 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthoGeoLoRA: Geometric Parameter-Efficient Fine-Tuning for Structured Social Science Concept Retrieval on theWeb
Jan 14, 2026Large language models and text encoders increasingly power web-based information systems in the social sciences, including digital libraries, data catalogues, and search interfaces used by researchers, policymakers, and civil society. Full fine-tuning is often computationally and energy intensive, which can be prohibitive for smaller institutions and non-profit organizations in the Web4Good ecosystem. Parameter-Efficient Fine-Tuning (PEFT), especially Low-Rank Adaptation (LoRA), reduces this cost by updating only a small number of parameters. We show that the standard LoRA update $ΔW = BA^\top$ has geometric drawbacks: gauge freedom, scale ambiguity, and a tendency toward rank collapse. We introduce OrthoGeoLoRA, which enforces an SVD-like form $ΔW = BΣA^\top$ by constraining the low-rank factors to be orthogonal (Stiefel manifold). A geometric reparameterization implements this constraint while remaining compatible with standard optimizers such as Adam and existing fine-tuning pipelines. We also propose a benchmark for hierarchical concept retrieval over the European Language Social Science Thesaurus (ELSST), widely used to organize social science resources in digital repositories. Experiments with a multilingual sentence encoder show that OrthoGeoLoRA outperforms standard LoRA and several strong PEFT variants on ranking metrics under the same low-rank budget, offering a more compute- and parameter-efficient path to adapt foundation models in resource-constrained settings.
Conversation Kernels: A Flexible Mechanism to Learn Relevant Context for Online Conversation Understanding
May 26, 2025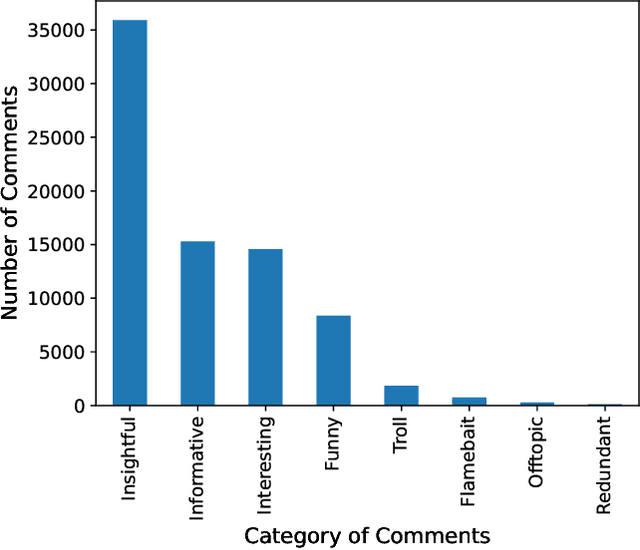
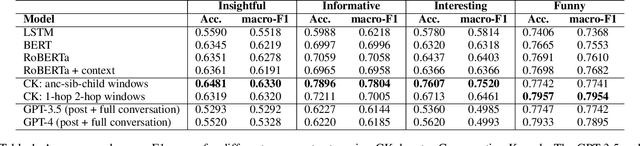
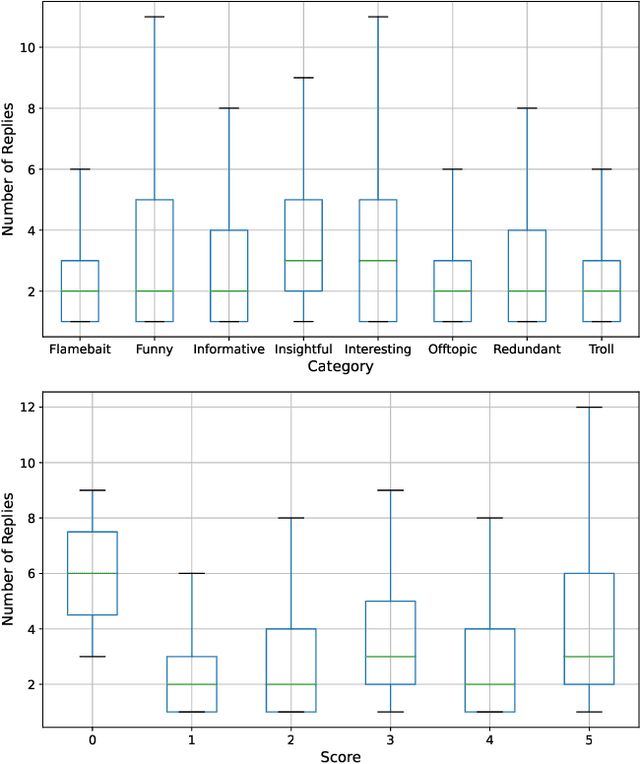

Understanding online conversations has attracted research attention with the growth of social networks and online discussion forums. Content analysis of posts and replies in online conversations is difficult because each individual utterance is usually short and may implicitly refer to other posts within the same conversation. Thus, understanding individual posts requires capturing the conversational context and dependencies between different parts of a conversation tree and then encoding the context dependencies between posts and comments/replies into the language model. To this end, we propose a general-purpose mechanism to discover appropriate conversational context for various aspects about an online post in a conversation, such as whether it is informative, insightful, interesting or funny. Specifically, we design two families of Conversation Kernels, which explore different parts of the neighborhood of a post in the tree representing the conversation and through this, build relevant conversational context that is appropriate for each task being considered. We apply our developed method to conversations crawled from slashdot.org, which allows users to apply highly different labels to posts, such as 'insightful', 'funny', etc., and therefore provides an ideal experimental platform to study whether a framework such as Conversation Kernels is general-purpose and flexible enough to be adapted to disparately different conversation understanding tasks.
