 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Multi-Modal Sequential Recommendation
Paper and Code



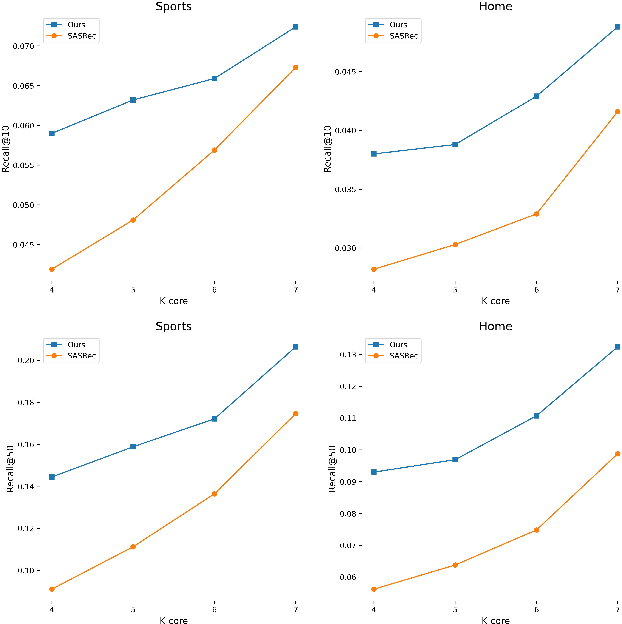
With the increasing development of e-commerce and online services, personalized recommendation systems have become crucial for enhancing user satisfaction and driving business revenue. Traditional sequential recommendation methods that rely on explicit item IDs encounter challenges in handling item cold start and domain transfer problems. Recent approaches have attempted to use modal features associated with items as a replacement for item IDs, enabling the transfer of learned knowledge across different datasets. However, these methods typically calculate the correlation between the model's output and item embeddings, which may suffer from inconsistencies between high-level feature vectors and low-level feature embeddings, thereby hindering further model learning. To address this issue, we propose a dual-tower retrieval architecture for sequence recommendation. In this architecture, the predicted embedding from the user encoder is used to retrieve the generated embedding from the item encoder, thereby alleviating the issue of inconsistent feature levels. Moreover, in order to further improve the retrieval performance of the model, we also propose a self-supervised multi-modal pretraining method inspired by the consistency property of contrastive learning. This pretraining method enables the model to align various feature combinations of items, thereby effectively generalizing to diverse datasets with different item features. We evaluate the proposed method on five publicly available datasets and conduct extensive experiments. The results demonstrate significant performance improvement of our method.