 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized Policy Learning for Continuous State and Action MDPs
Paper and Code
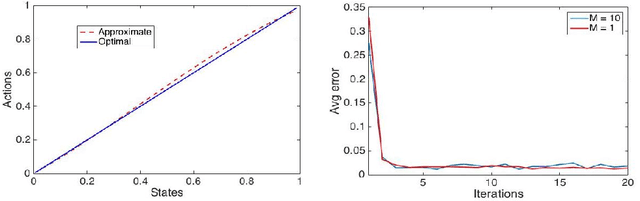

Deep reinforcement learning methods have achieved state-of-the-art results in a variety of challenging, high-dimensional domains ranging from video games to locomotion. The key to success has been the use of deep neural networks used to approximate the policy and value function. Yet, substantial tuning of weights is required for good results. We instead use randomized function approximation. Such networks are not only cheaper than training fully connected networks but also improve the numerical performance. We present \texttt{RANDPOL}, a generalized policy iteration algorithm for MDPs with continuous state and action spaces. Both the policy and value functions are represented with randomized networks. We also give finite time guarantees on the performance of the algorithm. Then we show the numerical performance on challenging environments and compare them with deep neural network based algorithms.