 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffSeeker: Online Reinforcement Learning Is Not All You Need for Deep Research Agents
Jan 26, 2026Deep research agents have shown remarkable potential in handling long-horizon tasks. However, state-of-the-art performance typically relies on online reinforcement learning (RL), which is financially expensive due to extensive API calls. While offline training offers a more efficient alternative, its progress is hindered by the scarcity of high-quality research trajectories. In this paper, we demonstrate that expensive online reinforcement learning is not all you need to build powerful research agents. To bridge this gap, we introduce a fully open-source suite designed for effective offline training. Our core contributions include DeepForge, a ready-to-use task synthesis framework that generates large-scale research queries without heavy preprocessing; and a curated collection of 66k QA pairs, 33k SFT trajectories, and 21k DPO pairs. Leveraging these resources, we train OffSeeker (8B), a model developed entirely offline. Extensive evaluations across six benchmarks show that OffSeeker not only leads among similar-sized agents but also remains competitive with 30B-parameter systems trained via heavy online RL.
AgentMath: Empowering Mathematical Reasoning for Large Language Models via Tool-Augmented Agent
Dec 23, 2025Large Reasoning Models (LRMs) like o3 and DeepSeek-R1 have achieved remarkable progress in natural language reasoning with long chain-of-thought. However, they remain computationally inefficient and struggle with accuracy when solving problems requiring complex mathematical operations. In this work, we present AgentMath, an agent framework that seamlessly integrates language models' reasoning capabilities with code interpreters' computational precision to efficiently tackle complex mathematical problems. Our approach introduces three key innovations: (1) An automated method that converts natural language chain-of-thought into structured tool-augmented trajectories, generating high-quality supervised fine-tuning (SFT) data to alleviate data scarcity; (2) A novel agentic reinforcement learning (RL) paradigm that dynamically interleaves natural language generation with real-time code execution. This enables models to autonomously learn optimal tool-use strategies through multi-round interactive feedback, while fostering emergent capabilities in code refinement and error correction; (3) An efficient training system incorporating innovative techniques, including request-level asynchronous rollout scheduling, agentic partial rollout, and prefix-aware weighted load balancing, achieving 4-5x speedup and making efficient RL training feasible on ultra-long sequences with scenarios with massive tool calls.Extensive evaluations show that AgentMath achieves state-of-the-art performance on challenging mathematical competition benchmarks including AIME24, AIME25, and HMMT25. Specifically, AgentMath-30B-A3B attains 90.6%, 86.4%, and 73.8% accuracy respectively, achieving advanced capabilities.These results validate the effectiveness of our approach and pave the way for building more sophisticated and scalable mathematical reasoning agents.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
WarriorCoder: Learning from Expert Battles to Augment Code Large Language Models
Dec 23, 2024Despite recent progress achieved by code large language models (LLMs), their remarkable abilities are largely dependent on fine-tuning on the high-quality data, posing challenges for data collection and annotation. To address this, current methods often design various data flywheels to gather complex code instructions, enabling models to handle more intricate tasks. However, these approaches typically rely on off-the-shelf datasets and data augmentation from the limited pool of proprietary LLMs (e.g., Claude, GPT4, and so on), which limits the diversity of the constructed data and makes it prone to systemic biases. In this paper, we propose WarriorCoder which learns from expert battles to address these limitations. Specifically, we create an arena for current expert code LLMs, where each model challenges and responds to others' challenges, with evaluations conducted by uninvolved judge models. This competitive framework generates novel training data constructed from scratch, harnessing the strengths of all participants. Experimental results demonstrate that WarriorCoder achieves competitive performance compared to previous methods, even without relying on proprietary LLMs.
Towards a Unified Paradigm: Integrating Recommendation Systems as a New Language in Large Models
Dec 22, 2024



This paper explores the use of Large Language Models (LLMs) for sequential recommendation, which predicts users' future interactions based on their past behavior. We introduce a new concept, "Integrating Recommendation Systems as a New Language in Large Models" (RSLLM), which combines the strengths of traditional recommenders and LLMs. RSLLM uses a unique prompting method that combines ID-based item embeddings from conventional recommendation models with textual item features. It treats users' sequential behaviors as a distinct language and aligns the ID embeddings with the LLM's input space using a projector. We also propose a two-stage LLM fine-tuning framework that refines a pretrained LLM using a combination of two contrastive losses and a language modeling loss. The LLM is first fine-tuned using text-only prompts, followed by target domain fine-tuning with unified prompts. This trains the model to incorporate behavioral knowledge from the traditional sequential recommender into the LLM. Our empirical results validate the effectiveness of our proposed framework.
