 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwiftRL: Towards Efficient Reinforcement Learning on Real Processing-In-Memory Systems
May 07, 2024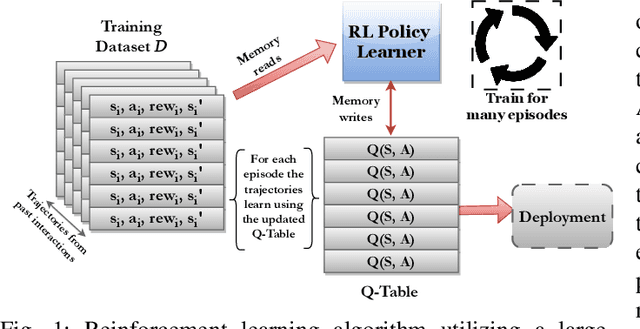
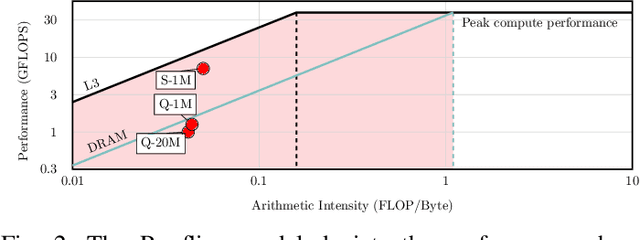
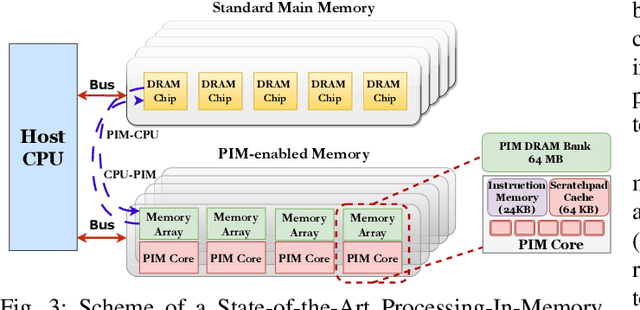
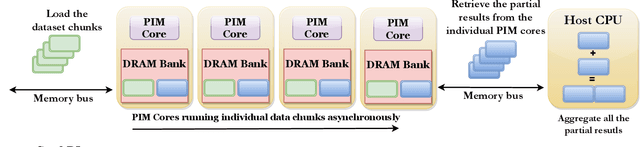
Reinforcement Learning (RL) trains agents to learn optimal behavior by maximizing reward signals from experience datasets. However, RL training often faces memory limitations, leading to execution latencies and prolonged training times. To overcome this, SwiftRL explores Processing-In-Memory (PIM) architectures to accelerate RL workloads. We achieve near-linear performance scaling by implementing RL algorithms like Tabular Q-learning and SARSA on UPMEM PIM systems and optimizing for hardware. Our experiments on OpenAI GYM environments using UPMEM hardware demonstrate superior performance compared to CPU and GPU implementations.
Every Parameter Matters: Ensuring the Convergence of Federated Learning with Dynamic Heterogeneous Models Reduction
Oct 26, 2023Cross-device Federated Learning (FL) faces significant challenges where low-end clients that could potentially make unique contributions are excluded from training large models due to their resource bottlenecks. Recent research efforts have focused on model-heterogeneous FL, by extracting reduced-size models from the global model and applying them to local clients accordingly. Despite the empirical success, general theoretical guarantees of convergence on this method remain an open question. This paper presents a unifying framework for heterogeneous FL algorithms with online model extraction and provides a general convergence analysis for the first time. In particular, we prove that under certain sufficient conditions and for both IID and non-IID data, these algorithms converge to a stationary point of standard FL for general smooth cost functions. Moreover, we introduce the concept of minimum coverage index, together with model reduction noise, which will determine the convergence of heterogeneous federated learning, and therefore we advocate for a holistic approach that considers both factors to enhance the efficiency of heterogeneous federated learning.
MAC-PO: Multi-Agent Experience Replay via Collective Priority Optimization
Feb 28, 2023Experience replay is crucial for off-policy reinforcement learning (RL) methods. By remembering and reusing the experiences from past different policies, experience replay significantly improves the training efficiency and stability of RL algorithms. Many decision-making problems in practice naturally involve multiple agents and require multi-agent reinforcement learning (MARL) under centralized training decentralized execution paradigm. Nevertheless, existing MARL algorithms often adopt standard experience replay where the transitions are uniformly sampled regardless of their importance. Finding prioritized sampling weights that are optimized for MARL experience replay has yet to be explored. To this end, we propose MAC-PO, which formulates optimal prioritized experience replay for multi-agent problems as a regret minimization over the sampling weights of transitions. Such optimization is relaxed and solved using the Lagrangian multiplier approach to obtain the close-form optimal sampling weights. By minimizing the resulting policy regret, we can narrow the gap between the current policy and a nominal optimal policy, thus acquiring an improved prioritization scheme for multi-agent tasks. Our experimental results on Predator-Prey and StarCraft Multi-Agent Challenge environments demonstrate the effectiveness of our method, having a better ability to replay important transitions and outperforming other state-of-the-art baselines.
Exploiting Partial Common Information Microstructure for Multi-Modal Brain Tumor Segmentation
Feb 06, 2023



