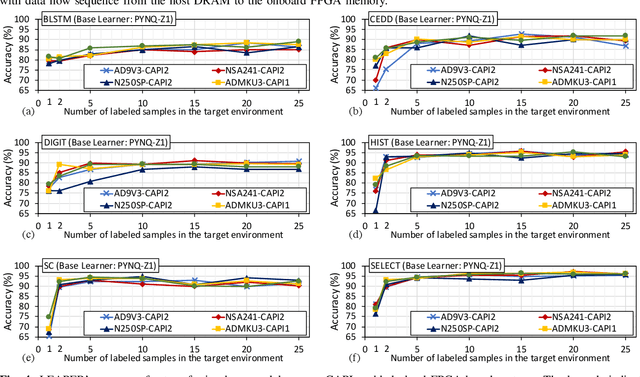
Machine-learning-based models have recently gained traction as a way to overcome the slow downstream implementation process of FPGAs by building models that provide fast and accurate performance predictions. However, these models suffer from two main limitations: (1) training requires large amounts of data (features extracted from FPGA synthesis and implementation reports), which is cost-inefficient because of the time-consuming FPGA design cycle; (2) a model trained for a specific environment cannot predict for a new, unknown environment. In a cloud system, where getting access to platforms is typically costly, data collection for ML models can significantly increase the total cost-ownership (TCO) of a system. To overcome these limitations, we propose LEAPER, a transfer learning-based approach for FPGA-based systems that adapts an existing ML-based model to a new, unknown environment to provide fast and accurate performance and resource utilization predictions. Experimental results show that our approach delivers, on average, 85% accuracy when we use our transferred model for prediction in a cloud environment with 5-shot learning and reduces design-space exploration time by 10x, from days to only a few hours.
Agile Autotuning of a Transprecision Tensor Accelerator Overlay for TVM Compiler Stack
Apr 20, 2020
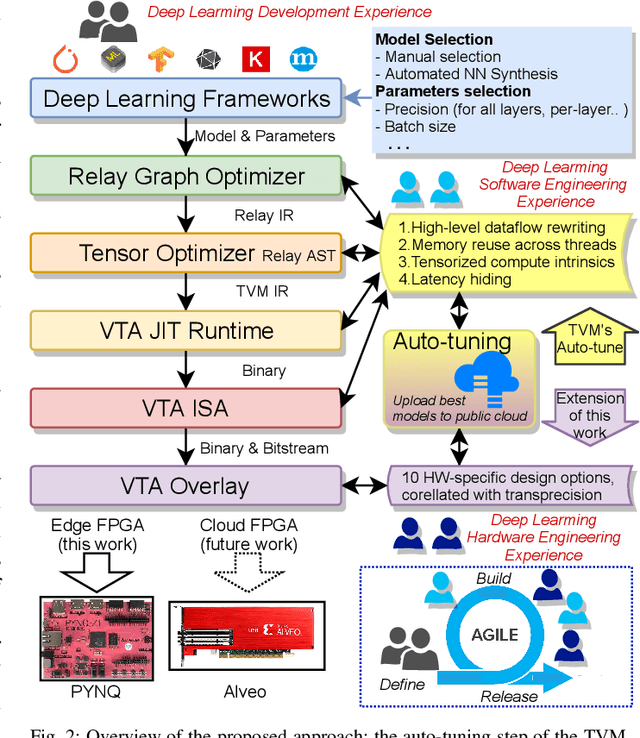


Specialized accelerators for tensor-operations, such as blocked-matrix operations and multi-dimensional convolutions, have been emerged as powerful architecture choices for high-performance Deep-Learning computing. The rapid development of frameworks, models, and precision options challenges the adaptability of such tensor-accelerators since the adaptation to new requirements incurs significant engineering costs. Programmable tensor accelerators offer a promising alternative by allowing reconfiguration of a virtual architecture that overlays on top of the physical FPGA configurable fabric. We propose an overlay ({\tau}-VTA) and an optimization method guided by agile-inspired auto-tuning techniques. We achieve higher performance and faster convergence than state-of-art.