AgentGen: Enhancing Planning Abilities for Large Language Model based Agent via Environment and Task Generation
Aug 01, 2024Large Language Model (LLM) based agents have garnered significant attention and are becoming increasingly popular. Furthermore, planning ability is a crucial component of an LLM-based agent, involving interaction with the environment and executing actions to complete a planning task, which generally entails achieving a desired goal from an initial state. This paper investigates enhancing the planning abilities of LLMs through instruction tuning, referred to as agent training. Recent studies have demonstrated that utilizing expert-level trajectory for instruction-tuning LLMs effectively enhances their planning capabilities. However, existing work primarily focuses on synthesizing trajectories from manually designed planning tasks and environments. The labor-intensive nature of creating these environments and tasks impedes the generation of sufficiently varied and extensive trajectories. To address this limitation, this paper explores the automated synthesis of diverse environments and a gradual range of planning tasks, from easy to difficult. We introduce a framework, AgentGen, that leverages LLMs first to generate environments and subsequently generate planning tasks conditioned on these environments. Specifically, to improve environmental diversity, we propose using an inspiration corpus composed of various domain-specific text segments as the context for synthesizing environments. Moreover, to increase the difficulty diversity of generated planning tasks, we propose a bidirectional evolution method, Bi-Evol, that evolves planning tasks from easier and harder directions to synthesize a task set with a smoother difficulty curve. The evaluation results derived from AgentBoard show that AgentGen greatly improves LLMs' planning ability, e.g., the AgentGen instruction-tuned Llama-3 8B surpasses GPT-3.5 in overall performance. Moreover, in certain tasks, it even outperforms GPT-4.
Arena Learning: Build Data Flywheel for LLMs Post-training via Simulated Chatbot Arena
Jul 15, 2024
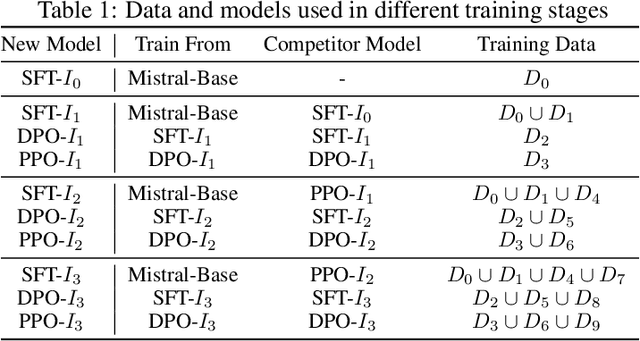


Assessing the effectiveness of large language models (LLMs) presents substantial challenges. The method of conducting human-annotated battles in an online Chatbot Arena is a highly effective evaluative technique. However, this approach is limited by the costs and time required for human annotation. In this paper, we introduce Arena Learning, an innovative offline strategy designed to simulate these arena battles using AI-driven annotations to evaluate battle outcomes, thus facilitating the continuous improvement of the target model through both supervised fine-tuning and reinforcement learning. Arena Learning comprises two key elements. First, it ensures precise evaluations and maintains consistency between offline simulations and online competitions via WizardArena, a pipeline developed to accurately predict the Elo rankings of various models using a meticulously designed offline test set. Our results demonstrate that WizardArena's predictions closely align with those from the online Arena. Second, it involves the continuous improvement of training data based on the battle results and the refined model. We establish a data flywheel to iteratively update the training data by highlighting the weaknesses of the target model based on its battle results, enabling it to learn from the strengths of multiple different models. We apply Arena Learning to train our target model, WizardLM-$\beta$, and demonstrate significant performance enhancements across various metrics. This fully automated training and evaluation pipeline sets the stage for continuous advancements in various LLMs via post-training. Notably, Arena Learning plays a pivotal role in the success of WizardLM-2, and this paper serves both as an exploration of its efficacy and a foundational study for future discussions related to WizardLM-2 and its derivatives.
WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct
Aug 18, 2023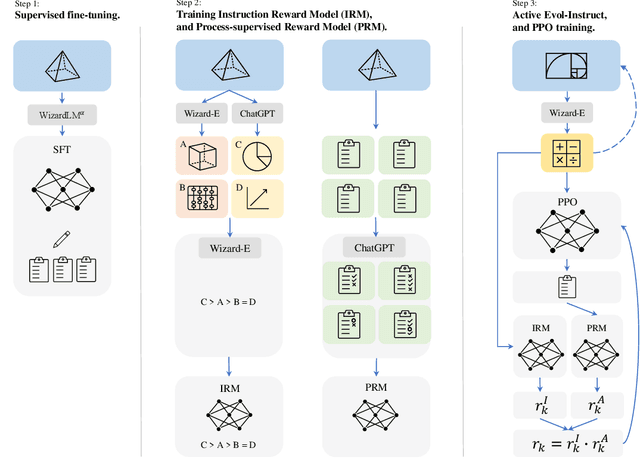
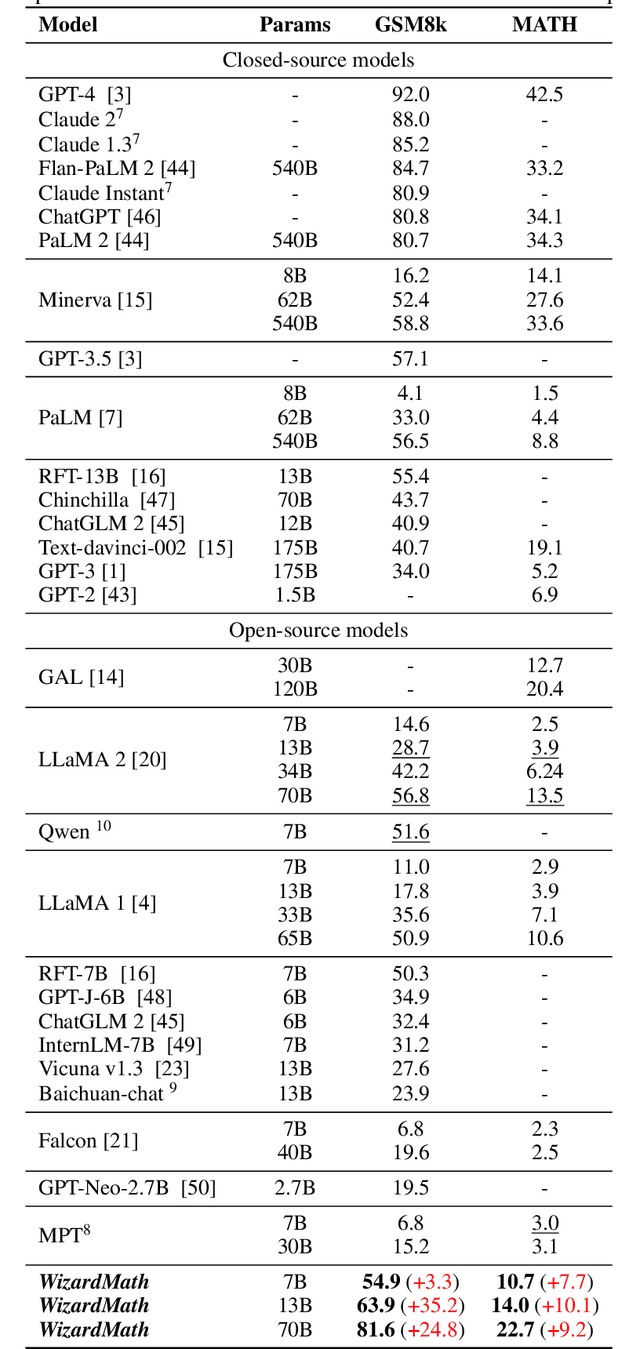
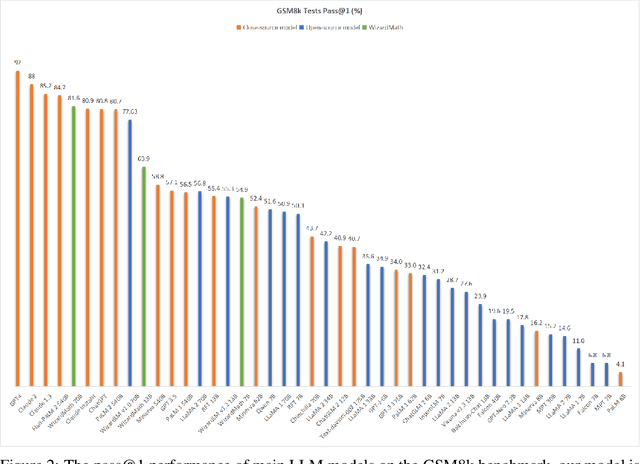

Large language models (LLMs), such as GPT-4, have shown remarkable performance in natural language processing (NLP) tasks, including challenging mathematical reasoning. However, most existing open-source models are only pre-trained on large-scale internet data and without math-related optimization. In this paper, we present WizardMath, which enhances the mathematical reasoning abilities of Llama-2, by applying our proposed Reinforcement Learning from Evol-Instruct Feedback (RLEIF) method to the domain of math. Through extensive experiments on two mathematical reasoning benchmarks, namely GSM8k and MATH, we reveal the extraordinary capabilities of our model. WizardMath surpasses all other open-source LLMs by a substantial margin. Furthermore, our model even outperforms ChatGPT-3.5, Claude Instant-1, PaLM-2 and Minerva on GSM8k, simultaneously surpasses Text-davinci-002, PaLM-1 and GPT-3 on MATH. More details and model weights are public at https://github.com/nlpxucan/WizardLM and https://huggingface.co/WizardLM.
