 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Unified Paradigm: Integrating Recommendation Systems as a New Language in Large Models
Dec 22, 2024



This paper explores the use of Large Language Models (LLMs) for sequential recommendation, which predicts users' future interactions based on their past behavior. We introduce a new concept, "Integrating Recommendation Systems as a New Language in Large Models" (RSLLM), which combines the strengths of traditional recommenders and LLMs. RSLLM uses a unique prompting method that combines ID-based item embeddings from conventional recommendation models with textual item features. It treats users' sequential behaviors as a distinct language and aligns the ID embeddings with the LLM's input space using a projector. We also propose a two-stage LLM fine-tuning framework that refines a pretrained LLM using a combination of two contrastive losses and a language modeling loss. The LLM is first fine-tuned using text-only prompts, followed by target domain fine-tuning with unified prompts. This trains the model to incorporate behavioral knowledge from the traditional sequential recommender into the LLM. Our empirical results validate the effectiveness of our proposed framework.
TStarBot-X: An Open-Sourced and Comprehensive Study for Efficient League Training in StarCraft II Full Game
Nov 27, 2020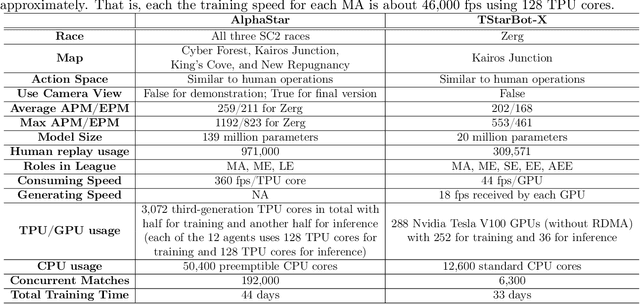
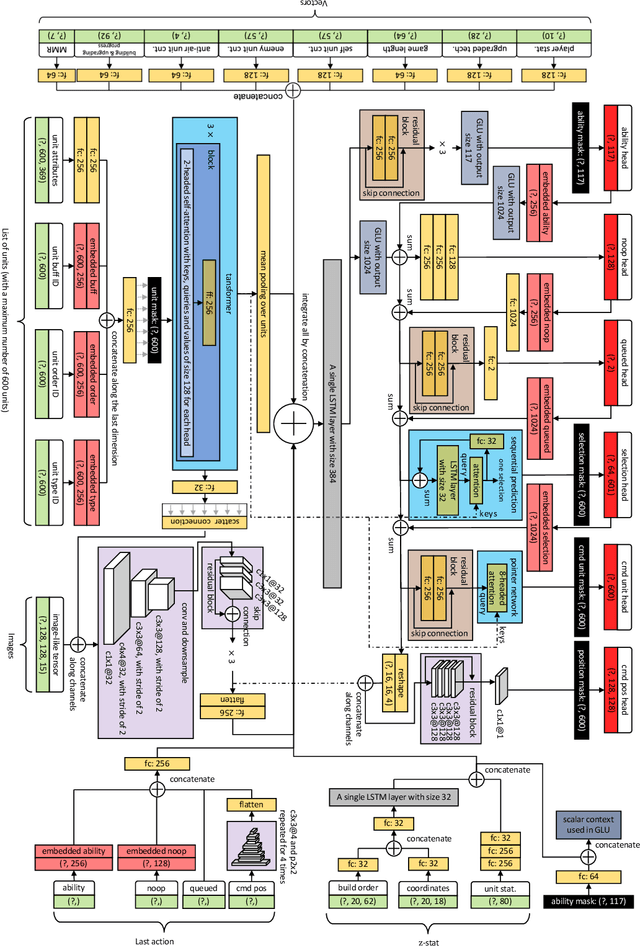
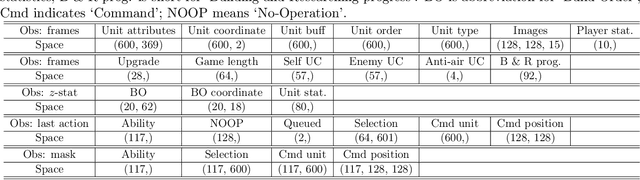

StarCraft, one of the most difficult esport games with long-standing history of professional tournaments, has attracted generations of players and fans, and also, intense attentions in artificial intelligence research. Recently, Google's DeepMind announced AlphaStar, a grandmaster level AI in StarCraft II. In this paper, we introduce a new AI agent, named TStarBot-X, that is trained under limited computation resources and can play competitively with expert human players. TStarBot-X takes advantage of important techniques introduced in AlphaStar, and also benefits from substantial innovations including new league training methods, novel multi-agent roles, rule-guided policy search, lightweight neural network architecture, and importance sampling in imitation learning, etc. We show that with limited computation resources, a faithful reimplementation of AlphaStar can not succeed and the proposed techniques are necessary to ensure TStarBot-X's competitive performance. We reveal all technical details that are complementary to those mentioned in AlphaStar, showing the most sensitive parts in league training, reinforcement learning and imitation learning that affect the performance of the agents. Most importantly, this is an open-sourced study that all codes and resources (including the trained model parameters) are publicly accessible via https://github.com/tencent-ailab/tleague_projpage We expect this study could be beneficial for both academic and industrial future research in solving complex problems like StarCraft, and also, might provide a sparring partner for all StarCraft II players and other AI agents.
Mastering Complex Control in MOBA Games with Deep Reinforcement Learning
Jan 03, 2020
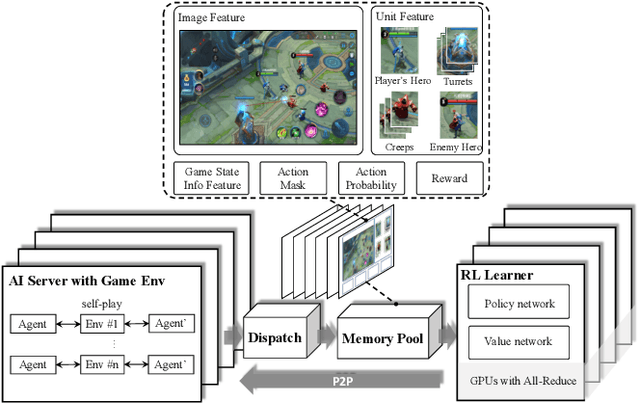
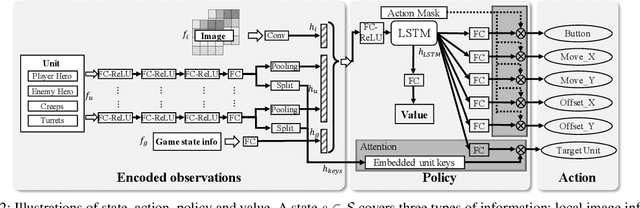

We study the reinforcement learning problem of complex action control in the Multi-player Online Battle Arena (MOBA) 1v1 games. This problem involves far more complicated state and action spaces than those of traditional 1v1 games, such as Go and Atari series, which makes it very difficult to search any policies with human-level performance. In this paper, we present a deep reinforcement learning framework to tackle this problem from the perspectives of both system and algorithm. Our system is of low coupling and high scalability, which enables efficient explorations at large scale. Our algorithm includes several novel strategies, including control dependency decoupling, action mask, target attention, and dual-clip PPO, with which our proposed actor-critic network can be effectively trained in our system. Tested on the MOBA game Honor of Kings, the trained AI agents can defeat top professional human players in full 1v1 games.