Learning with multiple modalities is crucial for automated brain tumor segmentation from magnetic resonance imaging data. Explicitly optimizing the common information shared among all modalities (e.g., by maximizing the total correlation) has been shown to achieve better feature representations and thus enhance the segmentation performance. However, existing approaches are oblivious to partial common information shared by subsets of the modalities. In this paper, we show that identifying such partial common information can significantly boost the discriminative power of image segmentation models. In particular, we introduce a novel concept of partial common information mask (PCI-mask) to provide a fine-grained characterization of what partial common information is shared by which subsets of the modalities. By solving a masked correlation maximization and simultaneously learning an optimal PCI-mask, we identify the latent microstructure of partial common information and leverage it in a self-attention module to selectively weight different feature representations in multi-modal data. We implement our proposed framework on the standard U-Net. Our experimental results on the Multi-modal Brain Tumor Segmentation Challenge (BraTS) datasets consistently outperform those of state-of-the-art segmentation baselines, with validation Dice similarity coefficients of 0.920, 0.897, 0.837 for the whole tumor, tumor core, and enhancing tumor on BraTS-2020.
On the Convergence of Heterogeneous Federated Learning with Arbitrary Adaptive Online Model Pruning
Feb 09, 2022


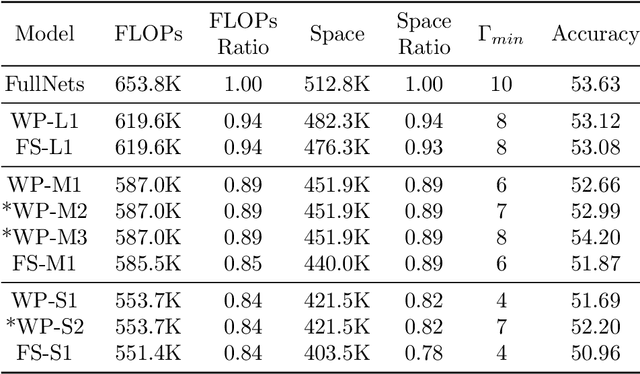
One of the biggest challenges in Federated Learning (FL) is that client devices often have drastically different computation and communication resources for local updates. To this end, recent research efforts have focused on training heterogeneous local models obtained by pruning a shared global model. Despite empirical success, theoretical guarantees on convergence remain an open question. In this paper, we present a unifying framework for heterogeneous FL algorithms with {\em arbitrary} adaptive online model pruning and provide a general convergence analysis. In particular, we prove that under certain sufficient conditions and on both IID and non-IID data, these algorithms converges to a stationary point of standard FL for general smooth cost functions, with a convergence rate of $O(\frac{1}{\sqrt{Q}})$. Moreover, we illuminate two key factors impacting convergence: pruning-induced noise and minimum coverage index, advocating a joint design of local pruning masks for efficient training.
PT-VTON: an Image-Based Virtual Try-On Network with Progressive Pose Attention Transfer
Nov 23, 2021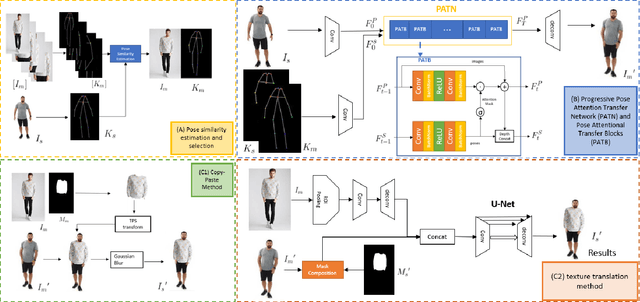



The virtual try-on system has gained great attention due to its potential to give customers a realistic, personalized product presentation in virtualized settings. In this paper, we present PT-VTON, a novel pose-transfer-based framework for cloth transfer that enables virtual try-on with arbitrary poses. PT-VTON can be applied to the fashion industry within minimal modification of existing systems while satisfying the overall visual fashionability and detailed fabric appearance requirements. It enables efficient clothes transferring between model and user images with arbitrary pose and body shape. We implement a prototype of PT-VTON and demonstrate that our system can match or surpass many other approaches when facing a drastic variation of poses by preserving detailed human and fabric characteristic appearances. PT-VTON is shown to outperform alternative approaches both on machine-based quantitative metrics and qualitative results.
Twin-Finder: Integrated Reasoning Engine for Pointer-related Code Clone Detection
Nov 05, 2019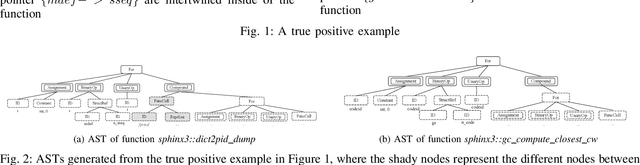



Detecting code clones is crucial in various software engineering tasks. In particular, code clone detection can have significant uses in the context of analyzing and fixing bugs in large scale applications. However, prior works, such as machine learning based clone detection, may cause a considerable amount of false positives. In this paper, we propose Twin-Finder, a novel, closed-loop approach for pointer-related code clone detection that integrates machine learning and symbolic execution techniques to achieve precision. Twin-Finder introduces a clone verification mechanism to formally verify if two clone samples are indeed clones and a feedback loop to automatically generated formal rules to tune machine learning algorithm and further reduce the false positives. Our experimental results show Twin-Finder that can swiftly identify up 9X more code clones comparing to conventional code clone detection approaches. We conduct security analysis for memory safety using real-world applications Links version 2.14 and libreOffice-6.0.0.1. Twin-Finder is able to find 6 unreported bugs in Links version 2.14 and one public patched bug in libreOffice-6.0.0.1.