WizardCoder: Empowering Code Large Language Models with Evol-Instruct
Jun 14, 2023Code Large Language Models (Code LLMs), such as StarCoder, have demonstrated exceptional performance in code-related tasks. However, most existing models are solely pre-trained on extensive raw code data without instruction fine-tuning. In this paper, we introduce WizardCoder, which empowers Code LLMs with complex instruction fine-tuning, by adapting the Evol-Instruct method to the domain of code. Through comprehensive experiments on four prominent code generation benchmarks, namely HumanEval, HumanEval+, MBPP, and DS-1000, we unveil the exceptional capabilities of our model. It surpasses all other open-source Code LLMs by a substantial margin. Moreover, our model even outperforms the largest closed LLMs, Anthropic's Claude and Google's Bard, on HumanEval and HumanEval+. Our code, model weights, and data are public at https://github.com/nlpxucan/WizardLM
Self-Supervised Multi-Modal Sequential Recommendation
Apr 26, 2023


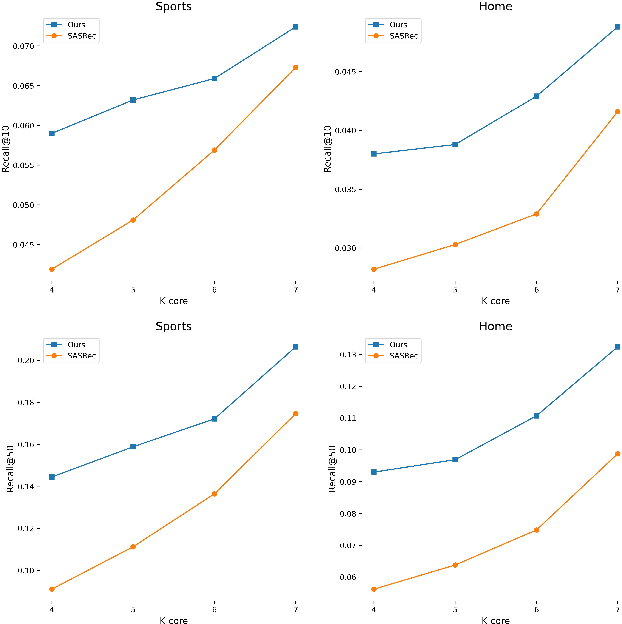
With the increasing development of e-commerce and online services, personalized recommendation systems have become crucial for enhancing user satisfaction and driving business revenue. Traditional sequential recommendation methods that rely on explicit item IDs encounter challenges in handling item cold start and domain transfer problems. Recent approaches have attempted to use modal features associated with items as a replacement for item IDs, enabling the transfer of learned knowledge across different datasets. However, these methods typically calculate the correlation between the model's output and item embeddings, which may suffer from inconsistencies between high-level feature vectors and low-level feature embeddings, thereby hindering further model learning. To address this issue, we propose a dual-tower retrieval architecture for sequence recommendation. In this architecture, the predicted embedding from the user encoder is used to retrieve the generated embedding from the item encoder, thereby alleviating the issue of inconsistent feature levels. Moreover, in order to further improve the retrieval performance of the model, we also propose a self-supervised multi-modal pretraining method inspired by the consistency property of contrastive learning. This pretraining method enables the model to align various feature combinations of items, thereby effectively generalizing to diverse datasets with different item features. We evaluate the proposed method on five publicly available datasets and conduct extensive experiments. The results demonstrate significant performance improvement of our method.