 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Crowd Counting With Self-Supervised Learning
Sep 26, 2025Multi-view counting (MVC) methods have attracted significant research attention and stimulated remarkable progress in recent years. Despite their success, most MVC methods have focused on improving performance by following the fully supervised learning (FSL) paradigm, which often requires large amounts of annotated data. In this work, we propose SSLCounter, a novel self-supervised learning (SSL) framework for MVC that leverages neural volumetric rendering to alleviate the reliance on large-scale annotated datasets. SSLCounter learns an implicit representation w.r.t. the scene, enabling the reconstruction of continuous geometry shape and the complex, view-dependent appearance of their 2D projections via differential neural rendering. Owing to its inherent flexibility, the key idea of our method can be seamlessly integrated into exsiting frameworks. Notably, extensive experiments demonstrate that SSLCounter not only demonstrates state-of-the-art performances but also delivers competitive performance with only using 70% proportion of training data, showcasing its superior data efficiency across multiple MVC benchmarks.
NTIRE 2023 Quality Assessment of Video Enhancement Challenge
Jul 19, 2023



This paper reports on the NTIRE 2023 Quality Assessment of Video Enhancement Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2023. This challenge is to address a major challenge in the field of video processing, namely, video quality assessment (VQA) for enhanced videos. The challenge uses the VQA Dataset for Perceptual Video Enhancement (VDPVE), which has a total of 1211 enhanced videos, including 600 videos with color, brightness, and contrast enhancements, 310 videos with deblurring, and 301 deshaked videos. The challenge has a total of 167 registered participants. 61 participating teams submitted their prediction results during the development phase, with a total of 3168 submissions. A total of 176 submissions were submitted by 37 participating teams during the final testing phase. Finally, 19 participating teams submitted their models and fact sheets, and detailed the methods they used. Some methods have achieved better results than baseline methods, and the winning methods have demonstrated superior prediction performance.
Synthetic Data Supervised Salient Object Detection
Oct 25, 2022
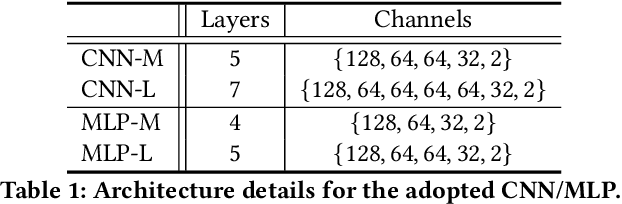
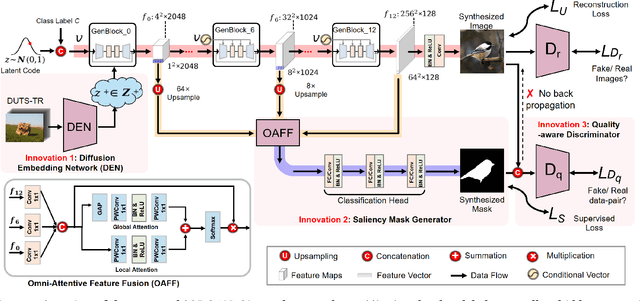
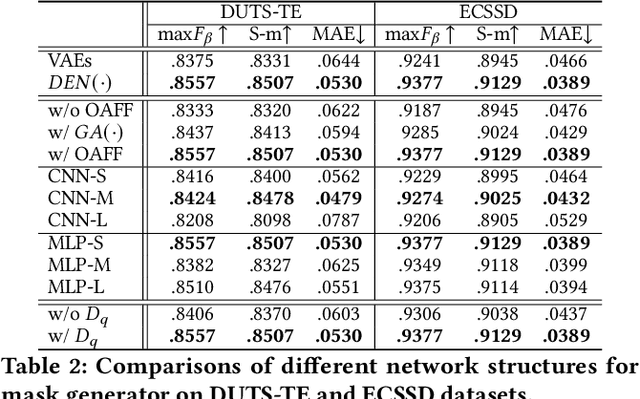
