 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDict-BERT: Enhancing Language Model Pre-training with Dictionary
Paper and Code
Oct 13, 2021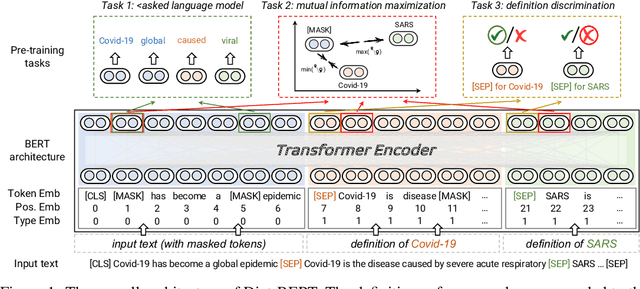



Pre-trained language models (PLMs) aim to learn universal language representations by conducting self-supervised training tasks on large-scale corpora. Since PLMs capture word semantics in different contexts, the quality of word representations highly depends on word frequency, which usually follows a heavy-tailed distributions in the pre-training corpus. Therefore, the embeddings of rare words on the tail are usually poorly optimized. In this work, we focus on enhancing language model pre-training by leveraging definitions of the rare words in dictionaries (e.g., Wiktionary). To incorporate a rare word definition as a part of input, we fetch its definition from the dictionary and append it to the end of the input text sequence. In addition to training with the masked language modeling objective, we propose two novel self-supervised pre-training tasks on word and sentence-level alignment between input text sequence and rare word definitions to enhance language modeling representation with dictionary. We evaluate the proposed Dict-BERT model on the language understanding benchmark GLUE and eight specialized domain benchmark datasets. Extensive experiments demonstrate that Dict-BERT can significantly improve the understanding of rare words and boost model performance on various NLP downstream tasks.