Are Information Retrieval Approaches Good at Harmonising Longitudinal Survey Questions in Social Science?
Apr 29, 2025Automated detection of semantically equivalent questions in longitudinal social science surveys is crucial for long-term studies informing empirical research in the social, economic, and health sciences. Retrieving equivalent questions faces dual challenges: inconsistent representation of theoretical constructs (i.e. concept/sub-concept) across studies as well as between question and response options, and the evolution of vocabulary and structure in longitudinal text. To address these challenges, our multi-disciplinary collaboration of computer scientists and survey specialists presents a new information retrieval (IR) task of identifying concept (e.g. Housing, Job, etc.) equivalence across question and response options to harmonise longitudinal population studies. This paper investigates multiple unsupervised approaches on a survey dataset spanning 1946-2020, including probabilistic models, linear probing of language models, and pre-trained neural networks specialised for IR. We show that IR-specialised neural models achieve the highest overall performance with other approaches performing comparably. Additionally, the re-ranking of the probabilistic model's results with neural models only introduces modest improvements of 0.07 at most in F1-score. Qualitative post-hoc evaluation by survey specialists shows that models generally have a low sensitivity to questions with high lexical overlap, particularly in cases where sub-concepts are mismatched. Altogether, our analysis serves to further research on harmonising longitudinal studies in social science.
Making Social Platforms Accessible: Emotion-Aware Speech Generation with Integrated Text Analysis
Oct 24, 2024



Recent studies have outlined the accessibility challenges faced by blind or visually impaired, and less-literate people, in interacting with social networks, in-spite of facilitating technologies such as monotone text-to-speech (TTS) screen readers and audio narration of visual elements such as emojis. Emotional speech generation traditionally relies on human input of the expected emotion together with the text to synthesise, with additional challenges around data simplification (causing information loss) and duration inaccuracy, leading to lack of expressive emotional rendering. In real-life communications, the duration of phonemes can vary since the same sentence might be spoken in a variety of ways depending on the speakers' emotional states or accents (referred to as the one-to-many problem of text to speech generation). As a result, an advanced voice synthesis system is required to account for this unpredictability. We propose an end-to-end context-aware Text-to-Speech (TTS) synthesis system that derives the conveyed emotion from text input and synthesises audio that focuses on emotions and speaker features for natural and expressive speech, integrating advanced natural language processing (NLP) and speech synthesis techniques for real-time applications. Our system also showcases competitive inference time performance when benchmarked against the state-of-the-art TTS models, making it suitable for real-time accessibility applications.