Although deep salient object detection (SOD) has achieved remarkable progress, deep SOD models are extremely data-hungry, requiring large-scale pixel-wise annotations to deliver such promising results. In this paper, we propose a novel yet effective method for SOD, coined SODGAN, which can generate infinite high-quality image-mask pairs requiring only a few labeled data, and these synthesized pairs can replace the human-labeled DUTS-TR to train any off-the-shelf SOD model. Its contribution is three-fold. 1) Our proposed diffusion embedding network can address the manifold mismatch and is tractable for the latent code generation, better matching with the ImageNet latent space. 2) For the first time, our proposed few-shot saliency mask generator can synthesize infinite accurate image synchronized saliency masks with a few labeled data. 3) Our proposed quality-aware discriminator can select highquality synthesized image-mask pairs from noisy synthetic data pool, improving the quality of synthetic data. For the first time, our SODGAN tackles SOD with synthetic data directly generated from the generative model, which opens up a new research paradigm for SOD. Extensive experimental results show that the saliency model trained on synthetic data can achieve $98.4\%$ F-measure of the saliency model trained on the DUTS-TR. Moreover, our approach achieves a new SOTA performance in semi/weakly-supervised methods, and even outperforms several fully-supervised SOTA methods. Code is available at https://github.com/wuzhenyubuaa/SODGAN
* 9 pages, 8 figures
Towards Playing Full MOBA Games with Deep Reinforcement Learning
Dec 31, 2020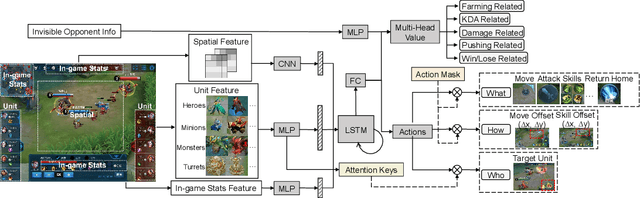
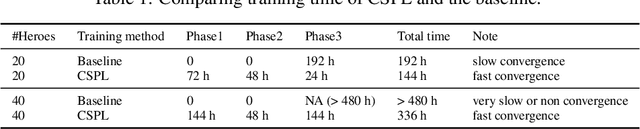
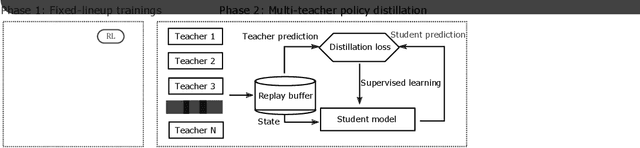

MOBA games, e.g., Honor of Kings, League of Legends, and Dota 2, pose grand challenges to AI systems such as multi-agent, enormous state-action space, complex action control, etc. Developing AI for playing MOBA games has raised much attention accordingly. However, existing work falls short in handling the raw game complexity caused by the explosion of agent combinations, i.e., lineups, when expanding the hero pool in case that OpenAI's Dota AI limits the play to a pool of only 17 heroes. As a result, full MOBA games without restrictions are far from being mastered by any existing AI system. In this paper, we propose a MOBA AI learning paradigm that methodologically enables playing full MOBA games with deep reinforcement learning. Specifically, we develop a combination of novel and existing learning techniques, including curriculum self-play learning, policy distillation, off-policy adaption, multi-head value estimation, and Monte-Carlo tree-search, in training and playing a large pool of heroes, meanwhile addressing the scalability issue skillfully. Tested on Honor of Kings, a popular MOBA game, we show how to build superhuman AI agents that can defeat top esports players. The superiority of our AI is demonstrated by the first large-scale performance test of MOBA AI agent in the literature.
