 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArena Learning: Build Data Flywheel for LLMs Post-training via Simulated Chatbot Arena
Paper and Code
Jul 15, 2024
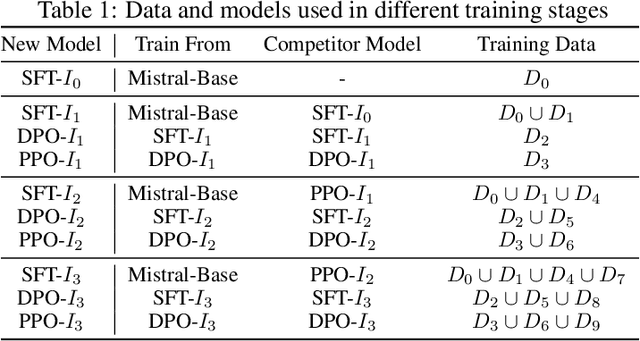


Assessing the effectiveness of large language models (LLMs) presents substantial challenges. The method of conducting human-annotated battles in an online Chatbot Arena is a highly effective evaluative technique. However, this approach is limited by the costs and time required for human annotation. In this paper, we introduce Arena Learning, an innovative offline strategy designed to simulate these arena battles using AI-driven annotations to evaluate battle outcomes, thus facilitating the continuous improvement of the target model through both supervised fine-tuning and reinforcement learning. Arena Learning comprises two key elements. First, it ensures precise evaluations and maintains consistency between offline simulations and online competitions via WizardArena, a pipeline developed to accurately predict the Elo rankings of various models using a meticulously designed offline test set. Our results demonstrate that WizardArena's predictions closely align with those from the online Arena. Second, it involves the continuous improvement of training data based on the battle results and the refined model. We establish a data flywheel to iteratively update the training data by highlighting the weaknesses of the target model based on its battle results, enabling it to learn from the strengths of multiple different models. We apply Arena Learning to train our target model, WizardLM-$\beta$, and demonstrate significant performance enhancements across various metrics. This fully automated training and evaluation pipeline sets the stage for continuous advancements in various LLMs via post-training. Notably, Arena Learning plays a pivotal role in the success of WizardLM-2, and this paper serves both as an exploration of its efficacy and a foundational study for future discussions related to WizardLM-2 and its derivatives.