Revealing COVID-19's Social Dynamics: Diachronic Semantic Analysis of Vaccine and Symptom Discourse on Twitter
Oct 10, 2024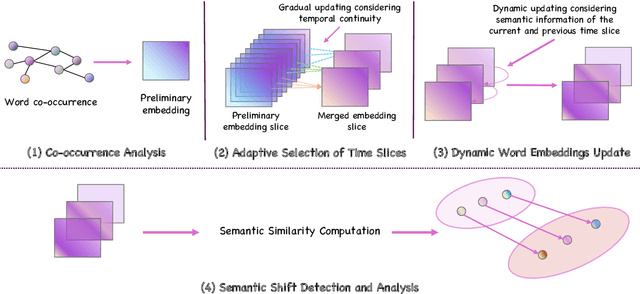
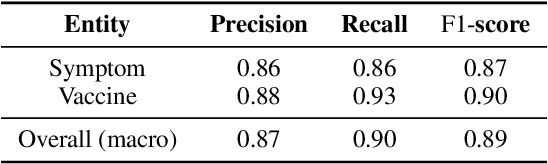

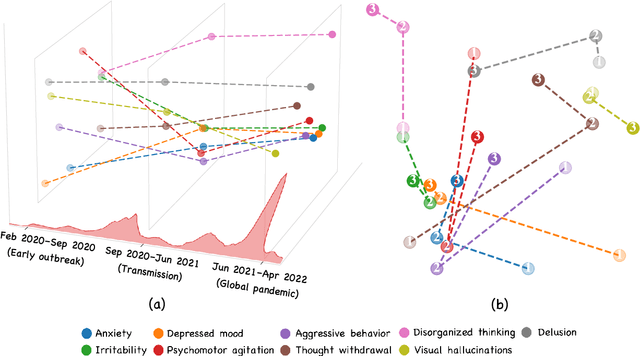
Social media is recognized as an important source for deriving insights into public opinion dynamics and social impacts due to the vast textual data generated daily and the 'unconstrained' behavior of people interacting on these platforms. However, such analyses prove challenging due to the semantic shift phenomenon, where word meanings evolve over time. This paper proposes an unsupervised dynamic word embedding method to capture longitudinal semantic shifts in social media data without predefined anchor words. The method leverages word co-occurrence statistics and dynamic updating to adapt embeddings over time, addressing the challenges of data sparseness, imbalanced distributions, and synergistic semantic effects. Evaluated on a large COVID-19 Twitter dataset, the method reveals semantic evolution patterns of vaccine- and symptom-related entities across different pandemic stages, and their potential correlations with real-world statistics. Our key contributions include the dynamic embedding technique, empirical analysis of COVID-19 semantic shifts, and discussions on enhancing semantic shift modeling for computational social science research. This study enables capturing longitudinal semantic dynamics on social media to understand public discourse and collective phenomena.
DKE-Research at SemEval-2024 Task 2: Incorporating Data Augmentation with Generative Models and Biomedical Knowledge to Enhance Inference Robustness
Apr 14, 2024



Safe and reliable natural language inference is critical for extracting insights from clinical trial reports but poses challenges due to biases in large pre-trained language models. This paper presents a novel data augmentation technique to improve model robustness for biomedical natural language inference in clinical trials. By generating synthetic examples through semantic perturbations and domain-specific vocabulary replacement and adding a new task for numerical and quantitative reasoning, we introduce greater diversity and reduce shortcut learning. Our approach, combined with multi-task learning and the DeBERTa architecture, achieved significant performance gains on the NLI4CT 2024 benchmark compared to the original language models. Ablation studies validate the contribution of each augmentation method in improving robustness. Our best-performing model ranked 12th in terms of faithfulness and 8th in terms of consistency, respectively, out of the 32 participants.
Zero-Shot Medical Information Retrieval via Knowledge Graph Embedding
Oct 31, 2023In the era of the Internet of Things (IoT), the retrieval of relevant medical information has become essential for efficient clinical decision-making. This paper introduces MedFusionRank, a novel approach to zero-shot medical information retrieval (MIR) that combines the strengths of pre-trained language models and statistical methods while addressing their limitations. The proposed approach leverages a pre-trained BERT-style model to extract compact yet informative keywords. These keywords are then enriched with domain knowledge by linking them to conceptual entities within a medical knowledge graph. Experimental evaluations on medical datasets demonstrate MedFusion Rank's superior performance over existing methods, with promising results with a variety of evaluation metrics. MedFusionRank demonstrates efficacy in retrieving relevant information, even from short or single-term queries.