TStarBot-X: An Open-Sourced and Comprehensive Study for Efficient League Training in StarCraft II Full Game
Nov 27, 2020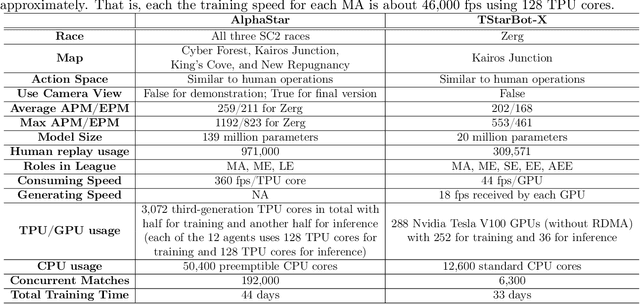
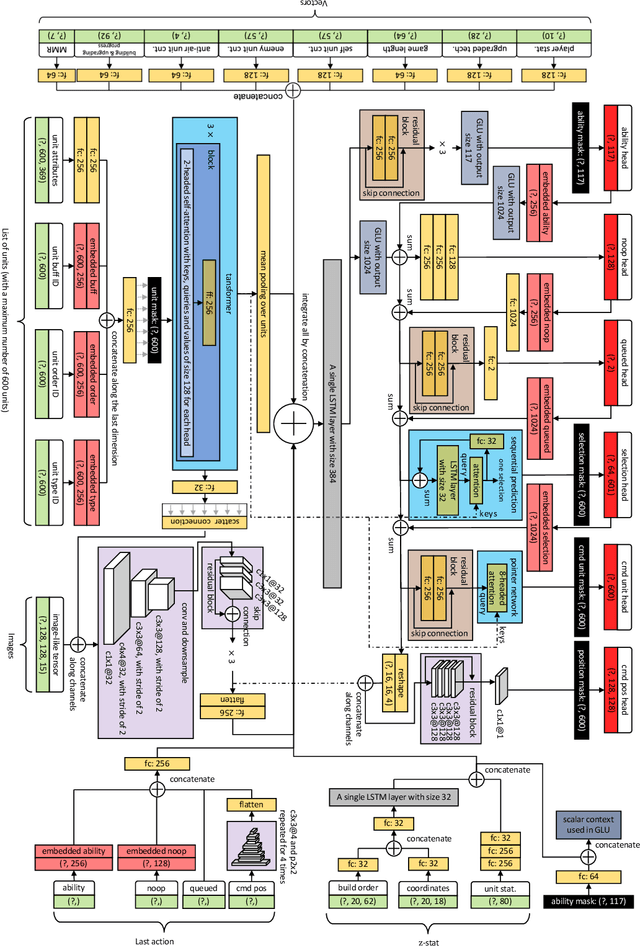
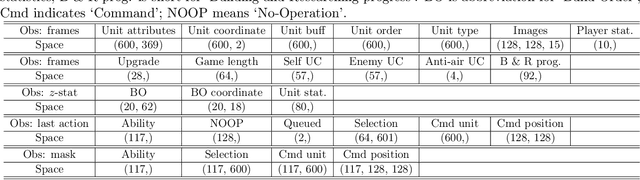

StarCraft, one of the most difficult esport games with long-standing history of professional tournaments, has attracted generations of players and fans, and also, intense attentions in artificial intelligence research. Recently, Google's DeepMind announced AlphaStar, a grandmaster level AI in StarCraft II. In this paper, we introduce a new AI agent, named TStarBot-X, that is trained under limited computation resources and can play competitively with expert human players. TStarBot-X takes advantage of important techniques introduced in AlphaStar, and also benefits from substantial innovations including new league training methods, novel multi-agent roles, rule-guided policy search, lightweight neural network architecture, and importance sampling in imitation learning, etc. We show that with limited computation resources, a faithful reimplementation of AlphaStar can not succeed and the proposed techniques are necessary to ensure TStarBot-X's competitive performance. We reveal all technical details that are complementary to those mentioned in AlphaStar, showing the most sensitive parts in league training, reinforcement learning and imitation learning that affect the performance of the agents. Most importantly, this is an open-sourced study that all codes and resources (including the trained model parameters) are publicly accessible via https://github.com/tencent-ailab/tleague_projpage We expect this study could be beneficial for both academic and industrial future research in solving complex problems like StarCraft, and also, might provide a sparring partner for all StarCraft II players and other AI agents.
Supervised Learning Achieves Human-Level Performance in MOBA Games: A Case Study of Honor of Kings
Nov 25, 2020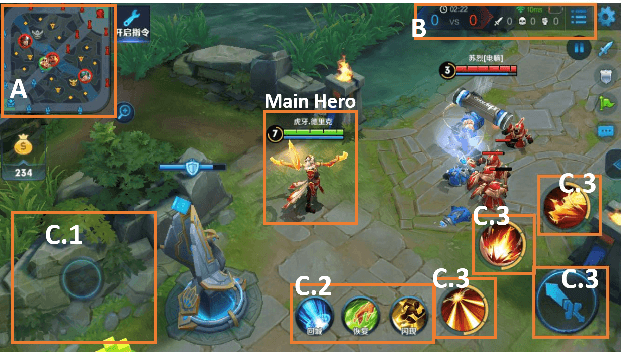
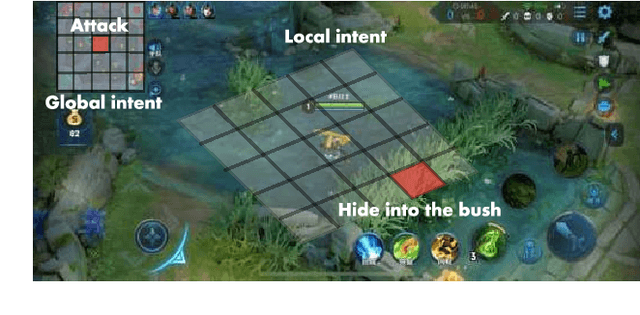
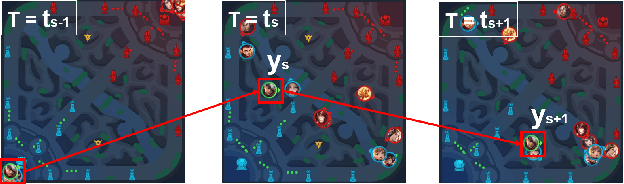
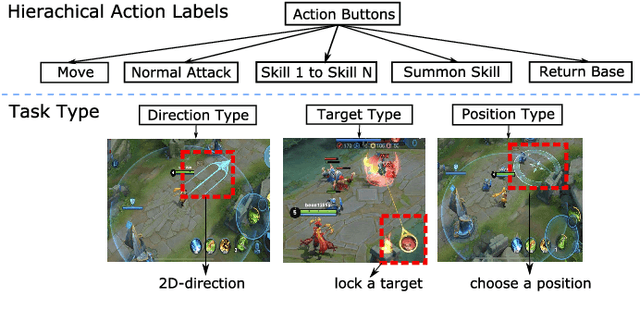
We present JueWu-SL, the first supervised-learning-based artificial intelligence (AI) program that achieves human-level performance in playing multiplayer online battle arena (MOBA) games. Unlike prior attempts, we integrate the macro-strategy and the micromanagement of MOBA-game-playing into neural networks in a supervised and end-to-end manner. Tested on Honor of Kings, the most popular MOBA at present, our AI performs competitively at the level of High King players in standard 5v5 games.
Mastering Complex Control in MOBA Games with Deep Reinforcement Learning
Jan 03, 2020
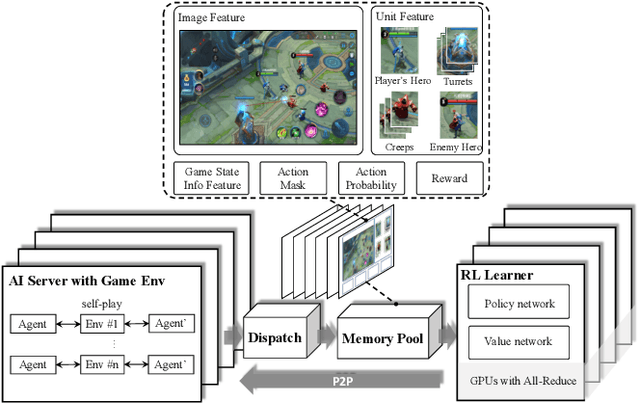
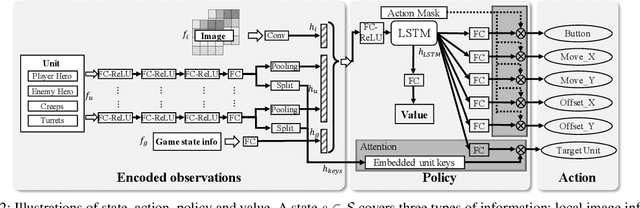

We study the reinforcement learning problem of complex action control in the Multi-player Online Battle Arena (MOBA) 1v1 games. This problem involves far more complicated state and action spaces than those of traditional 1v1 games, such as Go and Atari series, which makes it very difficult to search any policies with human-level performance. In this paper, we present a deep reinforcement learning framework to tackle this problem from the perspectives of both system and algorithm. Our system is of low coupling and high scalability, which enables efficient explorations at large scale. Our algorithm includes several novel strategies, including control dependency decoupling, action mask, target attention, and dual-clip PPO, with which our proposed actor-critic network can be effectively trained in our system. Tested on the MOBA game Honor of Kings, the trained AI agents can defeat top professional human players in full 1v1 games.